Meet MatFormer: A Universal Nested Transformer Architecture for Flexible Model Deployment Across Platforms
Transformer models find applications in various applications, ranging from powerful multi-accelerator clusters to individual mobile devices. The varied requirements for inference in these settings make developers train fundamental models like PaLM 2, Llama, and ViTs in different sizes. However, the higher costs associated with training lead to a restricted set of supported model sizes.
Large foundational models are used in different situations, such as giving quick responses on mobile phones or handling batches on multi-cluster GPUs for large-scale web applications. Each model provides a selection of independently trained models in different sizes to accommodate various circumstances. To accommodate a wide range of applications, these model sizes are typically grouped on a logarithmic scale in a roughly linear fashion.
Consequently, a group of researchers from Google Research, the University of Texas at Austin, the University of Washington, and Harvard University have introduced MatFormer—a Transformer architecture explicitly crafted for adaptability, as outlined in their latest paper, which is titled MatFormer: Nested Transformer for Elastic Inference. MatFormer makes it easier to build an integrated model that can generate numerous smaller submodels without extra training.
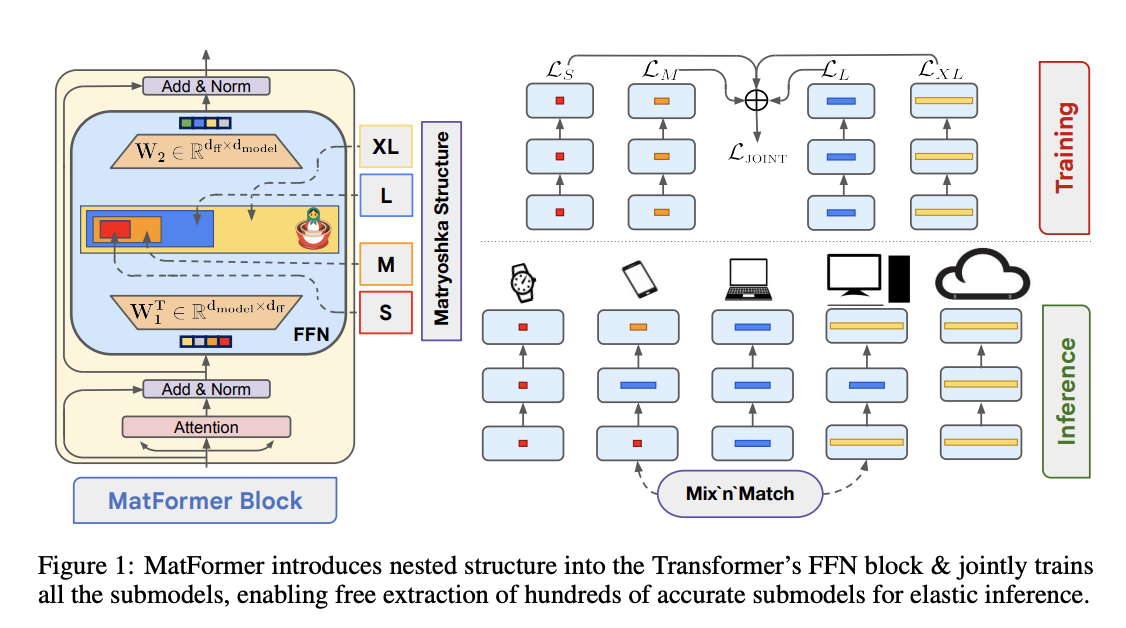
They have incorporated a nested sub-structure within the standard Transformer and jointly optimized all the granularities to produce a single, universal elastic model.
The researchers emphasized that they have produced many accurate submodels without acquiring additional training costs by deliberately mixing various levels of information in various layers of a universal MatFormer model. Each Feed Forward Network (FFN) block in the MatFormer architecture is optimized with a collection of smaller, nested FFN blocks. Each Feed Forward Network (FFN) block in the MatFormer architecture is optimized with a collection of smaller, nested FFN blocks. Through this training approach, they combined and adjusted the complexity of the model across different layers.
The nested structure is implemented on the hidden representations of the Feed Forward Network (FFN) block, amplifying the model’s capabilities by placing the attention heads in order of significance. A substructure within the attention heads is created from the most to the least. Compared to independently training equivalent Transformer-based submodels, training is accelerated by 15% since the more significant heads are distributed among a larger number of submodels. Additionally, this method aligns with the specifically optimized submodel curve and permits the extraction of several smaller submodels while maintaining accuracy.
The researchers found that they could produce a sizable number of accurate smaller models without further optimization by choosing different levels of detail for each MatFormer layer.
The team studied the effectiveness across a range of model types (decoders and encoders), modalities (language and vision), and scales (up to 2.6 billion parameters). The researchers emphasized that comparing these smaller models to their independently trained counterparts reveals comparable validation loss and one-shot downstream performance. Also, MatFormer exhibits robust generalization and works well as vision encoders (MatViT) and decoder-only language models (MatLM). In terms of accuracy and dependability, it scales similarly to the traditional Transformer.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.