This AI Research Introduces ‘RAFA’: A Principled Artificial Intelligence Framework for Autonomous LLM Agents with Provable Sample Efficiency
While LLMs’ reasoning capabilities are excellent, they still need to be improved to apply those capabilities in practical settings. In particular, how to proveably accomplish a task with minimal interactions with the outside world (e.g., via an internal method of reasoning) is still a matter of conjecture.
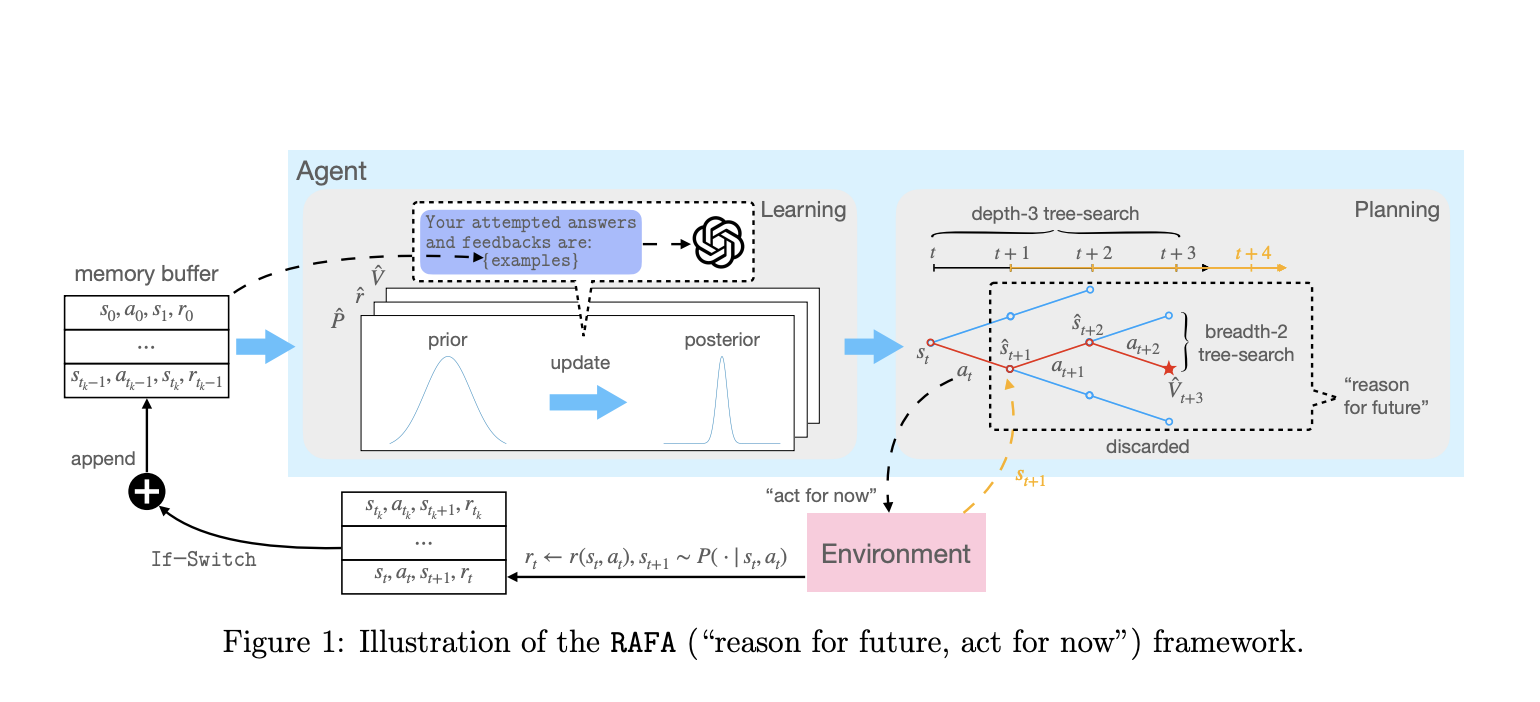
To choreograph reasoning and action, a new study by Northwestern University, Tsinghua University, and the Chinese University of Hong Kong presents a moral framework called “reason for future, act for now” (RAFA), which provides verifiable regret guarantees. To be more precise, they create a long-term trajectory planner (“reason for future”) that learns from the memory buffer’s prompts for reasoning.
Within a Bayesian adaptive MDP paradigm, they formally describe how to reason and act with LLMs. At each stage, the LLM agent does the first action of the planned trajectory (“act for now”), saves the gathered feedback in the memory buffer, and then re-invokes the reasoning routine to replan the future trajectory based on the current state.
Learning and planning in Bayesian adaptive Markov decision processes (MDPs) is the central principle, which is then used to represent reasoning in LLMs as MDPs. Similarly, they instruct LLMs to learn a more accurate posterior distribution over the unknown environment by consulting the memory buffer and designing a series of actions that will maximize some value function. When the external environment’s state changes, the LLM agent again calls on the reasoning routine to plot a new course of action. To maintain consistency in learning and planning, the researchers use a switching condition to determine if the more recent historical data should be used.
Several text-based benchmarks assess RAFA’s performance, including Game of 24, ALFWorld, BlocksWorld, and Tic-Tac-Toe. RAFA is an AI system that uses a linguistic model to carry out RL/PL tasks. The main points are summed up here.
- In the game 24, RAFA determines how to get 24 by adding and subtracting four different natural numbers. The algorithm keeps track of the most recent formula and produces the next procedure to reach this objective. In terms of sample efficiency, RAFA performs exceptionally well.
- ALFWorld is a virtual world where users may run simulations of household chores using embodied agents. RAFA achieves better results than competing frameworks like AdaPlanner, ReAct, and Reflexion.
- In BlocksWorld, players are tasked with building structures out of blocks. Compared to other models such as Vicuna, RAP, and CoT, RAFA’s success rates are significantly higher.
- RAFA acts as “O” in a game of Tic-Tac-Toe against a language model acting as “X.” The “O” penalty does not prevent RAFA from competing with and even outperforming the language model in some settings. The researchers believe selecting a different planning depth (B = 3 or B = 4) might improve or decrease sample efficiency.
In conclusion, RAFA is a flexible algorithm that excels in various settings and tasks, demonstrating amazing sample efficiency and often exceeding other existing frameworks.
Check out the Paper, Github, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.