Deciphering Memorization in Neural Networks: A Deep Dive into Model Size, Memorization, and Generalization on Image Classification Benchmarks
To learn statistically, one must balance memorization of training data and transfer to test samples. However, the success of overparameterized neural models casts doubt on this theory; these models can memorize yet still generalize well, as seen by their ability to correctly match random labels, for example. To attain perfect accuracy in classification, i.e., interpolate the training set, such models are commonly used in practice. This has sparked a slew of studies investigating the generalizability of these models.
Feldman recently showed that memorization may be required for generalization in certain contexts. Here, “memorization” is defined by a stability-based term with theoretical underpinnings; high memorization instances are those that the model can only correctly categorize if included in the training set. For practical neural networks, this term permits estimation of the degree of memorization1 of a training sample. Feldman and Zhang examined a ResNet’s memorization profile while using it to classify images using industry-standard standards.
While this is an intriguing initial look at what real-world models remember, a fundamental question remains: do larger neural models memorize more? New York-based Google researchers answer this topic empirically, providing a complete look at image classification standards. They discover that training examples display a surprising variety of memorization trajectories across model sizes, with some samples showing cap-shaped or growing memorization and others revealing decreasing memorization under larger models.
To produce high-quality models of varied sizes, practitioners use a systematic process, knowledge distillation. Specifically, it entails creating high-quality little (student) models with guidance from high-performing large (teacher) models.
Feldman’s concept of memorization has been used to theoretically examine the relationship between memorization and generalization across a range of model sizes. The following are their contributions based on the results of controlled experiments:
- A quantitative investigation of the relationship between model complexity (such as the depth or width of a ResNet) and memorization for image classifiers is presented. The primary findings show that as the complexity of the model increases, the distribution of memorization across examples becomes increasingly bi-modal. They also note that other computationally tractable methods of assessing memorization and, for example, difficulty miss capturing this essential trend.
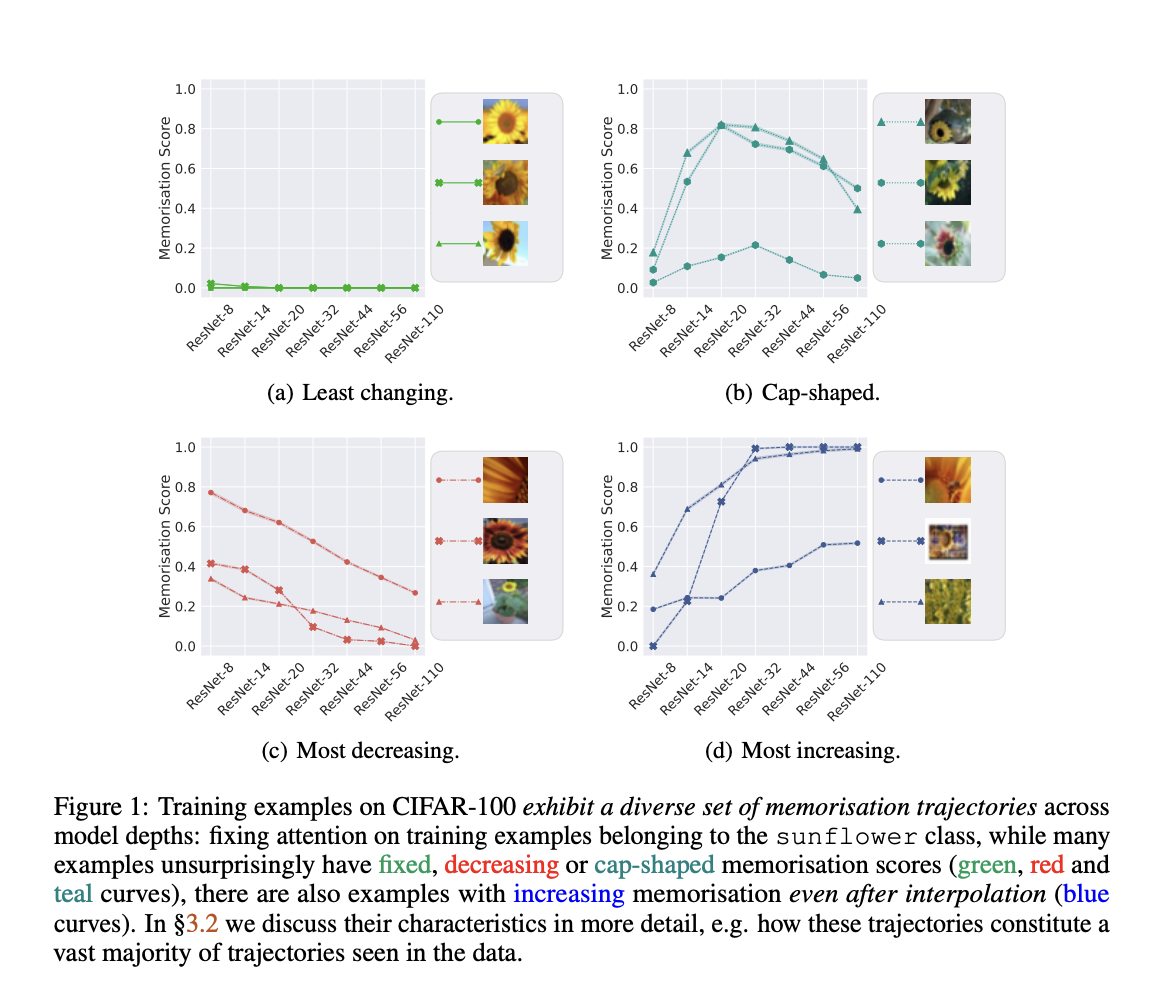
- They give instances displaying different memorization score trajectories across model sizes, and they identify the four most frequent trajectory types, including those where memorization increases with model complexity, to investigate the bi-modal memorization trend further. Specifically, nebulous and mislabeled cases are found to follow this pattern.
