Researchers from Stanford Propose ‘EquivAct’: A Breakthrough in Robot Learning for Generalizing Tasks Across Different Scales and Orientations
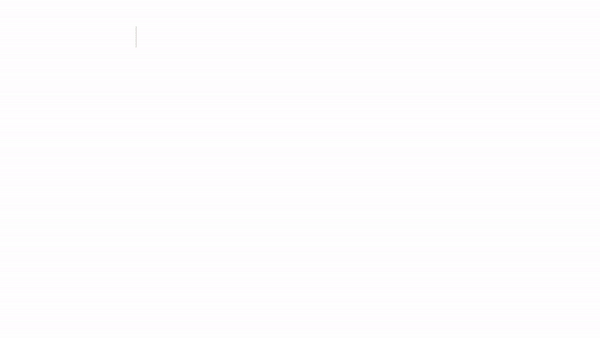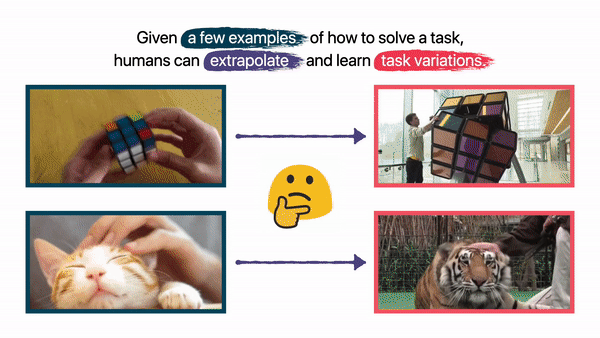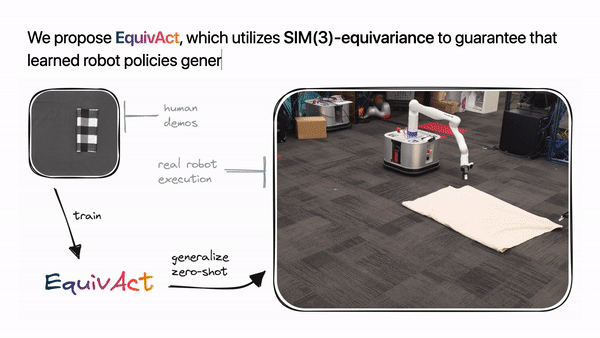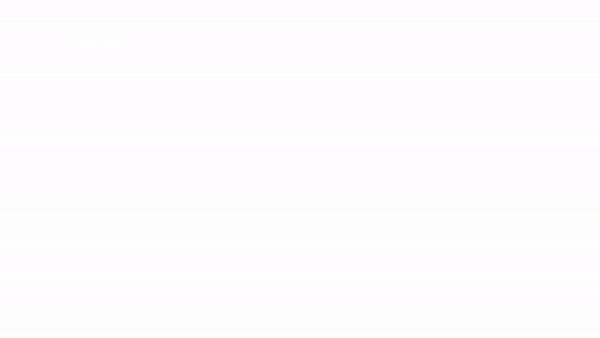
Humans can extrapolate and learn to solve variations of a manipulation task if the objects involved have varied visual or physical attributes, given just a few examples of how to complete the task with standard objects. To make the learnt policies universal to different object scales, orientations, and visual appearances, existing studies in robot learning still need considerable data augmentation. Despite these enhancements, however, generalization to undiscovered variations is not guaranteed.
A new paper by Stanford University investigates the challenge of zero-shot learning of a visuomotor policy that may take as input a small number of sample trajectories from a single source manipulation scenario and generalize to scenarios with unseen object visual appearances, sizes, and poses. In particular, it was important to learn policies to deal with deformable and articulated objects, like clothes or boxes, in addition to rigid ones, like pick-and-place. To ensure that the learnt policy is robust across different object placements, orientations, and scales, the proposal was to incorporate equivariance into the visual object representation and policy architecture.
They present EquivAct, a novel visuomotor policy learning approach that can learn closed-loop policies for 3D robot manipulation tasks from demonstrations in a single source manipulation scenario and generalize zero-shot to unseen scenarios. The learnt policy takes as input the robot’s end-effector postures and a partial point cloud of the environment and as output the robot’s actions, such as end-effector velocity and gripper commands. In contrast to most previous work, the researchers used SIM(3)- equivariant network architectures for their neural networks. This means that the output end-effector velocities will adjust in kind when the input point cloud and end-effector positions are translated and rotated. Since their policy architecture is equivariant, it can learn from demonstrations of smaller-scale tabletop activities and then zero-shot generalize to mobile manipulation tasks involving larger variations of the demonstrated objects with distinct visual and physical appearances.
This approach is split into two parts: learning the representation and the policy. To train the agent’s representations, the team first provides it with a set of synthetic point clouds that were captured using the same camera and settings as the target task’s objects but with a different random nonuniform scale. They supplemented the training data in this way to accommodate for nonuniform scaling, even if the suggested architecture is equivariant to uniform scaling. The simulated data doesn’t have to show robot activities or even demonstrate the actual task. To extract global and local features from the scene point cloud, they employ the simulated data to train a SIM(3)-equivariant encoder-decoder architecture. During training, a contrastive learning loss was used on paired point cloud inputs to combine local features for related object sections of objects in similar positions. During the policy-learning phase, it was presumed that access to a sample of previously-verified task trajectories is limited.
The researchers use data to train a closed-loop policy that, given a partial point cloud of the scene as input, uses a previously learned encoder to extract global and local features from the point cloud and then feeds those features into a SIM(3)-equivariant action prediction network to predict end effector movements. Beyond the standard rigid object manipulation tasks of previous work, the proposed method is evaluated on the more complex tasks of comforter folding, container covering, and box sealing.
The team presents many human examples in which a person manipulates a tabletop object for each activity. After demonstrating the method, they assessed it on a mobile manipulation platform, where the robots will have to solve the same problem on a much grander scale. Findings show that this method is capable of learning a closed-loop robot manipulation policy from the source manipulation demos and executing the target job in a single run without any need for fine-tuning. It is further demonstrated that the approach is more efficient than that and relies on significant augmentations for generalization to out-of-distribution object poses and scales. It also outperforms works that do not exploit equivariance.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.