Researchers from UC Berkeley Propose RingAttention: A Memory-Efficient Artificial Intelligence Approach to Reduce the Memory Requirements of Transformers
A type of deep learning model architecture is called Transformers in the context of many state-of-the-art AI models. They have revolutionized the field of artificial intelligence, particularly in natural language processing and various other tasks in machine learning. It is based on a self-attention mechanism where the model weighs the importance of different parts of the input sequence when making predictions. They consist of an encoder and a decoder to process the inputs.
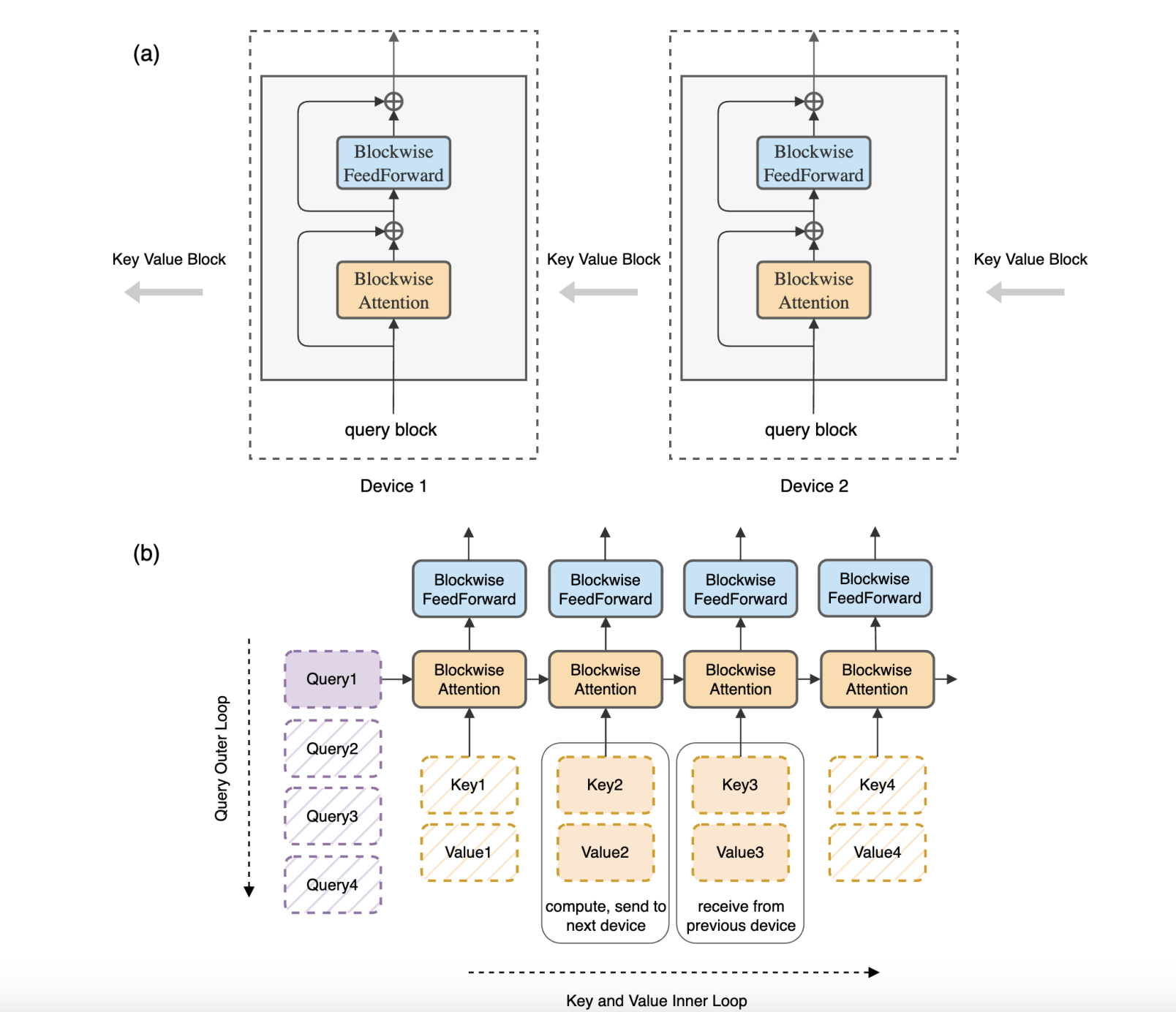
However, scaling up the context length of Transformers takes a lot of work. It is due to the inherited self-attention. Self-attention has memory cost quadratic in the input sequence length, which makes it challenging to scale to the longer input sequences. Researchers at UC Berkley developed a method called Ring Attention to tackle this based on a simple observation. They observed that when self-attention and feedforward network computations are performed blockwise, the sequences can be distributed across multiple devices and easily analyzed.
They distribute the outer loop of computing blockwise attention among hosts, each device managing its respective input block. For the inner loop, they compute blockwise attention and feedforward operations specific to its designated input block for all devices. Their host devices form a conceptual ring and send a copy of its key-value blocks being used for blockwise computation to the next device in the ring. They also simultaneously receive key-value blocks from the previous one.
The block computations take longer than block transfers. The team overlapped these processes, resulting in no added overhead compared to standard transformers. By doing so, each device requires only memory proportional to the block size, independent of the original input sequence length. This effectively eliminates the memory constraints imposed by individual devices.
Their experiments show that Ring Attention can reduce the memory requirements of Transformers by enabling them to train more than 500 times longer sequences than prior memory efficient state-of-the-arts. This method also allows training sequences that exceed 100 million in length without making approximations to attention. As Ring Attention eliminates the memory constraints imposed by individual devices, one can also achieve near-infinite context sizes. However, one would require many number of devices as sequence length is proportional to the number of devices.
The research only involves an evaluation of the effectiveness of the method without the large-scale training models. As the scale context length depends on the number of devices, the model’s efficiency depends on the optimization; they have only worked on the low-level operations required for achieving optimal computer performance. The researchers say that they would like to work on both maximum sequence length and maximum computer performance in the future. The possibility of near-infinite context introduces many exciting opportunities, such as large video-audio-language models, learning from extended feedback and trial-and-errors, understanding and generating codebase, and adapting AI models to understand scientific data such as gene sequences.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.