Researchers from Google and the University of Toronto Introduce Groundbreaking Zero-Shot Agent for Autonomous Learning and Task Execution in Live Computer Environments

Large language models (LLMs) for action production in various live contexts, such as ALFWORLD and ALPHACODE, have shown promise in earlier efforts. Examples include SAYCAN, REACT, TOOLFORMER, and SWIFTSAGE. LLMs are used similarly to follow expert trails, understand environmental changes, plan and carry out future activities, and compose API requests. Several studies, including REFLEXION and SELF-REFINE, have demonstrated that repeatedly performing a task with numerous rounds of self-reflection may significantly enhance task completion. LLMs are asked to modify a previous execution plan in light of environmental feedback. Such adjustments are incorporated into the action generator’s prompt for the subsequent round.
MINIWOB++ has recently been utilized as a testbed to evaluate LLM’s performance on modularized computing workloads. Using comprehensive trace examples of the task for direct supervision (WebGUM), self-supervision, or few/many shot prompting (SYNAPSE) are standard methods for learning a task. They have completed dozens of computer jobs with a task completion rate greater than 90%, seemingly solving the computer control issue. Nonetheless, the need for expert traces constrains the agent’s capacity to learn new jobs. Can an agent independently know and enhance its control over a computer without utilizing well-chosen traces as guidance? Researchers from Google Research and the University of Toronto suggest a zero-shot agent to answer this query.
Their agent is built on top of PaLM2, a recent LLM, and it uses a single set of instruction prompts for all activities rather than task-specific prompts. Additionally, contemporary efforts like RCI, ADAPLANNER, and SYNAPSE use screen representations that might include a lot more data than what is displayed to the user on the screen. For instance, Fig. 1 illustrates items that are contained in the HTML that are provided to the LLM but are not displayed on the screen. Arbitrarily, using this new knowledge makes the agent’s ability to complete the task easier. However, in typical usage scenarios, such information might not be easily accessible and, depending on it, could limit how widely the agent can be applied.
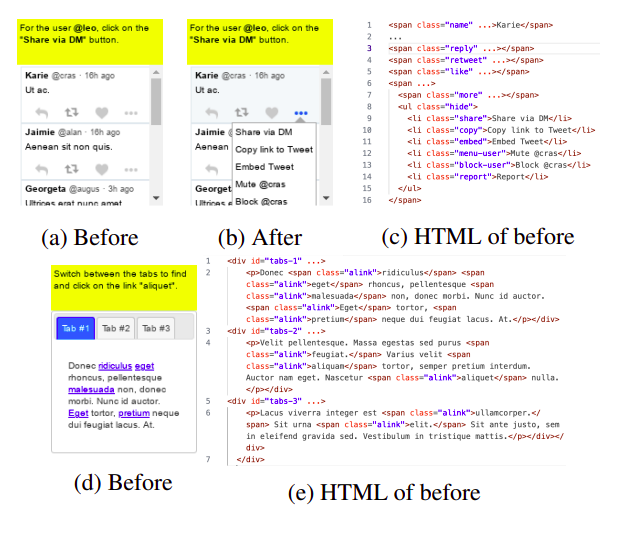
Figure 1 shows disparate displays on screens. Fig. 1a–1c shows the social media task before and after pressing the “more” button (seed=2). HTML has already made the material visible before clicking. Fig. 1d-1e: The click-tab-2 (seed=0) has a similar problem.
13 rather difficult jobs on MINIWOB++ that are meant to span many screens were carefully evaluated, and they discovered that 5 of them included HTML that contained such information—multi-screen information in a single observation. These are the contributions they made: First, in comparison to earlier studies, they adopt a condensed screen depiction, which makes the test environment more all-encompassing and realistic. Second, they provide a straightforward but effective action planner that, in a single pass, precisely plans out executable operations on a state. They demonstrate that such a “naive” approach can complete nearly all the simple tasks on the MINIWOB++ benchmark using the most recent LLM capacity.
To help the agent successfully learn from exploratory failures and advance in more difficult tasks, they suggest a systematic thought management technique that draws influence from Reflexion. Their agent achieves performance equivalent to previous few/many-shot state-of-the-art after a few rounds of tries. Their agent is the first zero-shot design for computer control tasks that they are aware of, according to research.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.