Revolutionizing Video Object Segmentation: Unveiling Cutie with Advanced Object-Level Memory Reading Techniques
Tracking and segmenting objects from an open vocabulary defined in a first-frame annotation is necessary for Video Object Segmentation (VOS), more precisely, the “semisupervised” option. VOS techniques may be coupled with Segment Anything Models (SAMs) for all-purpose video segmentation (such as Tracking Anything) and for robotics, video editing, and cost-reduction in data annotation. Modern VOS methods use a memory-based paradigm. Any new query frame “reads” from this memory to extract features for segmentation. This memory representation is generated using previous segmented frames (either supplied as input or segmented by the model).
Importantly, these methods create the segmentation bottom-up from the pixel memory readout and primarily employ pixel-level matching for memory reading, either with one or several matching layers. Pixel-level matching converts each memory pixel into a linear combination of query pixels (for example, using an attention layer). As a result, pixel-level matching has low-level consistency and is susceptible to matching noise, particularly when distractors are present. As a result, individuals perform worse in difficult situations, including occlusions and frequent distractions. Concretely, when assessing the recently suggested difficult MOSE dataset rather than the default DAVIS-2017 dataset, the performance of current techniques is more than 20 points in J & F worse.
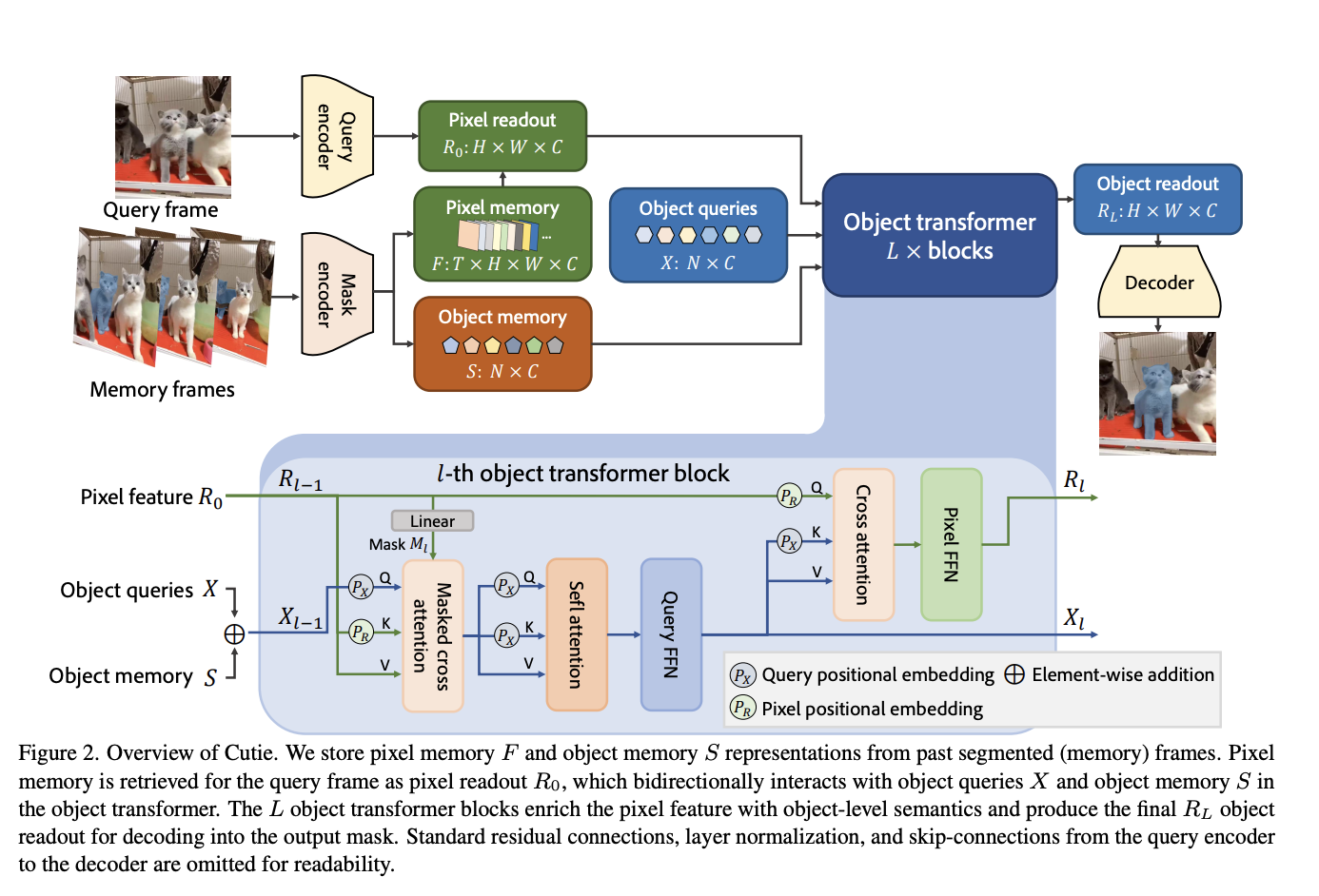
They believe the absence of object-level thinking is to blame for the disappointing outcomes in difficult cases. They suggest object-level memory reading to solve this problem, which effectively returns the object from memory to the query frame (Figure 1). They use an object transformer to achieve their object-level memory reading since current query-based object detection/segmentation methods that describe objects as “object queries” serve as inspiration. To 1) iteratively probe and calibrate a feature map (started by a pixel-level memory readout) and 2) encode object level information, this object transformer employs a limited collection of end-to-end trained object queries. This method allows for bidirectional top-down and bottom-up communication by maintaining a high-level/global object query representation and a low-level/high-resolution feature map.
