This AI Paper Presents Video Language Planning (VLP): A Novel Artificial Intelligence Approach that Consists of a Tree Search Procedure with Vision-Language Models and Text-to-Video Dynamics
With the constantly advancing applications of Artificial Intelligence, generative models are growing at a fast pace. The idea of intelligently interacting with the physical environment has been a topic of discussion as it highlights the significance of planning at two different levels: low-level underlying dynamics and high-level semantic abstractions. These two layers are essential for robotic systems to be properly controlled to carry out activities in the actual world.
The notion of dividing the planning problem into these two layers has long been recognized in robotics. As a result, many strategies have been developed, including combining motion with task planning and determining control rules for intricate manipulation jobs. These methods seek to produce plans that consider the goals of the work and the dynamics of the real environment. Talking about LLMs, these models can create high-level plans using symbolic job descriptions but have trouble implementing such plans. When it comes to the more tangible parts of tasks, such as shapes, physics, and limitations, they are incapable of reasoning.
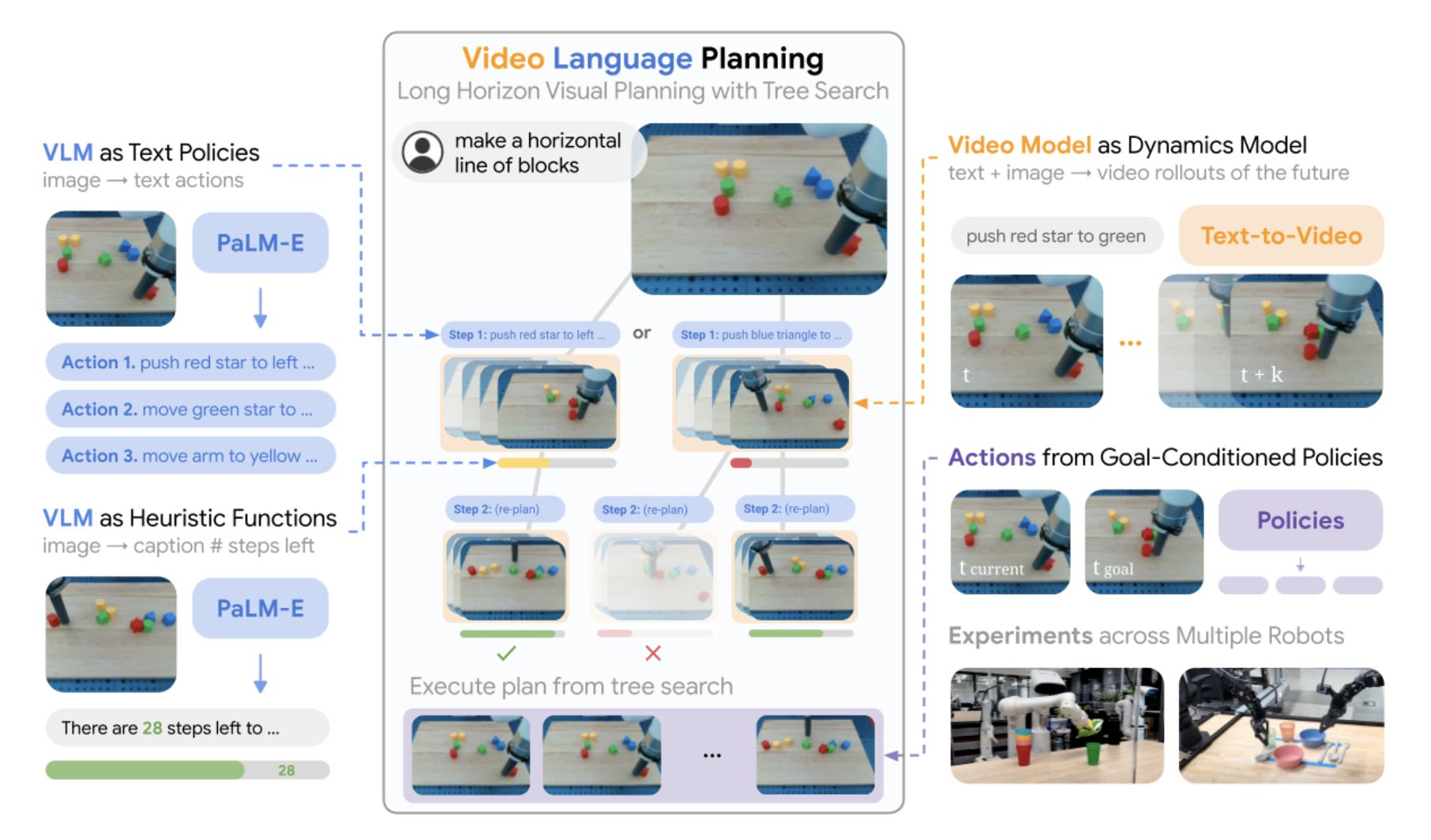
In recent research, a team of researchers from Google Deepmind, MIT, and UC Berkeley has proposed merging text-to-video and vision-language models (VLMs) to overcome the drawbacks. By combining the advantages of both models, this integration, known as Video Language Planning (VLP), has been introduced. VLP has been introduced with the goal of facilitating visual planning for long-horizon, complex activities. This method makes use of recent developments in huge generative models that have undergone extensive pre-training on internet data. VLP’s major objective is to make it easier to plan jobs that call for lengthy action sequences and comprehension in both the language and visual domains. These jobs could involve anything from simple object rearrangements to complex robotic system operations.
The foundation of VLP is a tree search process that has two primary parts, which are as follows.
- Vision-Language Models: These models fulfill the roles of both value functions and policies and support the creation and evaluation of plans. They are able to suggest the next course of action to complete the work after comprehending the task description and the available visual information.
- Models for Text-to-Video: These models serve as dynamics models as they have the ability to foresee how certain decisions will have an impact. They predict potential results derived from the behaviors suggested by the vision-language models.
A long-horizon task instruction and the current visual observations are the two primary inputs used by VLP. A complete and detailed video plan is the result of VLP, which provides step-by-step instructions on accomplishing the ultimate objective by combining language and visual features. It does a good job of bridging the gap between written work descriptions and visual comprehension.
VLP can do a variety of activities, including bi-arm dexterous manipulation and multi-object rearrangement. This flexibility demonstrates the approach’s wide range of possible applications. Real robotic systems may realistically implement the generated video blueprints. Goal-conditioned rules facilitate this conversion of the virtual plan into actual robot behaviors. These regulations enable the robot to carry out the task step-by-step by using each intermediate frame of the video plan as a guide for its actions.
Comparing experiments using VLP to earlier techniques, significant gains in long-horizon task success rates have been seen. These investigations have been carried out on real robots employing three different hardware platforms and in simulated situations.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.