Is ConvNet Making a Comeback? Unraveling Their Performance on Web-Scale Datasets and Matching Vision Transformers
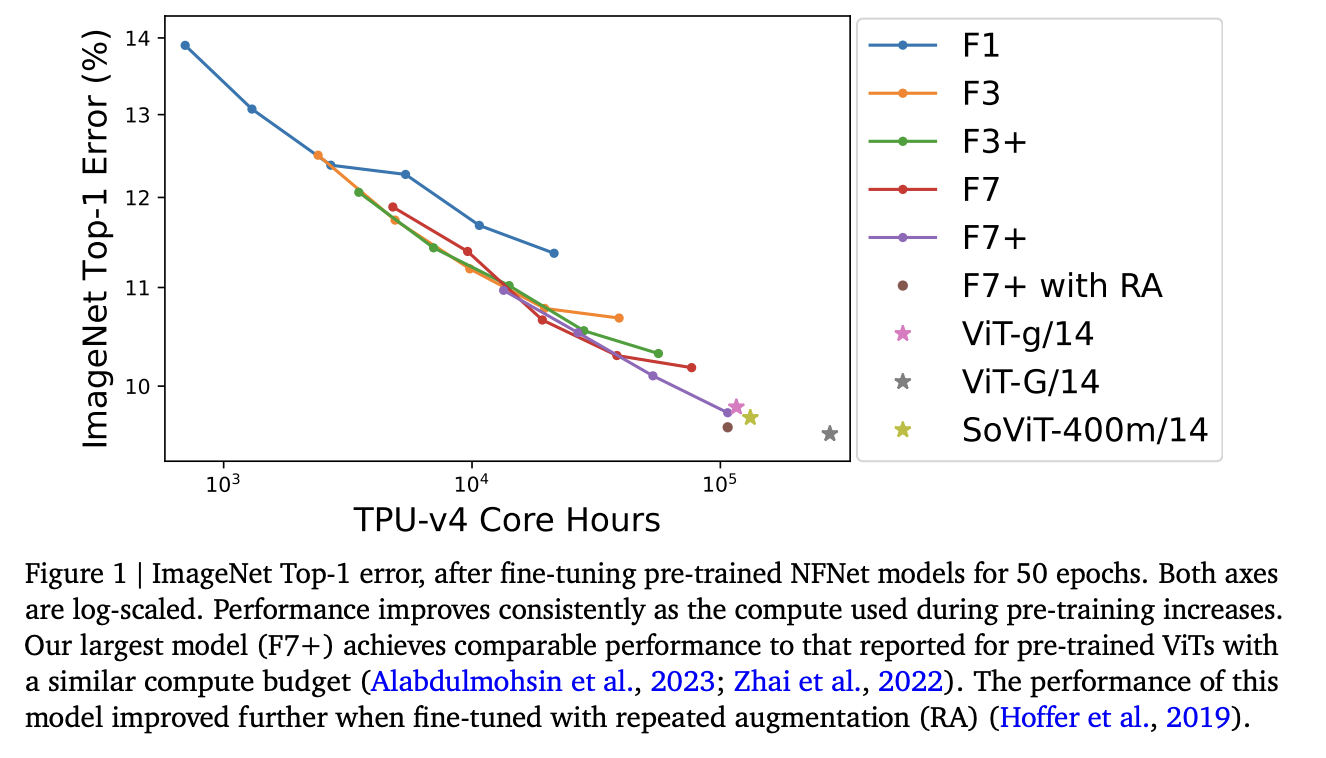
Researchers have challenged the prevailing belief in the field of computer vision that Vision Transformers (ViTs) outperform Convolutional Neural Networks (ConvNets) when given access to large web-scale datasets. They introduce a ConvNet architecture called NFNet, which is pre-trained on a massive dataset called JFT-4B, containing approximately 4 billion labeled images from 30,000 classes. Their aim is to evaluate the scaling properties of NFNet models and determine how they perform in comparison to ViTs with similar computational budgets.
In recent years, ViTs have gained popularity, and there’s a widespread belief that they surpass ConvNets in performance, especially when dealing with large datasets. However, this belief lacks substantial evidence, as most studies have compared ViTs to weak ConvNet baselines. Additionally, ViTs have been pre-trained with significantly larger computational budgets, raising questions about the actual performance differences between these architectures.
ConvNets, specifically ResNets, have been the go-to choice for computer vision tasks for years. Still, the rise of ViTs, which are Transformer-based models, has led to a shift in the way performance is evaluated, with a focus on models pre-trained on large, web-scale datasets.
Researchers introduce NFNet, a ConvNet architecture, and pre-train it on the vast JFT-4B dataset, adhering to the architecture and training procedure without significant modifications. They examine how the performance of NFNet scales with varying computational budgets, ranging from 0.4k to 110k TPU-v4 core compute hours. Their goal is to determine if NFNet can match ViTs in terms of performance with similar computational resources.
The research team trains different NFNet models with varying depths and widths on the JFT-4B dataset. They fine-tune these pre-trained models on ImageNet and plot their performance against the compute budget used during pre-training. They also observe a log-log scaling law, finding that larger computational budgets lead to better performance. Interestingly, they notice that the optimal model size and epoch budget increase in tandem.
The research team finds that their most expensive pre-trained NFNet model, an NFNet-F7+, achieves an ImageNet Top-1 accuracy of 90.3% with 110k TPU-v4 core hours for pre-training and 1.6k TPU-v4 core hours for fine-tuning. Furthermore, by introducing repeated augmentation during fine-tuning, they achieve a remarkable 90.4% Top-1 accuracy. Comparatively, ViT models, which often require more substantial pre-training budgets, achieve similar performance.
In conclusion, this research challenges the prevailing belief that ViTs significantly outperform ConvNets when trained with similar computational budgets. They demonstrate that NFNet models can achieve competitive results on ImageNet, matching the performance of ViTs. The study emphasizes that compute and data availability are critical factors in model performance. While ViTs have their merits, ConvNets like NFNet remain formidable contenders, especially when trained at a large scale. This work encourages a fair and balanced evaluation of different architectures, considering both their performance and computational requirements.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.