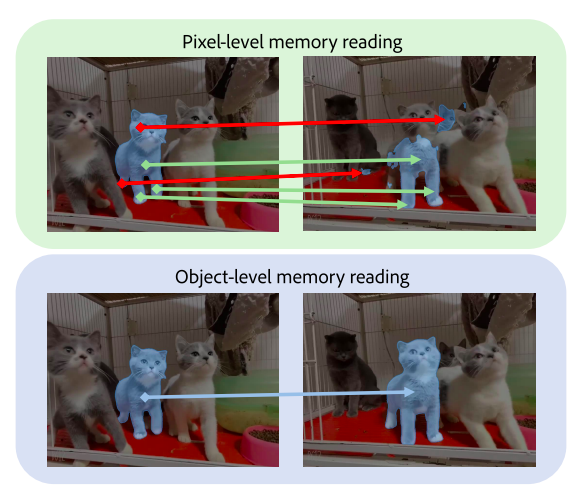
Figure 1 contrasts object-level memory reading with reading at the pixel level. The reference frame is on the left in each box, and the segmentable query frame is on the right. Wrong matches are shown with red arrows. When there are distractions, low-level pixel matching (like might become loud. For more reliable video object segmentation, we recommend object-level memory reading.
A series of attention layers, including a suggested foreground-background masked attention, are parameterized for this communication. Extended from foreground-only masked attention, masked attention allows some object queries to focus only on the foreground. In contrast, the remaining questions focus only on the background, enabling global feature interaction and clear foreground/background semantic distinction. Additionally, they incorporate a compact object memory (in addition to a pixel memory) to condense the characteristics of the target objects. With target-specific characteristics, this object memory improves end-to-end object searches and enables an effective long-term representation of target objects.
In tests, the suggested method, Cutie, outperforms previous methods in difficult situations (such as +8.7 J & F in MOSE over XMem) while maintaining competitive accuracy and efficiency levels on common datasets like DAVIS and YouTubeVOS. In conclusion, researchers from the University of Illinois Urbana-Champaign and Adobe Research created Cutie, which has an object transformer for reading object-level memories.
• It combines pixel-level bottom-up features with high-level top-down queries for effective video object segmentation in difficult situations with significant occlusions and distractions.
• They extend the masked focus to the foreground and background to distinguish the target item from distractions while preserving the rich scene elements.
• To store object characteristics in a compact form for later retrieval as target-specific object-level representations during querying, they build a compact object memory.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.