Unlocking Intent Alignment in Smaller Language Models: A Comprehensive Guide to Zephyr-7B’s Breakthrough with Distilled Supervised Fine-Tuning and AI Feedback
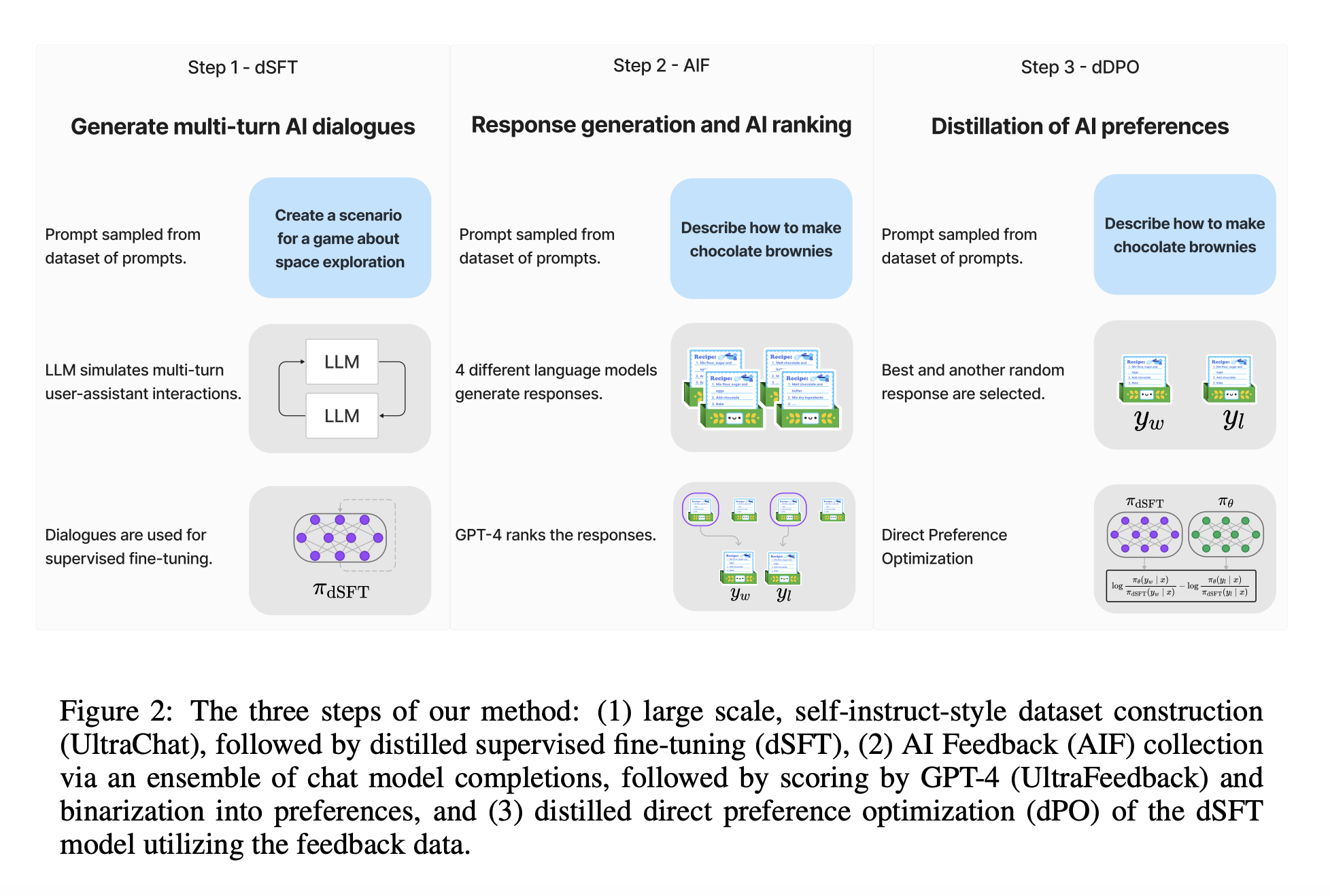
ZEPHYR-7B, a smaller language model optimized for user intent alignment through distilled direct preference optimization (dDPO) using AI Feedback (AIF) data. This approach notably enhances intent alignment without human annotation, achieving top performance on chat benchmarks for 7B parameter models. The method relies on preference data from AIF, requiring minimal training time and no additional sampling during fine-tuning, setting a new state-of-the-art.
Researchers address the proliferation of LLMs like ChatGPT and its derivatives, such as LLaMA, MPT, RedPajama-INCITE, Falcon, and Llama 2. It underscores advancements in fine-tuning, context, retrieval-augmented generation, and quantization. Distillation techniques for improving smaller model performance are discussed, along with tools and benchmarks for model evaluation. The study evaluates ZEPHYR-7B’s performance on MTBench, AlpacaEval, and the HuggingFace Open LLM Leaderboard.
The study discussed enhancing smaller open LLMs using distilled supervised fine-tuning (dSFT) for improved accuracy and user intent alignment. It introduces dDPO to align LLMs without human annotation, relying on AIF from teacher models. Researchers present ZEPHYR-7B, an aligned version of Mistral-7B, achieved through dSFT, AIF data, and dDPO, demonstrating its performance comparable to 70B-parameter chat models aligned with human feedback. It emphasizes the significance of intent alignment in LLM development.
The approach outlines a method for enhancing language models, combining dSFT to train the model with high-quality data and dDPO to refine it by optimizing response preferences. AIF from teacher models is used to improve alignment with user intent. The process involves iterative self-prompting to generate a training dataset. The resulting ZEPHYR-7B model, achieved through dSFT, AIF data, and dDPO, represents a state-of-the-art chat model with improved intent alignment.
ZEPHYR-7B, a 7B parameter model, establishes a new state-of-the-art in chat benchmarks, surpassing LLAMA2-CHAT-70B, the best open-access RLHF-based model. It competes favourably with GPT-3.5-TURBO and CLAUDE 2 in AlpacaEval but lags in math and coding tasks. Among 7B models, the dDPO model excels, outperforming dSFT and Xwin-LM dPPO. However, larger models outperform ZEPHYR in knowledge-intensive tasks. Evaluation on the Open LLM Leaderboard shows ZEPHYR’s strength in multiclass classification tasks, affirming its reasoning and truthfulness capabilities after fine-tuning.
ZEPHYR-7B employs direct preference optimization to enhance intent alignment. The study underscores potential biases in using GPT-4 as an evaluator and encourages exploring smaller open models’ capacity for user intent alignment. It notes the omission of safety considerations, such as harmful outputs or illegal advice, indicating the need for future research in this vital area.
The study identifies several avenues for future research. Safety considerations, addressing harmful outputs and illegal advice, remain unexplored. Investigating the impact of larger teacher models on distillation for improving student model performance is suggested. The use of synthetic data in distillation, though challenging, is recognized as a valuable research area. Further exploration of smaller open models and their capacity for aligning with user intent is encouraged for potential advancements. Evaluating ZEPHYR-7B on a broader range of benchmarks and tasks is recommended to assess its capabilities comprehensively.
Check out the Paper, Github, and Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.