MIT Researchers Introduce a New Training-Free and Game-Theoretic AI Procedure for Language Model Decoding
A few tasks requiring the creation or verification of factual assertions—such as question answering, fact-checking, and even the generation of unconditional text—are relatively successfully handled by current language models (LMs). However, growing evidence shows that LMs become more prone to producing erroneous but often repeated comments as size increases. They are far from being completely dependable. The fact that LMs have several affordances for resolving factual generation tasks further complicates issues.
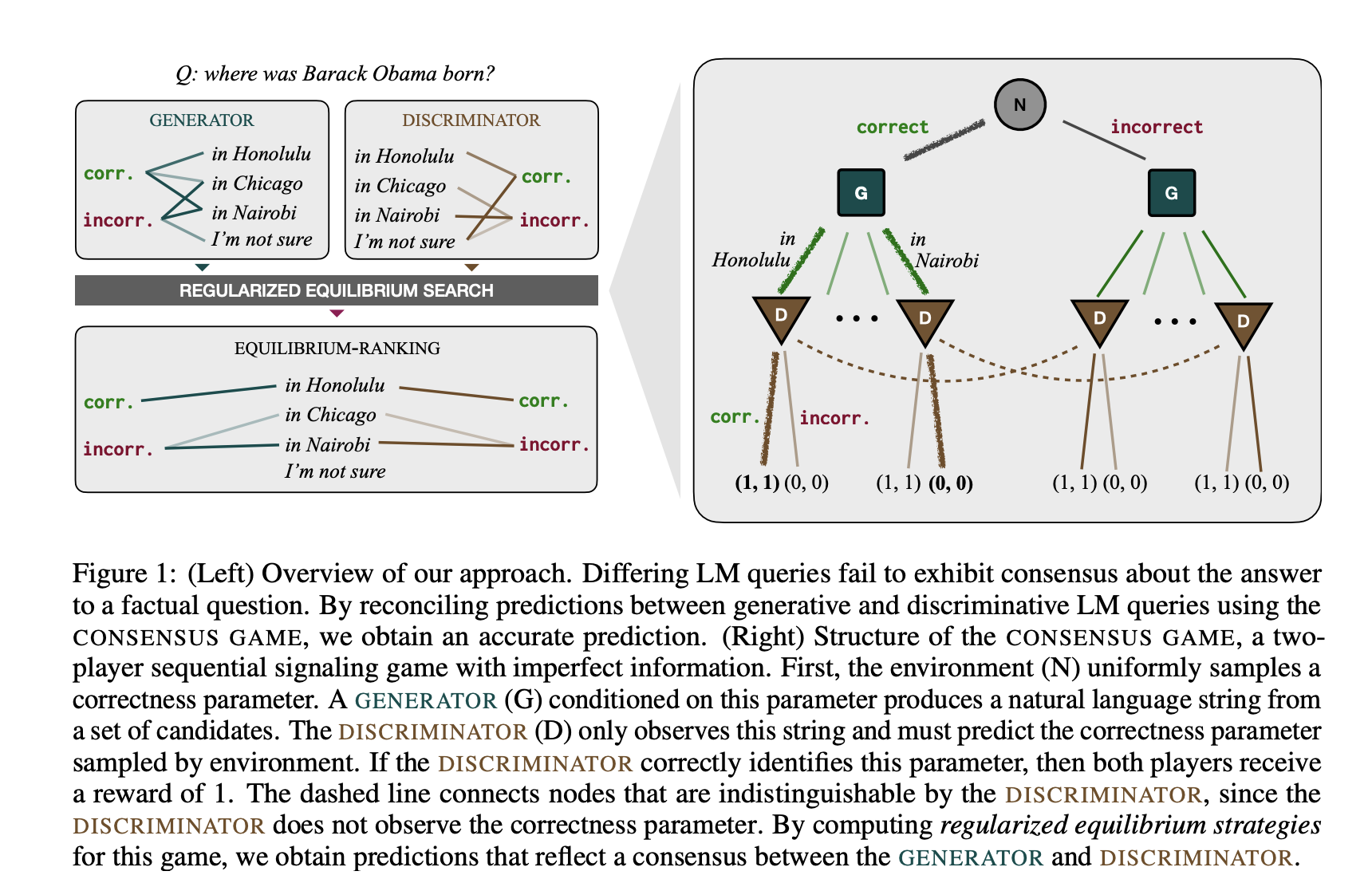
They can be used both generatively (by asking for the most likely answer to a question) and discriminatively (by presenting a (question-answer pair and asking whether the answer is acceptable), but these two methods sometimes yield different results. Generative methods can fail when probability mass is spread across multiple contradictory answers, whereas discriminative methods can fail because of miscalibration or a subtle dependence on the question. How should they extract an LM’s best estimate about the truth from these chaotic and frequently contradicting signals? The CONSENSUS GAME, a signaling game, is used in this research by researchers from MIT to offer a method for bridging generative and discriminative LM decoding processes.
A DISCRIMINATOR agent must convey an abstract correct or wrong value to a GENERATOR agent at a high level. Still, it can only do so by utilizing a limited number of potential natural language strings. It seems to reason that a combined policy, where the GENERATOR and DISCRIMINATOR agree on the assignment of strings to correctness values, would be a successful approach for this game. They can examine an approach like that to find candidates everyone agrees are right. A multi-step game with a difficult (string-valued) action space must be solved to do this. No-regret learning algorithms have been popular recently as the go-to method for calculating winning tactics in games like Poker, Stratego, and Diplomacy.
Here, they demonstrate that they may also be used for tasks involving the creation of free-form languages. This game-theoretic method of LM decoding is known as EQUILIBRIUM-RANKING. When used in 6 benchmarks for question-answering performance (MMLU, ARC, RACE, HHH, TruthfulQA, and GSM8K), EQUILIBRIUM-RANKING significantly outperforms the generative, discriminative, and mixed decoding techniques now in use. In a broader sense, their findings demonstrate how the game-theoretic toolset may be used to formalize and enhance coherence in LMs. The accuracy of factual tasks also improves as a result of increased coherence.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.