Researchers from China Introduced a Novel Compression Paradigm called Retrieval-based Knowledge Transfer (RetriKT): Revolutionizing the Deployment of Large-Scale Pre-Trained Language Models in Real-World Applications
Natural language processing (NLP) applications have shown remarkable performance using pre-trained language models (PLMs), including BERT/RoBERTa. However, because of their enormous complexity, these models—which generally have hundreds of millions of parameters—present a significant difficulty for researchers. Thus, large-scale pre-trained language models (PLMs) have not yet reached their full potential. Many model compression strategies, including weight sharing, quantization, network pruning, and knowledge distillation, have been put forth to address this problem. However, situations needing large compression ratios, such as knowledge distillation, are not directly relevant to these model compression techniques.
Adding assistance models frequently results in worse, more erratic performance when this happens. Large language models (LLMs) are becoming increasingly popular since they are highly skilled in language and may be used for various downstream activities. Therefore, investigating ways to apply this information to small-scale models is crucial. However, because LLMs have very high compression ratios, current methods are unsuitable for compressing them. Previous studies have proposed using LLMs for knowledge transfer and data augmentation to small-scale models, enabling the latter to show enhanced performance on low-resource datasets.
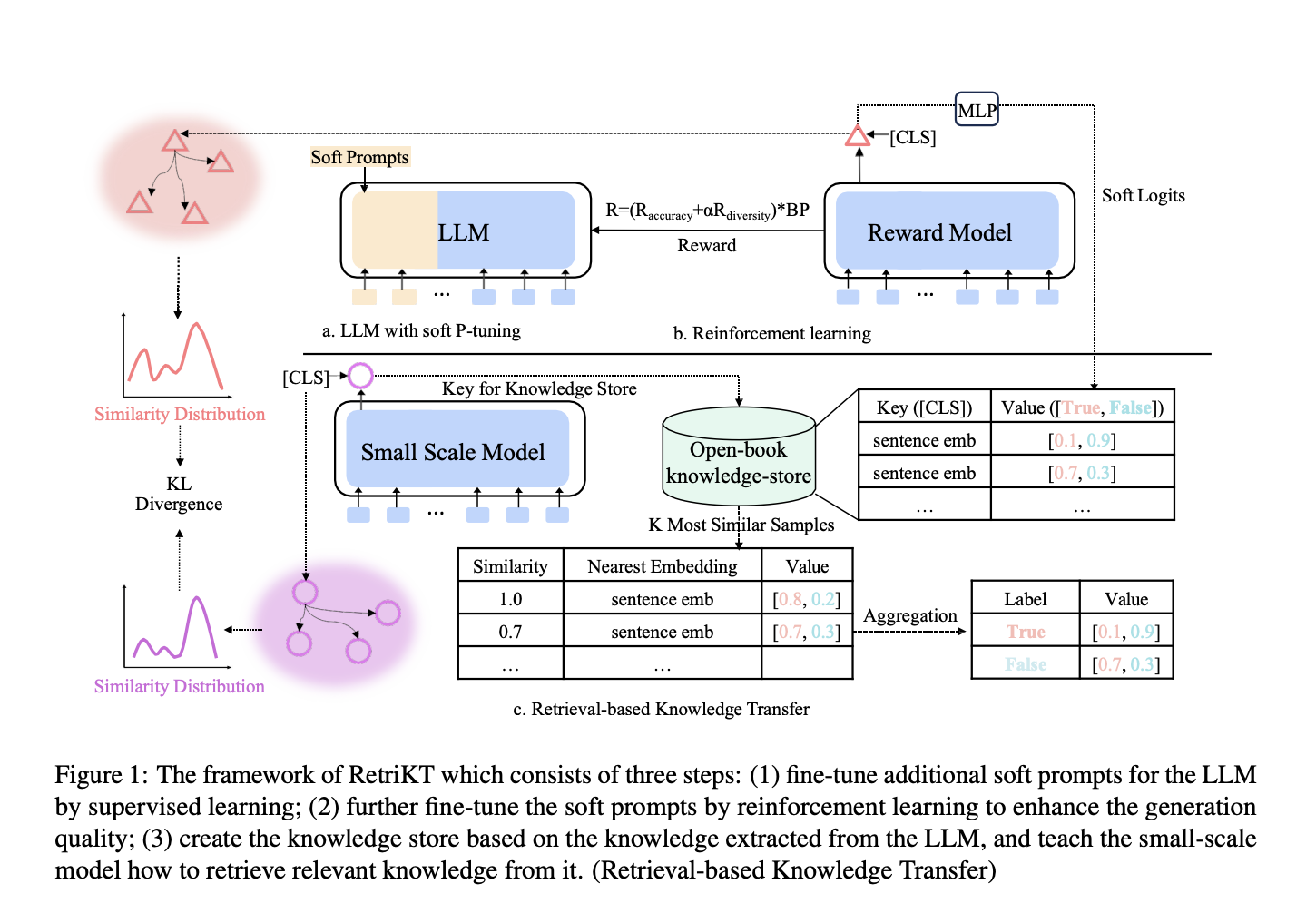
Nevertheless, small-scale models’ constrained parameter sizes pose an obstacle when taking on more difficult tasks like the SuperGLUE benchmark, making retaining the information that LLMs impart easier. As a result, the performance gain attained for small-scale models still needs to be improved. Researchers from Peking University, Meituan, Meta AI, National Key Laboratory of General Artificial Intelligence, BIGAI and Renmin University of China propose a revolutionary compression paradigm dubbed Retrieval-based information transmission (RetriKT), which aims to efficiently and precisely transmit the information of Large Language Models (LLMs) to small-scale models. Their method consists of two primary steps: first, knowledge is extracted from the LLM to create a knowledge store, and then the small-scale model retrieves pertinent information from the knowledge store to complete the job.
To be more precise, they use the method of soft prompt tuning to adjust an LLM such that it produces samples that are within the domain. They also provide the Proximal Policy Optimization (PPO) reinforcement learning technique to improve the generation quality. Lastly, the small-scale model gains the ability to obtain relevant data from the knowledge store. They conduct comprehensive tests on genuinely difficult and low-resource jobs taken from the SuperGLUE and GLUE benchmarks. The experimental findings show that using LLM information, RetriKT greatly improves small-scale model performance and beats earlier SOTA knowledge distillation approaches.
This suggests that the retrieval-based knowledge transfer paradigm for severe model compression is practicable and successful. The following is a summary of their contributions:
• Retrieval-based information transmission, a novel compression paradigm they suggest, attempts to transmit information from LLMs to incredibly small-scale models.
• To improve the generation quality, they carefully construct the incentive function and propose the reinforcement learning algorithm PPO. This paradigm tackles the problem of obtaining extreme model compression when there is a large difference in model size.
• Through comprehensive tests on low-resource tasks from the SuperGLUE and GLUE benchmarks, they improve the accuracy and diversity of knowledge collected from LLMs used for knowledge transfer. The findings show that by utilizing the information from LLMs, RetriKT considerably improves the performance of small-scale models and surpasses earlier SOTA knowledge distillation techniques.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.