Shedding Light on Cartoon Animation’s Future: AnimeInbet’s Innovation in Line Drawing Inbetweening
Cartoon animation has seen significant progress since its beginnings in the early 1900s when animators would draw individual frames by hand on paper. While automation techniques have been introduced to assist with specific tasks in animation production, such as colorization and special effects, the fundamental aspect, which involves hand-drawing line drawings of characters for each frame, remains a labor-intensive endeavor in 2D animation.
The development of an automated algorithm for generating intermediate line drawings from two input key frames, a process commonly known as “in-betweening,” has the potential to significantly enhance productivity within the industry. Line in-betweening presents distinct challenges compared to general frame interpolation due to the sparsity of line drawings. These drawings typically consist of approximately 3% black pixels, with the remainder of the image being a white background. This uniqueness poses two critical challenges for existing raster-image-based frame interpolation methods. First, the absence of texture in line drawings makes it difficult to accurately compute pixel-wise correspondences in frame interpolation, resulting in inaccurate motion predictions due to multiple similar matching candidates for a single pixel. Second, the warping and blending techniques used in frame interpolation can lead to the blurring of essential boundaries between the line and the background, resulting in a significant loss of detail.
Considering the aforementioned issues, a novel deep-learning framework called “AnimeInbet” has been proposed to perform the in-betweening of line drawings in a geometrized format rather than raster images. The overview of the approach is presented in the figure below.
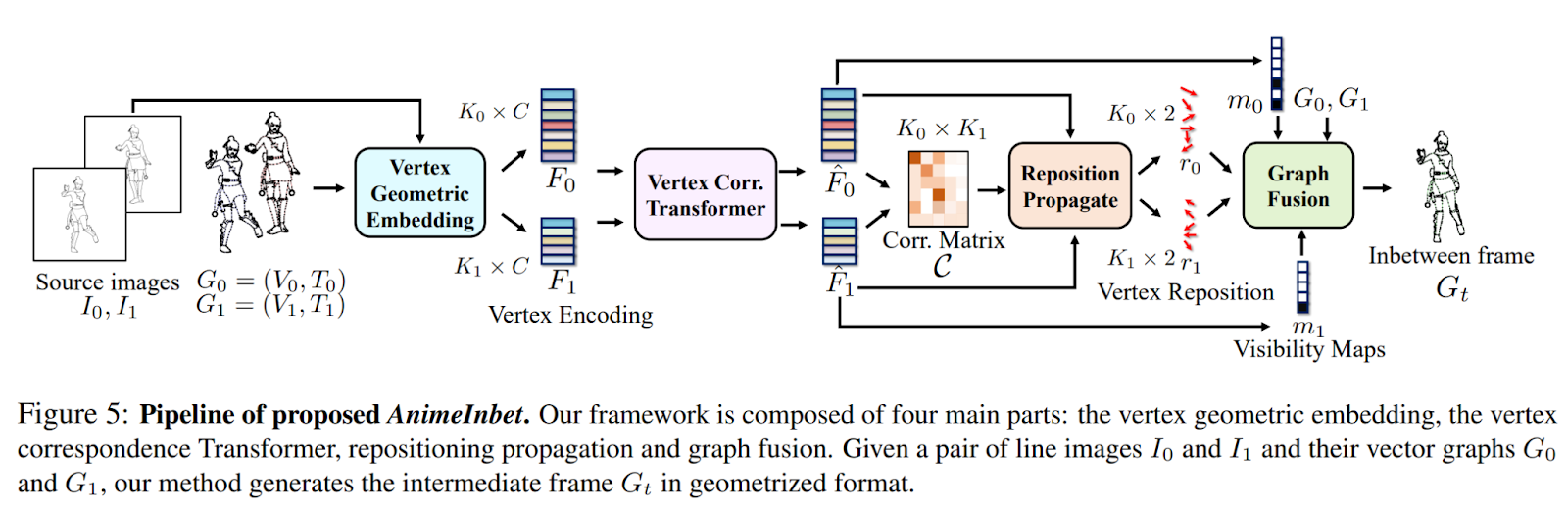
The process involves transforming the source images into vector graphs to synthesize an intermediate graph. This reformulation addresses the challenges outlined earlier in the paper. The matching process in the geometric domain focuses on concentrated geometric endpoint vertices rather than all pixels, reducing potential ambiguity and enhancing correspondence accuracy. Furthermore, the repositioning process preserves the topology of the line drawings, allowing for the retention of intricate and meticulous line structures.
