A Comprehensive Review of Video Diffusion Models in the Artificial Intelligence Generated Content (AIGC)
Artificial Intelligence is booming, and so is its sub-field, i.e., the domain of Computer Vision. From researchers and academics to scholars, it is getting a lot of attention and is making a big impact on a lot of different industries and applications, like computer graphics, art and design, medical imaging, etc. Diffusion models have been the main technique for image production among the various approaches. They have outperformed strategies based on generative adversarial networks (GANs) and auto-regressive Transformers. These diffusion-based techniques are preferred because they are controllable, can create a wide range of outputs, and can produce extremely realistic images. They have found use in a variety of computer vision tasks, including 3D generation, video synthesis, dense prediction, and image editing.
The diffusion model has been crucial to the considerable advancements in computer vision, as evidenced by the recent boom in AI-generated content (AIGC). These models are not only achieving remarkable results in image generation and editing, but they are also leading the way in research connected to videos. While surveys addressing diffusion models in the context of picture production have been published, there are few recent reviews that examine their use in the video domain. Recent work provides a thorough evaluation of video diffusion models in the AIGC era in order to close this gap.
In a recent research paper, a team of researchers has highlighted how crucial diffusion models are in showing remarkable generative powers, surpassing alternative techniques, and exhibiting noteworthy performance in image generation and editing, as well as in the field of video-related research. The paper’s main focus is a thorough investigation of video diffusion models in the context of AIGC. It is separated into three main sections: duties related to creating, editing, and comprehending videos. The report summarises the practical contributions made by researchers, reviews the body of literature that has already been written in these fields, and organizes the work.
The paper has also shared the difficulties that researchers in this field face. It also delineates prospective avenues for future research and development in the field of video diffusion models and offers perspectives on potential future directions for the area as well as challenges that still need to be solved.
The primary contributions of the research paper are as follows.
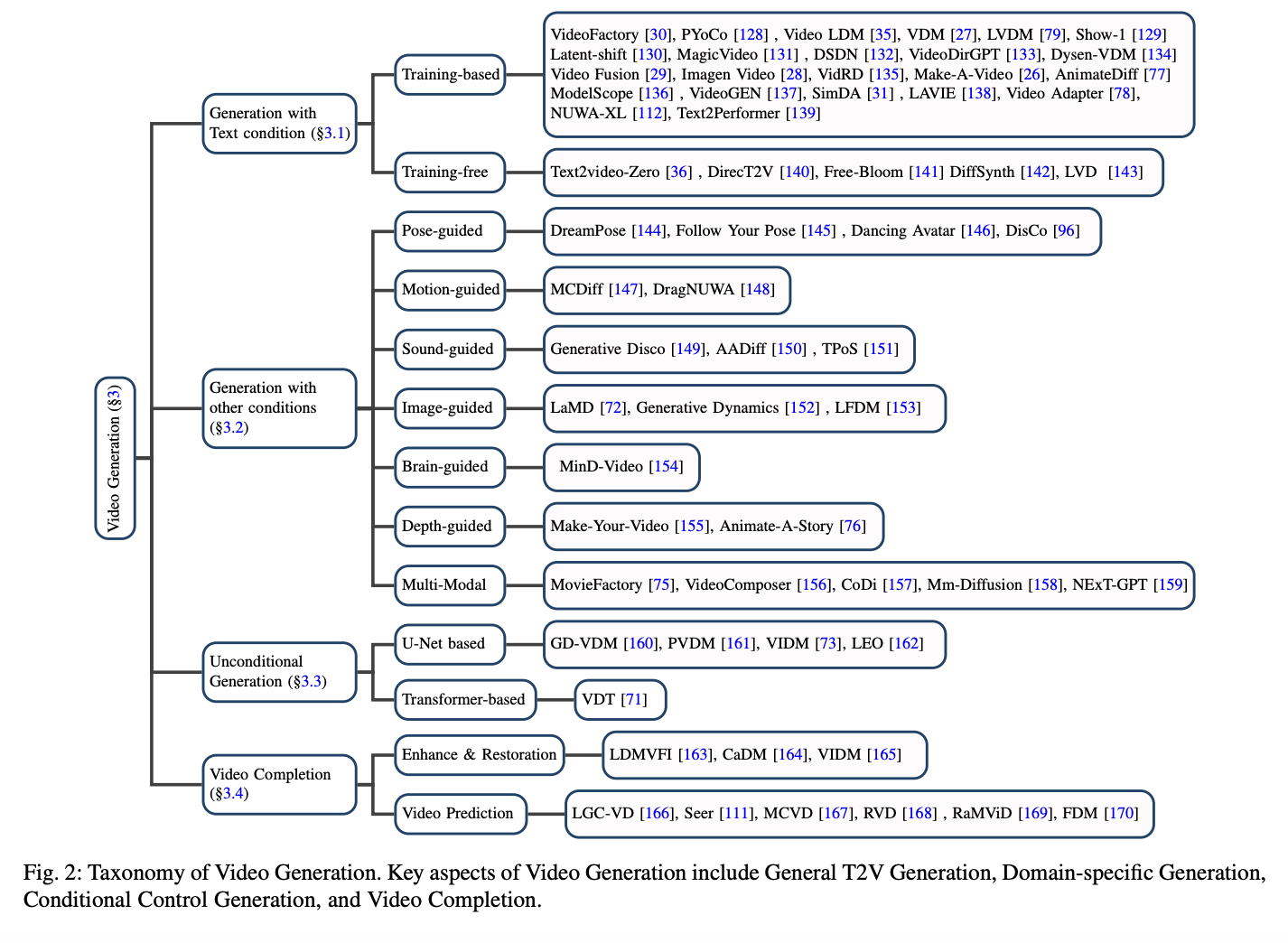
- Methodical monitoring and synthesis of current research on video dissemination models has been included, such as a range of topics like video creation, editing, and comprehension.
- Background information and pertinent data on video diffusion models have been introduced, along with datasets, assessment measures, and problem definitions.
- A summary of the most influential works on the topic, focusing on common technical information, has been shared.
- An in-depth examination and contrast of video-generating benchmarks and settings, addressing a critical need in the literature, has also been shared.
To sum up, this study is an invaluable tool for anyone curious about the most recent developments in video diffusion models in the context of AIGC. It also acknowledges the need for additional studies and reviews in the video domain, emphasizing the importance of diffusion models in the context of computer vision. The study provides a thorough overview of the topic by classifying and assessing previous work, highlighting potential future trends and obstacles for further investigation.
Check out the Paper and Github link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.