Unlocking AI Transparency: How Anthropic’s Feature Grouping Enhances Neural Network Interpretability
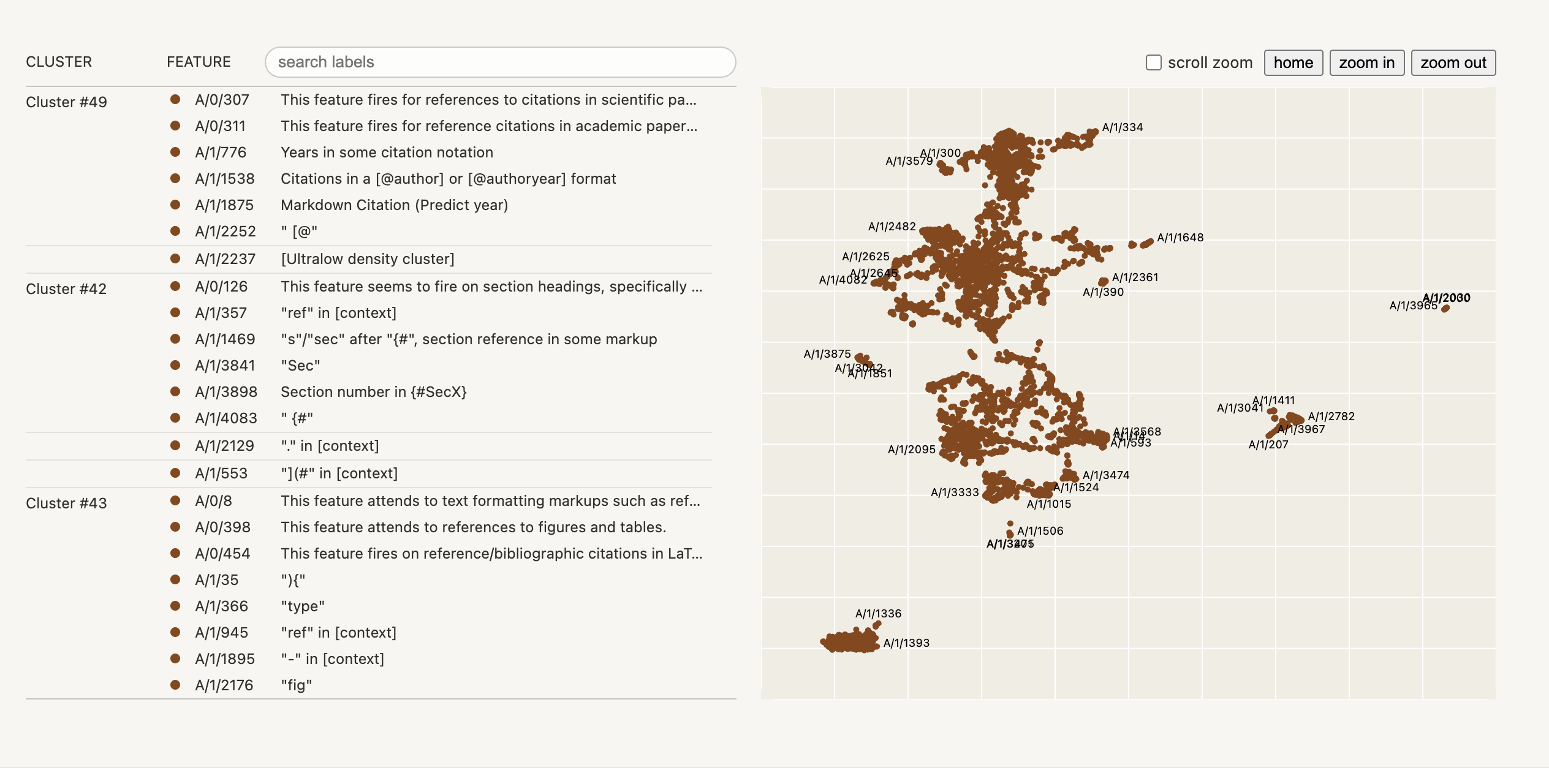
In a recent paper, “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning,” researchers have addressed the challenge of understanding complex neural networks, specifically language models, which are increasingly being used in various applications. The problem they sought to tackle was the lack of interpretability at the level of individual neurons within these models, which makes it challenging to comprehend their behavior fully.
The existing methods and frameworks for interpreting neural networks were discussed, highlighting the limitations associated with analyzing individual neurons due to their polysemantic nature. Neurons often respond to mixtures of seemingly unrelated inputs, making it difficult to reason about the overall network’s behavior by focusing on individual components.
The research team proposed a novel approach to address this issue. They introduced a framework that leverages sparse autoencoders, a weak dictionary learning algorithm, to generate interpretable features from trained neural network models. This framework aims to identify more monosemantic units within the network, which are easier to understand and analyze than individual neurons.
The paper provides an in-depth explanation of the proposed method, detailing how sparse autoencoders are applied to decompose a one-layer transformer model with a 512-neuron MLP layer into interpretable features. The researchers conducted extensive analyses and experiments, training the model on a vast dataset to validate the effectiveness of their approach.
The results of their work were presented in several sections of the paper:
1. Problem Setup: The paper outlined the motivation for the research and described the neural network models and sparse autoencoders used in their study.
2. Detailed Investigations of Individual Features: The researchers offered evidence that the features they identified were functionally specific causal units distinct from neurons. This section served as an existence proof for their approach.
3. Global Analysis: The paper argued that the typical features were interpretable and explained a significant portion of the MLP layer, thus demonstrating the practical utility of their method.
4. Phenomenology: This section describes various properties of the features, such as feature-splitting, universality, and how they could form complex systems resembling “finite state automata.”
The researchers also provided comprehensive visualizations of the features, enhancing the understandability of their findings.
In conclusion, the paper revealed that sparse autoencoders can successfully extract interpretable features from neural network models, making them more comprehensible than individual neurons. This breakthrough can enable the monitoring and steering of model behavior, enhancing safety and reliability, particularly in the context of large language models. The research team expressed their intention to further scale this approach to more complex models, emphasizing that the primary obstacle to interpreting such models is now more of an engineering challenge than a scientific one.
Check out the Research Article and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.