Meet FreeU: A Novel AI Technique To Enhance Generative Quality Without Additional Training Or Fine-tuning

Probabilistic diffusion models, a cutting-edge category of generative models, have become a critical point in the research landscape, particularly for tasks related to computer vision. Distinct from other classes of generative models, such as Variational Autoencoder (VAE), Generative Adversarial Networks (GANs), and vector-quantized approaches, diffusion models introduce a novel generative paradigm. These models employ a fixed Markov chain to map the latent space, facilitating intricate mappings that capture latent structural complexities within a dataset. Recently, their impressive generative capabilities, ranging from the high level of detail to the diversity of the generated examples, have pushed groundbreaking advancements in various computer vision applications such as image synthesis, image editing, image-to-image translation, and text-to-video generation.
The diffusion models consist of two primary components: the diffusion process and the denoising process. During the diffusion process, Gaussian noise is progressively incorporated into the input data, gradually transforming it into nearly pure Gaussian noise. In contrast, the denoising process aims to recover the original input data from its noisy state using a sequence of learned inverse diffusion operations. Typically, a U-Net is employed to predict the noise removal iteratively at each denoising step. Existing research predominantly focuses on the use of pre-trained diffusion U-Nets for downstream applications, with limited exploration of the internal characteristics of the diffusion U-Net.
A joint study from the S-Lab and the Nanyang Technological University departs from the conventional application of diffusion models by investigating the effectiveness of the diffusion U-Net in the denoising process. To gain a deeper understanding of the denoising process, the researchers introduce a paradigm shift towards the Fourier domain to observe the generation process of diffusion models—a relatively unexplored research area.