The fundamental concept underlying the AnimeInbet framework is the identification of matching vertices between two input line drawing graphs, followed by their relocation to create a novel intermediate graph. The process begins with the development of a strategy for encoding the vertices, allowing for the differentiation of geometric features at the endpoints of sparsely drawn lines. Subsequently, a vertex correspondence Transformer is employed to establish matches between the endpoints in the two input line drawings. Shift vectors from the matched vertices are then propagated to unmatched vertices based on the similarity of their aggregated features, facilitating the repositioning of all endpoints. Lastly, the framework predicts a visibility mask to remove the vertices and edges that are obscured in the in-betweened frame, ensuring the creation of a clean and complete intermediate frame.
To support supervised training for vertex correspondence, a new dataset named MixamoLine240 is introduced. This unique dataset offers line art with ground truth geometrization and vertex-matching labels. The 2D line drawings in the dataset are selectively generated from specific edges of a 3D model, with the endpoints corresponding to the indexed 3D vertices. The use of 3D vertices as reference points ensures the accuracy and consistency of the vertex-matching labels in the dataset at the vertex level.
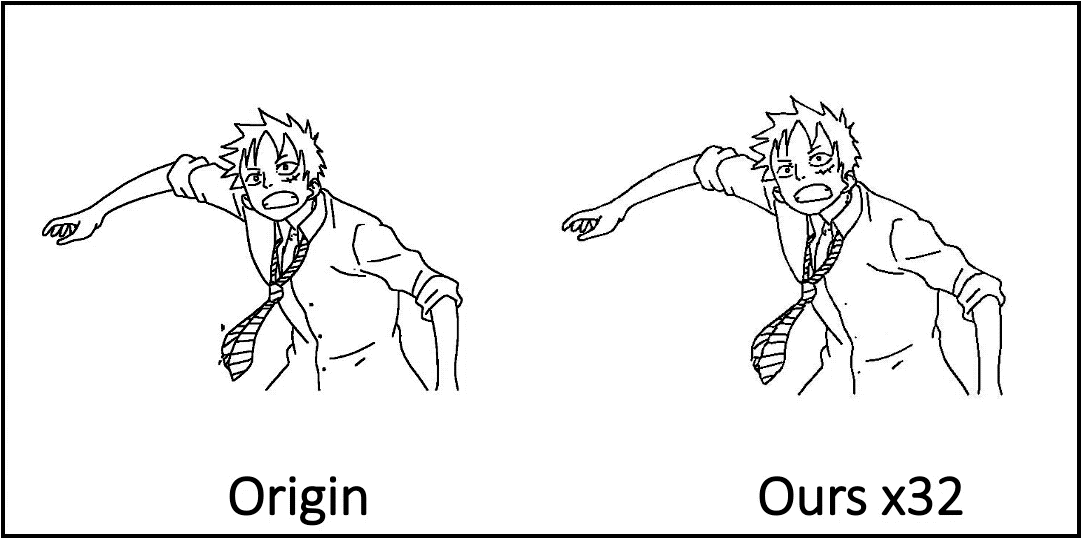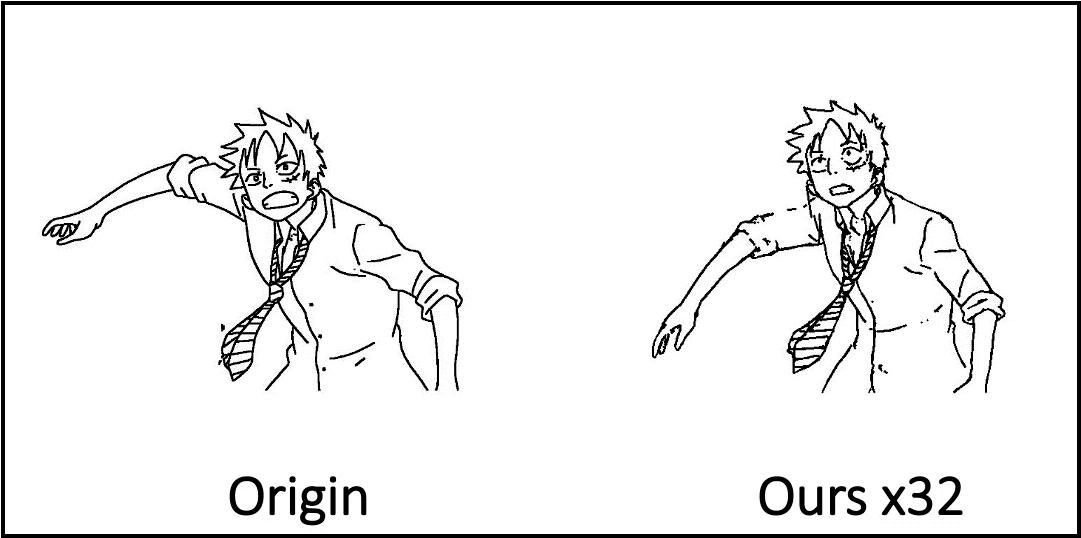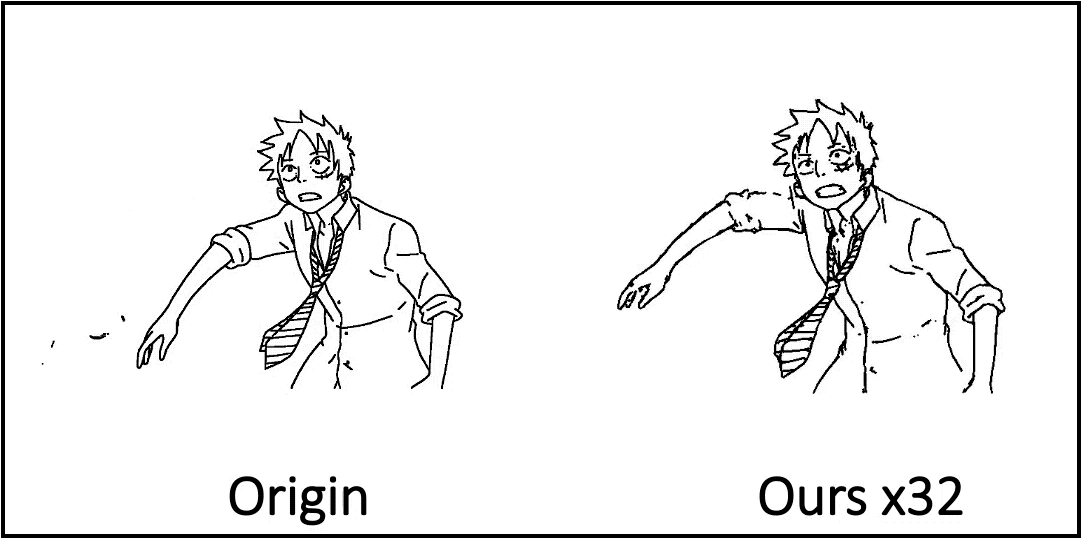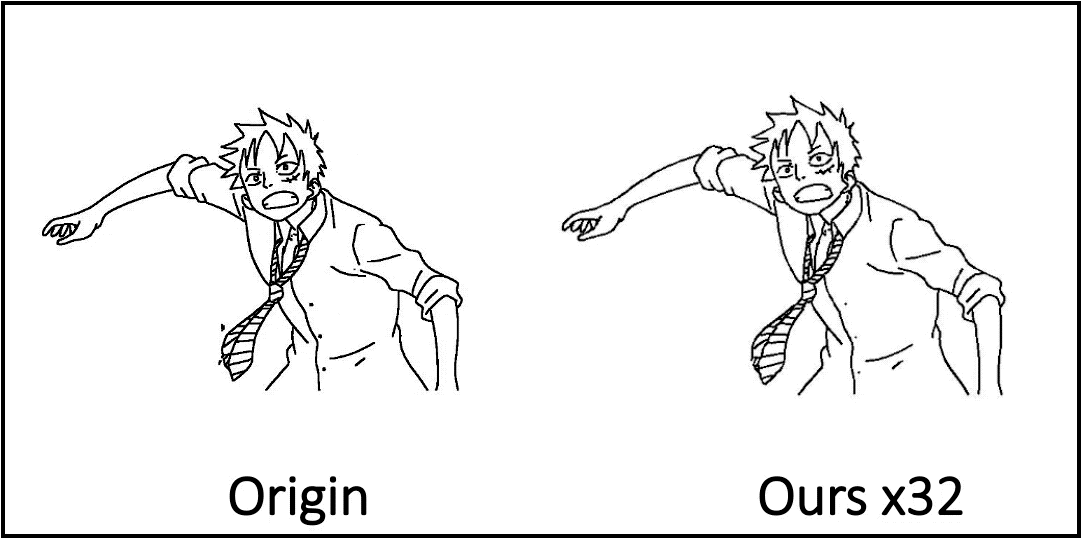
Compared to existing methods, the AnimeInbet framework has demonstrated its ability to generate clean and complete intermediate line drawings. Some examples taken from the study are reported below.
