Meet MindGPT: A Non-Invasive Neural Decoder that Interprets Perceived Visual Stimuli into Natural Languages from fMRI Signals
To communicate with others, humans can only use a limited amount of words to explain what they see in the outside world. This adaptable cognitive ability shows that the semantic information communicated through language is intricately interwoven with different forms of sensory input, particularly for vision. According to neuroscientific investigations, amodal semantic representations are shared across visual and linguistic experiences. For example, the word “cat” generates conceptual information comparable to a cat’s mental image. However, the semantic relationships between conceptual categories and the smooth transition between V&L modalities have only sometimes been quantified or realized using computational models.
Recent research on neural decoders showed that visual content can be recreated from representations of the visual cortex captured via functional magnetic resonance imaging. However, the blurriness and semantic meaninglessness or mismatch of the rebuilt pictures persisted. On the other hand, the neuroscience community has provided strong evidence to back the claim that the VC of the brain can access semantic ideas in both V&L forms. The results compel us to develop new “mind reading” equipment to translate what you perceive vocally. Such an effort has considerable scientific value in illuminating cross-modal semantic integration mechanisms and may offer useful information for augmentative or restorative brain-computer interfaces.
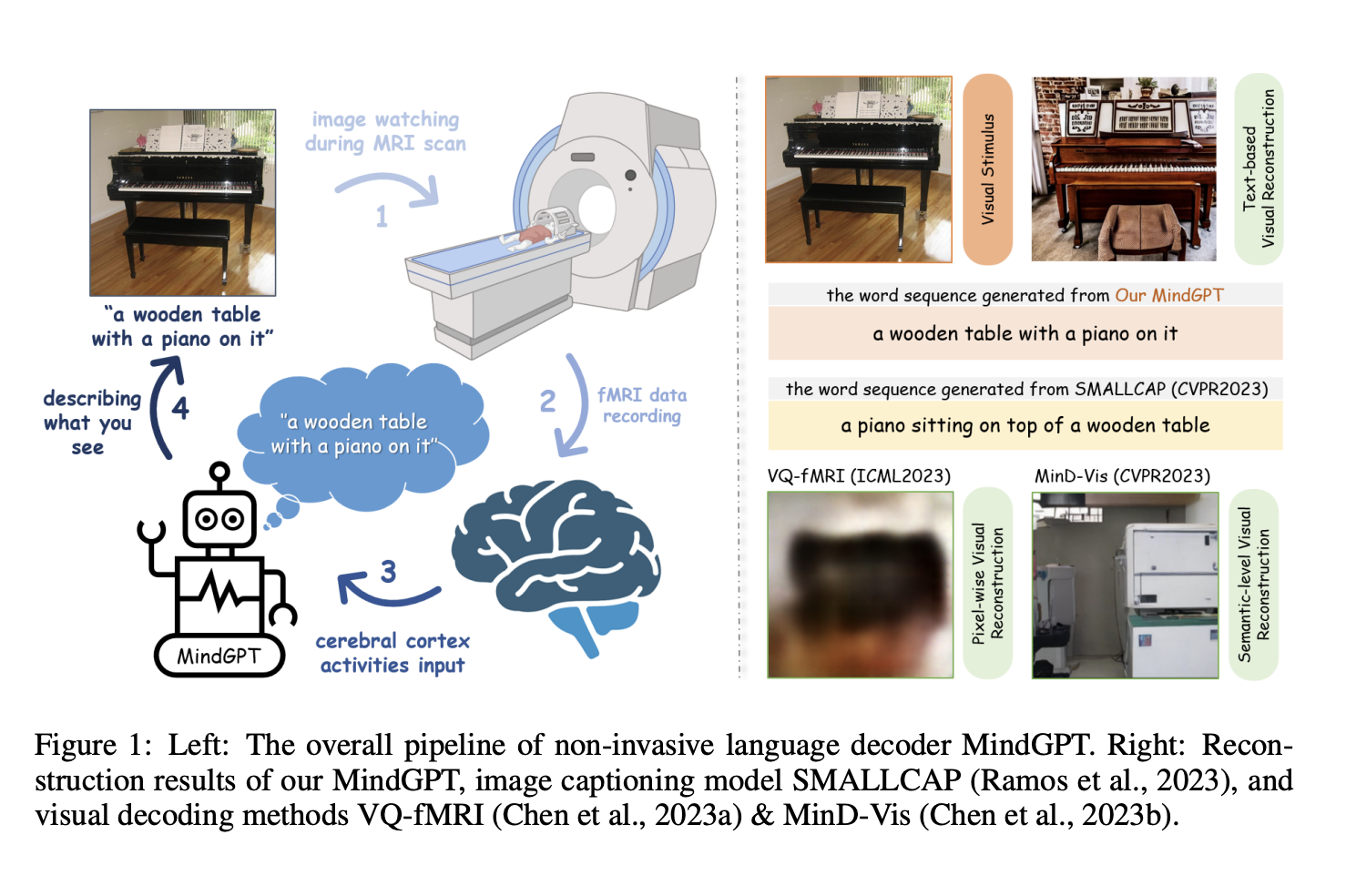
The authors from Zhejiang University introduce MindGPT, a non-invasive neural language decoder that converts the blood-oxygen-level-dependent patterns produced by static visual stimuli into well-formed word sequences, as seen in Fig. 1 Left. To their knowledge, Tang et al. first attempted to create a non-invasive neural decoder for perceived speech reconstruction that can even recover the meaning of silent films for the non-invasive language decoder. However, because fMRI has a poor temporal resolution, much fMRI data must be gathered to predict the fine-grained semantic significance between the candidate words and the induced brain responses.