The figure above illustrates the progressive denoising process in the top row, showcasing the generated images at successive iterations. In contrast, the following two rows present the associated low-frequency and high-frequency spatial domain information after the inverse Fourier Transform, corresponding to each respective step. This figure reveals a gradual modulation of low-frequency components, indicating a subdued rate of change, whereas high-frequency components exhibit more pronounced dynamics throughout the denoising process. These findings can be intuitively explained: low-frequency components inherently represent an image’s global structure and characteristics, encompassing global layouts and smooth colors. Drastic alterations to these components are generally unsuitable in denoising processes as they can fundamentally reshape the image’s essence. On the other hand, high-frequency components capture rapid changes in the images, such as edges and textures, and are highly sensitive to noise. Denoising processes must remove noise while preserving these intricate details.
Considering these observations regarding low-frequency and high-frequency components during denoising, the investigation extends to determine the specific contributions of the U-Net architecture within the diffusion framework. At each stage of the U-Net decoder, skip features from the skip connections and backbone features are combined. The study reveals that the primary backbone of the U-Net plays a significant role in denoising, while the skip connections introduce high-frequency features into the decoder module, aiding in the recovery of fine-grained semantic information. However, this propagation of high-frequency features can inadvertently weaken the inherent denoising capabilities of the backbone during the inference phase, potentially leading to the generation of abnormal image details, as depicted in the first row of Figure 1.
In light of this discovery, the researchers propose a new approach referred to as “FreeU,” which can enhance the quality of generated samples without requiring additional computational overhead from training or fine-tuning. The overview of the framework is reported below.
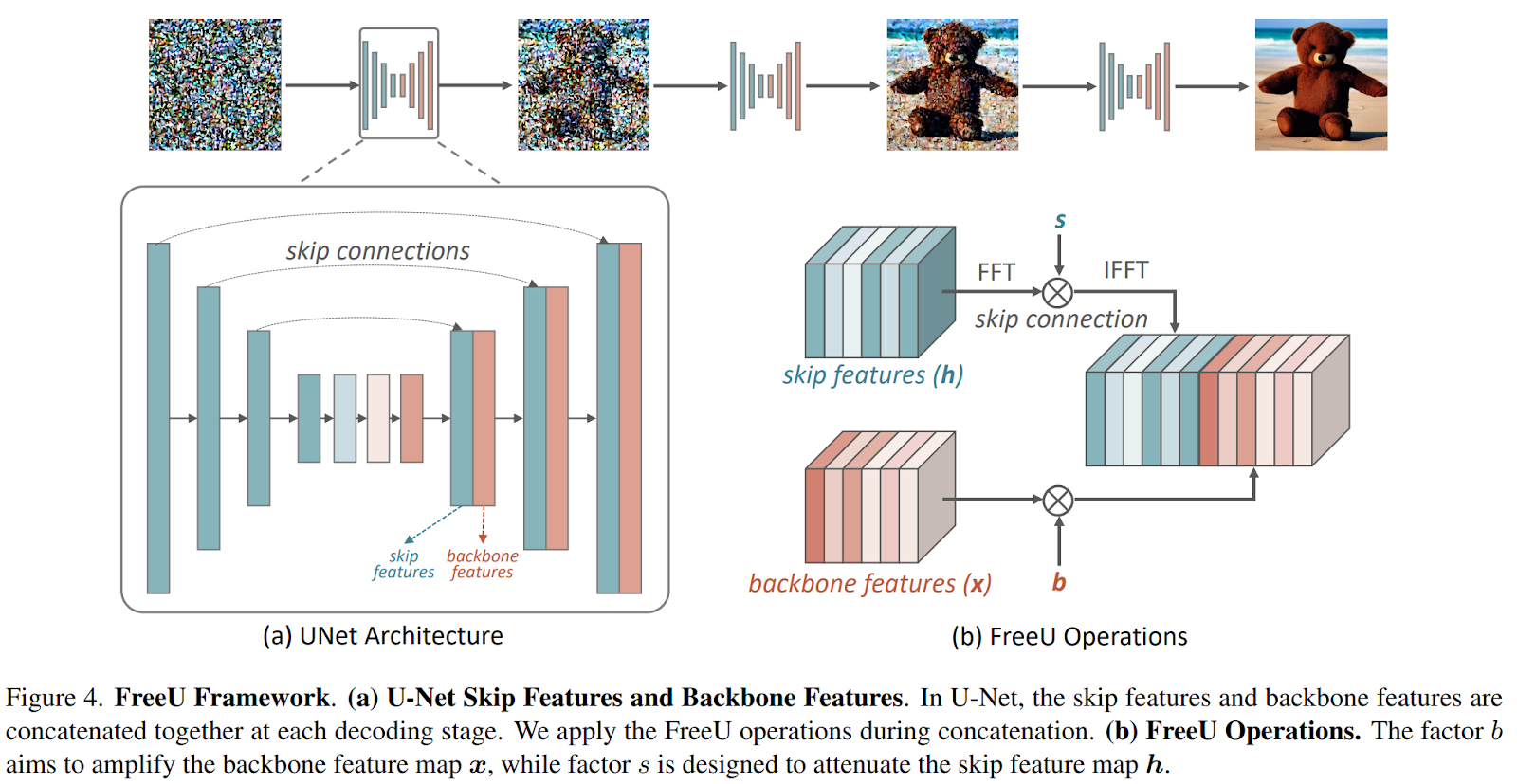
During the inference phase, two specialized modulation factors are introduced to balance the contributions of features from the primary backbone and skip connections of the U-Net architecture. The first factor, known as “backbone feature factors,” is designed to amplify the feature maps of the primary backbone, thereby strengthening the denoising process. However, it is observed that the inclusion of backbone feature scaling factors, while yielding significant improvements, can occasionally result in undesired over-smoothing of textures. To address this concern, the second factor, “skip feature scaling factors,” is introduced to mitigate the problem of texture over-smoothing.
The FreeU framework demonstrates seamless adaptability when integrated with existing diffusion models, including applications like text-to-image generation and text-to-video generation. A comprehensive experimental evaluation of this approach is conducted using foundational models such as Stable Diffusion, DreamBooth, ReVersion, ModelScope, and Rerender for benchmark comparisons. When FreeU is applied during the inference phase, these models show a noticeable enhancement in the quality of the generated outputs. The visual representation in the illustration below provides evidence of FreeU’s effectiveness in significantly improving both intricate details and the overall visual fidelity of the generated images.

This was the summary of FreeU, a novel AI technique that enhances generative models’ output quality without additional training or fine-tuning. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.