Researchers from the University of Amsterdam and Qualcomm AI Presents VeRA: A Novel Finetuning AI Method that Reduces the Number of Trainable Parameters by 10x Compared to LoRA
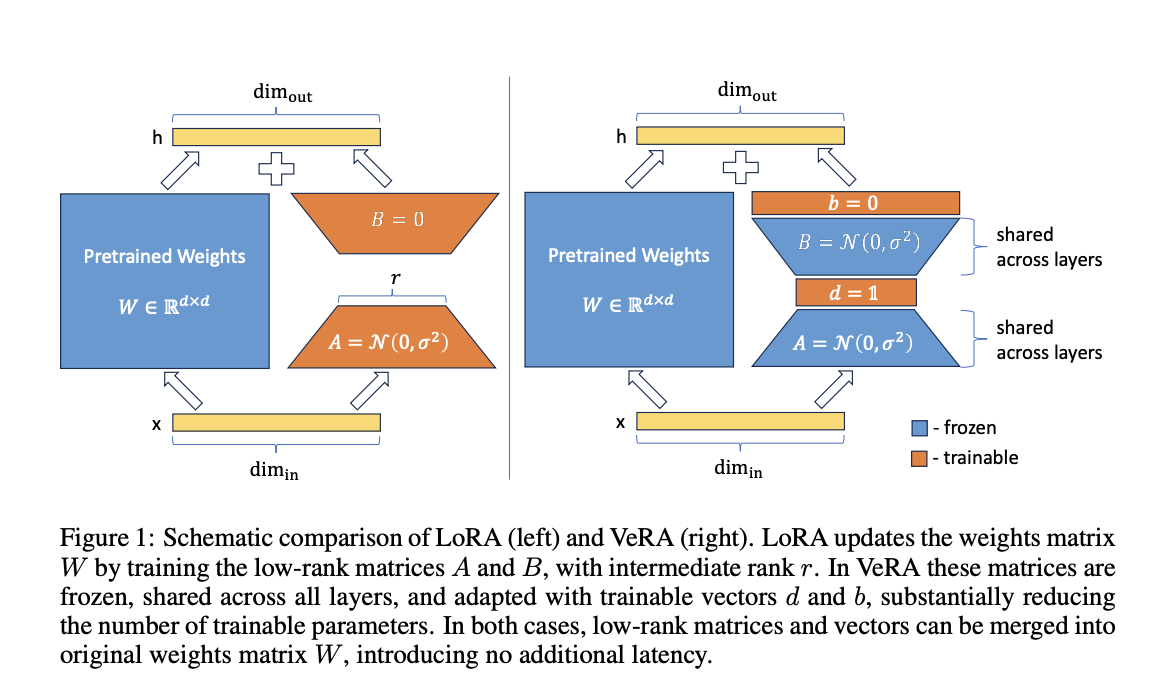
With the ever-expanding scope of natural language processing applications, there has been a growing demand for models that can effectively comprehend and act upon specific instructions with minimal computational complexity and memory requirements. This research highlights the limitations of existing methods and presents a novel approach known as VeRA, which aims to optimize instruction-tuning processes significantly.
Language models often need help with their memory and computational demands, making them less efficient for real-world applications. To address this issue, the researchers introduce VeRA, a novel method that enables the Llama2 7B model to follow instructions effectively using only 1.4 million trainable parameters. This marks a remarkable advancement compared to the previously employed LoRA method, which necessitated a significantly larger parameter count of 159.9 million with a rank of 64, as proposed by Dettmers et al. The substantial reduction in parameters while maintaining performance levels demonstrates the efficacy and promise of the VeRA approach.
The VeRA method’s success can be attributed to its comprehensive fine-tuning strategy, primarily focusing on all linear layers, excluding the top one. Additionally, the utilization of quantization techniques for single-GPU training and the utilization of the Alpaca dataset’s cleaned version has been instrumental in showcasing VeRA’s capabilities. The research team conducted training on a subset of 10,000 samples from the Alpaca dataset, preceded by a comprehensive learning rate sweep, to ensure optimal performance. This meticulous approach to data selection and training methodology underscores the robustness and reliability of the research findings.

In the evaluation phase, the research team employed an approach similar to that of Chiang et al., generating model responses to a predefined set of 80 questions and evaluating these responses using GPT-4. The results, presented in Table 4, highlight the superior performance of the VeRA method, as evidenced by higher overall scores compared to the conventional LoRA approach. This significant achievement underscores the effectiveness of the VeRA approach in achieving enhanced instruction-following capabilities while maintaining optimal efficiency.
The impact of the VeRA method extends beyond its immediate applications, signaling a paradigm shift in instruction tuning and language model optimization. By significantly reducing the number of trainable parameters, VeRA has effectively addressed a critical bottleneck in applying language models, paving the way for more efficient and accessible AI services. This breakthrough holds immense potential for various industries and sectors that rely on AI-driven solutions, offering a practical and efficient approach to instruction tuning for various applications.
In conclusion, the emergence of the VeRA method represents a significant milestone in the evolution of language models and instruction-tuning methodologies. Its success is a testament to the possibilities of achieving optimal performance with minimal computational complexity and memory requirements. As the demand for efficient and practical AI solutions continues to grow, the VeRA method is a testament to the ongoing advancements in AI research and its potential to transform various industries and sectors. The research team’s findings mark a significant step forward in the quest for more accessible and streamlined AI solutions, setting the stage for future innovations and developments in natural language processing and instruction-tuning techniques.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.