Researchers from the University of Washington and Princeton Present a Pre-Training Data Detection Dataset WIKIMIA and a New Machine Learning Approach MIN-K% PROB
Large Language Models (LLMs) are powerful models capable of processing large volumes of textual data. They are trained on a massive corpus of texts ranging from a few hundred GBs to even TBs. Given the scale of this data, it becomes essential to find out if the training data contains problematic texts like copyrighted material or personally identifiable information. Moreover, because of the rate at which the training corpora has grown, the developers of these LLMs have now become more reluctant to disclose the full composition of their data.
In this paper, a group of researchers from the University of Washington and Princeton University have studied the above-mentioned issue. Given a piece of text and black-box access to an LLM, the researchers have tried to determine if the model was trained on the provided text. They have introduced a benchmark called WIKIMIA that includes both pretraining and non-pretraining data to support gold truth. They have also introduced a new detection method called MIN-K% PROB that identifies outlier words with low probabilities under the LLM.
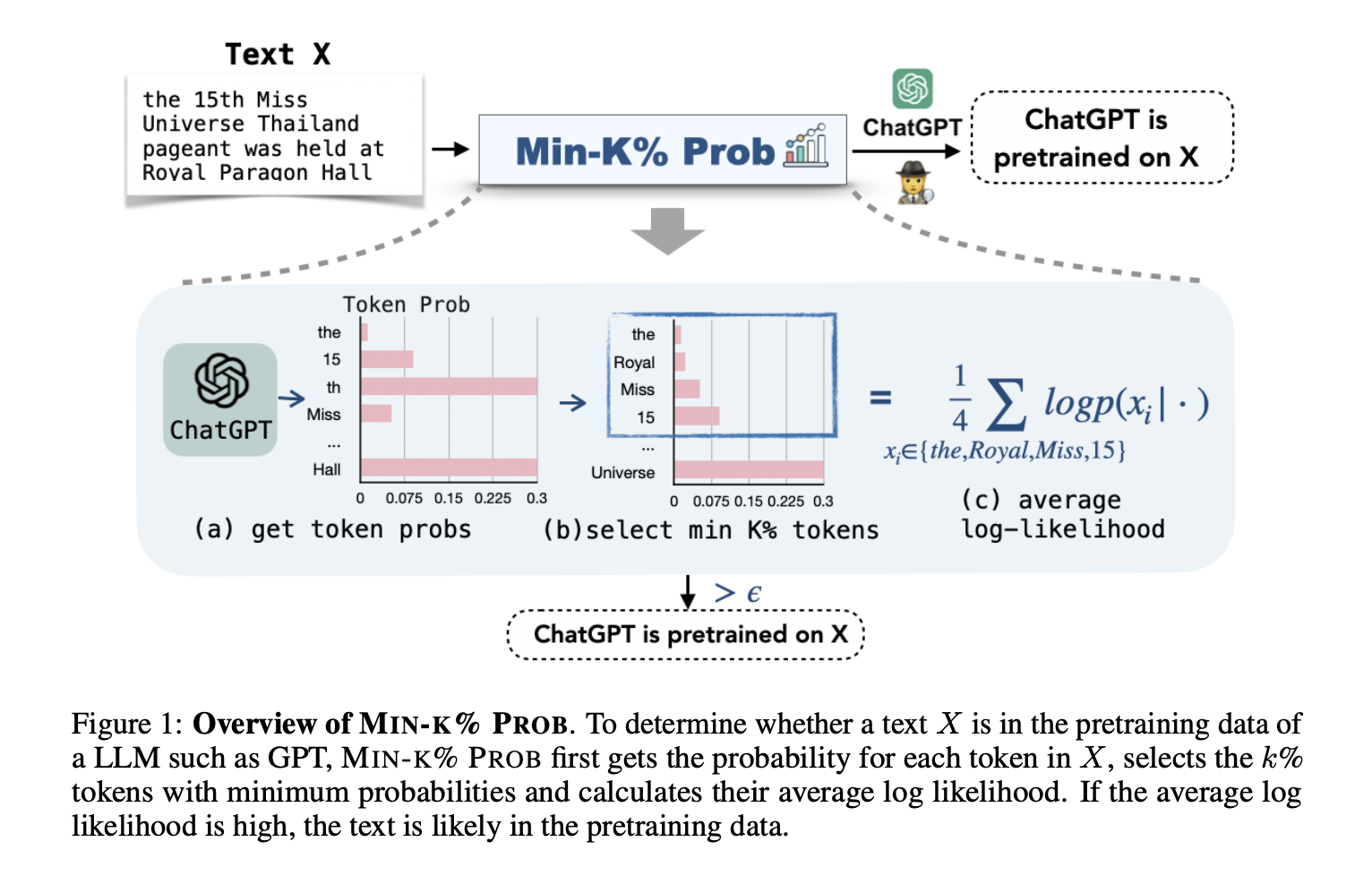
Having a reliable benchmark is essential in tackling the challenges of identifying problematic training text. WIKIMIA is a dynamic benchmark that automatically evaluates the detection methods on any newly released pretrained LLMs. The MIN-K% PROB method is based on the hypothesis that unseen text is more likely to contain words that the LLM doesn’t know well, and MIN-K% PROB calculates the average probability of these outlier words.
The way MIN-K% PROB works is as follows. Suppose we have a text X, and we have to determine whether the LLM was trained on X. The method uses the LLM to calculate the probabilities of each token in the given text. It then selects the k% of tokens with minimum probabilities and then calculates their average log-likelihood. A higher value of the same signifies that the text X is likely to be in the pretraining data.
The researchers applied the method of three real-life scenarios- copyrighted book detection, contaminated downstream example detection, and privacy auditing of machine unlearning. They took a test set of 10,000 text snippets from 100 copyrighted books and found that around 90% had a contamination rate of over 50%. The GPT-3 model, in particular, had text from 20 copyrighted books as per their findings.
For removing personal information and copyrighted data from LLMs, we use the Machine unlearning method. The researchers used the MIN-K% PROB method and found that LLMs can still generate similar copyrighted content even after unlearning copyrighted books.
In conclusion, the MIN-K% PROB is a new method to determine whether an LLM has been trained on copyrighted and personal data. The researchers verified the effectiveness of their methods using real-world case studies and found strong evidence that the GPT-3 model may have been trained on copyrighted books. They found this method to be a consistently effective solution in detecting problematic training text, and it marks a significant step forward toward better model transparency and accountability.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link
Comments are closed.