- Regarding samples that the one-hot (i.e., non-distilled) student memorizes, the researchers conclude with a quantitative study showing that distillation tends to impede memorization. Interestingly, they find memorization is hampered primarily for the cases in which memorization improves with model size. This finding suggests that distillation aids generalization by reducing the need to memorize such challenging circumstances.
The researchers begin by quantitatively analyzing the relationship between model complexity (the depth and width of a ResNet used for image classification) and memorization. They provide a graphic representation of the relationship between ResNet depth and memorization score on two well-known datasets (CIFAR-100 and ImageNet). Their investigation reveals that contrary to their initial beliefs, the memorization score decreases after reaching a depth of 20.
Researchers conclude that a greater bimodal distribution of memorization across diverse examples occurs as model complexity increases. They also point out a problem with current computationally feasible approaches for evaluating memorization and example difficulty by showing that these methods fail to capture this crucial pattern.
The study group gives examples with varied memorizing score trajectories across different model sizes to dig deeper into the bi-modal memorization pattern. They single out four main classes of trajectories, one of which involves memorization improving with model complexity. In particular, they discover that both unclear and mislabeled samples tend to follow this pattern.
The study concludes with a quantitative analysis showing that the process of distillation, by which knowledge is transferred from a big instructor model to a smaller student model, is associated with a decrease in memorization. This blockade is most noticeable for samples memorized by the one-hot, non-distilled student model. It’s interesting to note that distillation predominantly reduces memorization when memorization rises with increased model size. Based on this evidence, we can conclude that distillation improves generalization by preventing us from memorizing too many difficult examples.
In Conclusion:
The discovery by Google researchers has substantial practical implications and potential future directions for research. First, it’s important to use caution while memorizing specific data using only proxies. Various metrics defined in terms of model training or model inference have been proposed as effective surrogates for the memorization score in prior publications. These proxies provide a high agreement rate with memorization. Still, researchers have found that they differ greatly in distribution and fail to represent essential features of the memorization behavior of real-world models. This suggests a path forward for locating effectively computable proxies for memorization scores. The complexity of examples has been previously classified as a predetermined model size. The investigation results highlight the value of considering several model sizes when characterizing examples. For instance, Feldman defines the long tail examples of a dataset as the ones with the highest memorization score for a certain architecture. The results show that memorized information for one model size may not apply to another.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.