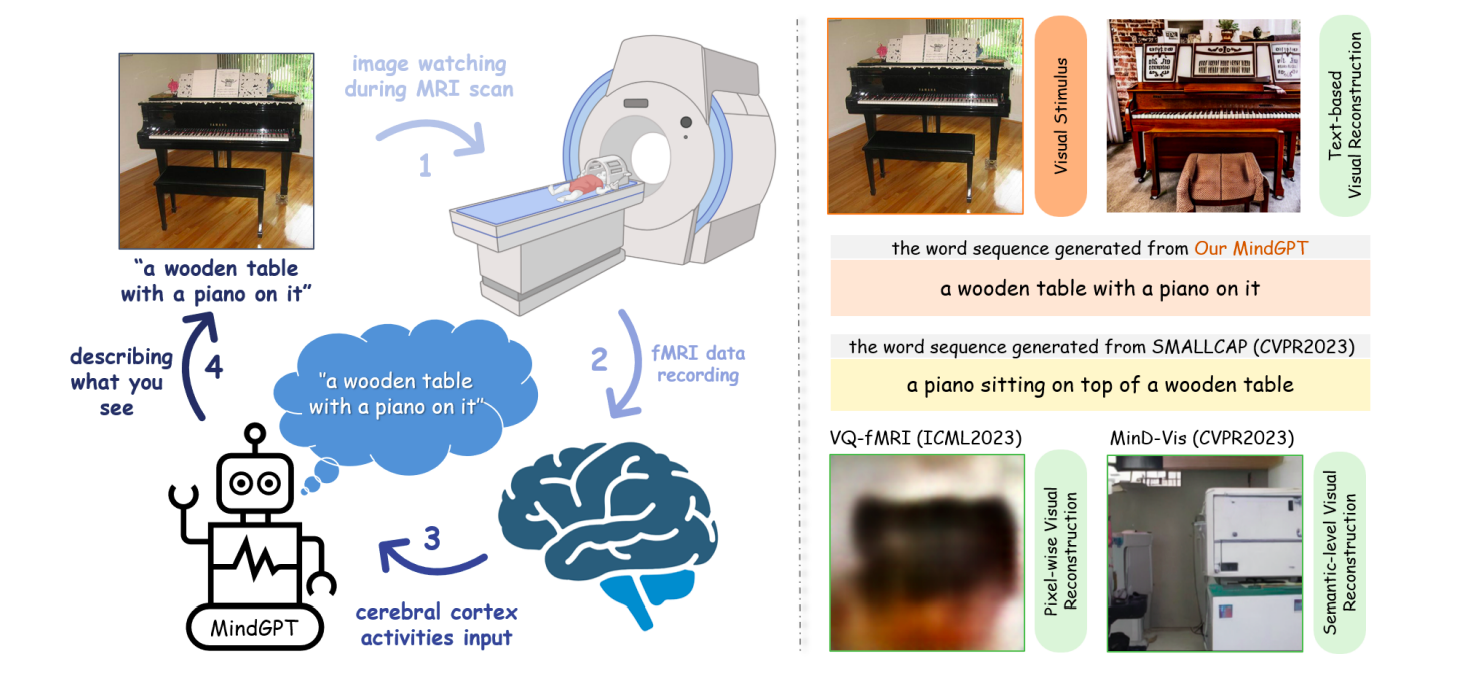
Figure 1: Left: The MindGPT non-intrusive language decoder’s overall pipeline. Right: The outcomes of our MindGPT reconstruction, the SMALLCAP image captioning model, and the VQ-fMRI and MinD-Vis visual decoding approaches.
Instead, this research focuses on whether and to what degree amodal language maps are semantically labeled by static visual sensory experiences, such as a single image. Their MindGPT is built to satisfy two important requirements: (i) it must be able to extract visual semantic representations from brain activity, and (ii) it must include a method for converting learned VSRs into properly constructed word sequences. They first decided to use a big language model, GPT-2, as their text generator. This model has been pre-trained on a dataset of millions of websites called WebText, and it allows us to limit sentence patterns to resemble well-formed natural English.
Then, to close the meaning gap between brain-visual linguistic representations end-to-end, they adopt a straightforward yet effective CLIP-guided fMRI encoder with cross-attention layers. This neural decoding formulation has a very low number of learnable parameters, making it both lightweight and efficient. They have shown in this work that the MindGPT may serve as a link between the brain’s VC and machine for reliable V&L semantic transformations. Their technique has learned generalizable brain semantic representations and a thorough comprehension of B & V & L modalities since the language it produces accurately captures the visual semantics of the observed inputs.
In addition, they discovered that even with very little fMRI picture training data, the well-trained MindGPT appears to emerge with the capacity to record visual cues of stimulus images, which makes it easier for us to investigate how visual features contribute to language semantics. They also noticed, with the aid of a visualization tool, that the latent brain representations taught by MindGPT had beneficial locality-sensitive characteristics in both low-level visual aspects and high-level semantic ideas, consistent with certain findings from the field of neuroscience. Overall, their MindGPT revealed that, in contrast to previous work, it is possible to deduce the semantic relationships between V&L representations from their brain’s VC without considering the temporal resolution of fMRI.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.