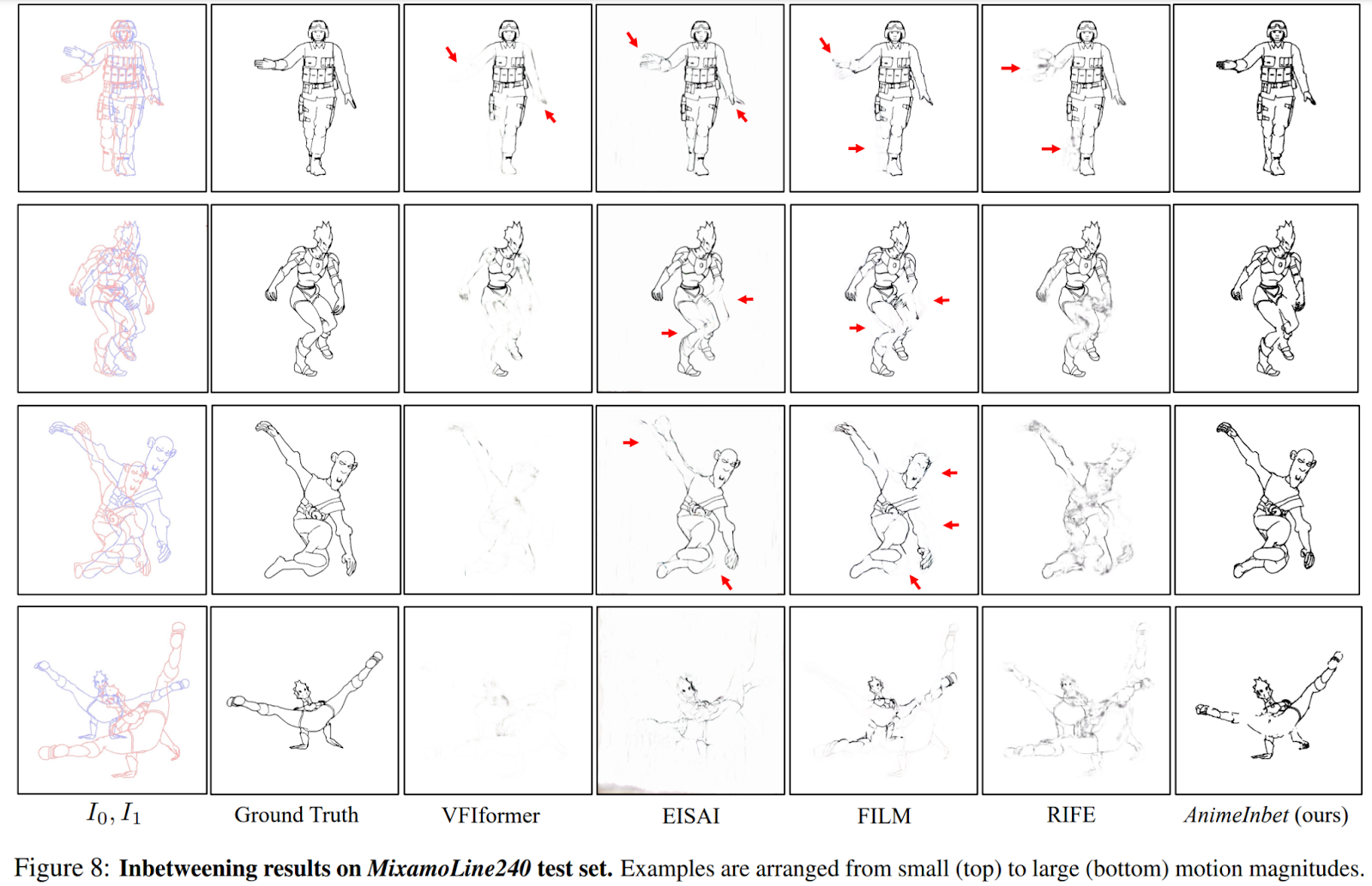
This was the summary of AnimeInbet, a novel AI technique that performs the in-betweening of line drawings in a geometrized format rather than raster images. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.