Enhancing Reasoning in Large Language Models: Check Out the Hypotheses-to-Theories (HtT) Framework for Accurate and Transferable Rule-Based Learning
In the realm of reasoning tasks, large language models (LLMs) have displayed remarkable performance when provided with examples and intermediate steps. Nevertheless, approaches that depend on implicit knowledge within an LLM can sometimes produce erroneous answers when the implicit knowledge is incorrect or inconsistent with the task at hand.
To address this issue, a team of researchers from Google, Mila – Québec AI Insitute, Université de Montréal, HEC Montréal, University of Alberta, and CIFAR AI Chair introduce the Hypotheses-to-Theories (HtT) framework that focuses on acquiring a rule library for LLM-based reasoning. HtT comprises two key stages: an induction stage and a deduction stage. In the induction stage, an LLM is initially tasked with generating and validating rules based on a set of training examples.
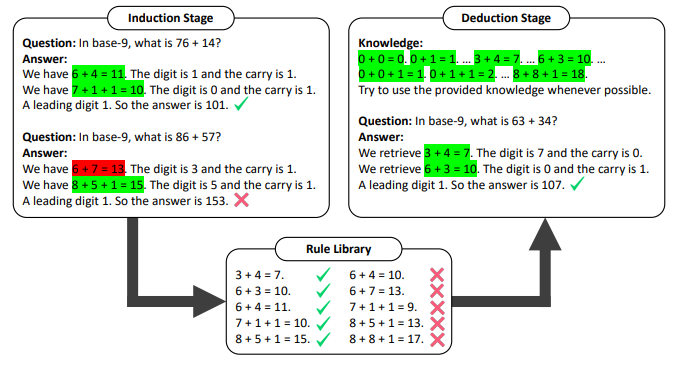
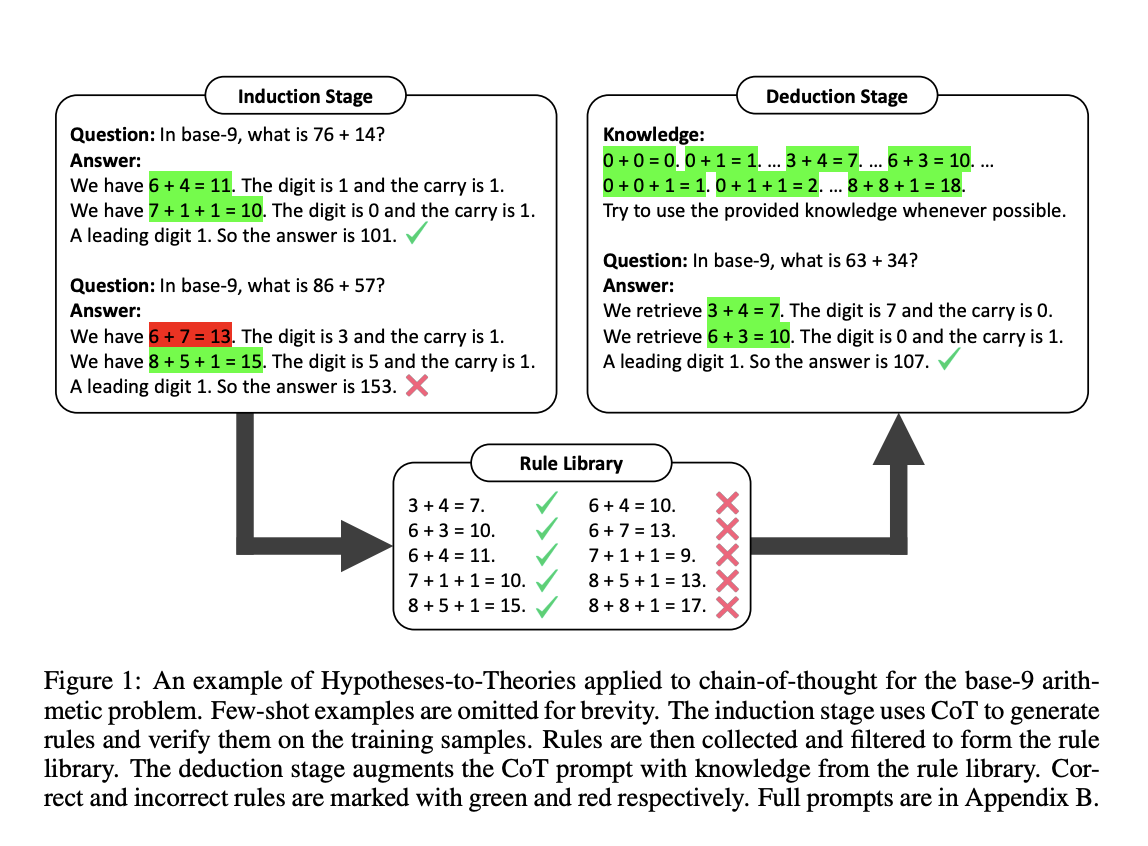
The above image demonstrates the application of Hypotheses-to-Theories to the chain-of-thought method for solving base-9 arithmetic problems is exemplified here. To maintain conciseness, a few-shot examples have been omitted. In the induction stage, the Chain of Thought (CoT) technique is utilized to generate rules and validate them using training samples.
Subsequently, the rules produced are gathered and refined to construct a rule library. In the deduction stage, the CoT prompt is enhanced with knowledge derived from the rule library. Correct rules are indicated with green markers, while incorrect ones are marked in red. Rules that frequently lead to correct answers are accumulated to establish a rule library. In the deduction stage, the LLM is subsequently prompted to utilize the acquired rule library for reasoning in order to answer test questions.
In their evaluation of HtT, the researchers integrate it as an enhancement to pre-existing few-shot prompting techniques, such as chain-of-thought and least-to-most prompting. Performance is assessed on two challenging multi-step reasoning problems that have proven to be problematic for current few-shot prompting approaches.
Experimental results on both numerical reasoning and relational reasoning problems reveal that HtT enhances existing prompting methods, achieving an increase in accuracy ranging from 11% to 27%. Furthermore, the acquired rules can be effectively transferred to different models and various forms of the same problem. The introduced method paves the way for a novel approach to acquiring textual knowledge using LLMs. It is anticipated that HtT will enable a range of applications and inspire further research in the field of LLMs.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.