Google AI Introduces Spectron: The First Spoken Language AI Model that is Trained End-to-End to Directly Process Spectrograms as Both Input and Output
Speech continuation and question-answering LLMs are versatile tools that can be applied to a wide array of tasks and industries, making them valuable for enhancing productivity, improving user experiences, and advancing research and development in various fields. Prominent examples of such LLMs include GPT-3 and its successors, which have gained significant attention for their impressive performance in understanding and generating text.
These LLMs are typically built on deep-learning architectures. They are pretrained on vast amounts of text data, enabling them to understand the nuances of human language and generate text that is contextually relevant and coherent by capturing the statistical patterns and structures of text-based natural language.
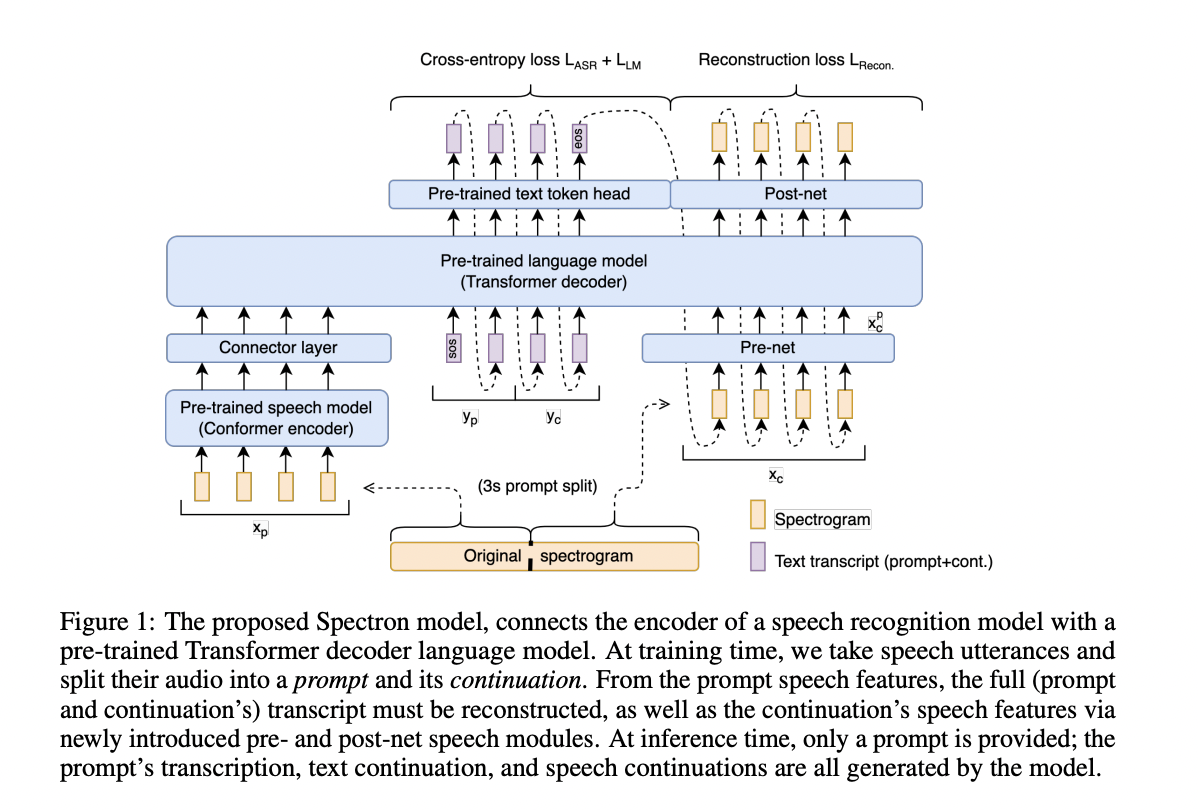
The team at Google Research and Verily AI introduced a new novel spoken language model named “Spectron“. This model directly processes spectrograms both as input and output. A spectrogram is a visual representation of the spectrum of frequencies of a signal as they vary with time. This model uses intermediate projection layers to leverage the audio capabilities of a pre-trained speech encoder. This model not only eliminates the inductive biases, which usually arise in a pre-trained encoder and decoder but also does it without sacrificing the representational fidelity.
The language model transcribes and generates text continuations, acting as an ‘intermediate scratchpad’, further conditioned for audio generation. The derivatives of the ground truth express rich, longer-range information about the signal’s shape. The team uses this fact to supervise the model match the higher-order temporal and feature deltas of the ground truth using the spectrogram regression.
The model’s architecture is initialized with a pre-trained speech encoder and a pre-trained language decode. The encoder is prompted with a speech utterance as input, and they are encoded into linguistic features. The features act as input to the decoder as a prefix, and the whole encoder-decoder is optimized to minimize cross-entropy jointly. This method provides a spoken speech prompt, encoded and then decoded to give both text and speech continuations.
The researchers used the same architecture to decode the intermediate text and the spectrograms. This has two benefits. Firstly, the pre-training of the LM in the text domain to continue the prompt in the text domain before synthesizing the speech. Secondly, the predicted text serves as intermediate reasoning, enhancing the quality of the synthesized speech, analogous to improvements in text-based language models.
However, their work is high time and space complex. It requires generating multiple spectrogram frames, which is time-consuming. This makes the generation of long speech utterances not possible. Another limitation is that the model can’t run the text and spectrogram decoding process in parallel. In the future, the team will be focusing on the development of a parallized decoding algorithm.
Check out the Paper and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.