This AI Research from Google Reveals How Encoding Graph Data Elevates Language Model Performance on Complex Tasks
Large language model (LLM) research and applications have advanced remarkably in recent years. These generative models have enthralled the artificial intelligence community, and many models trained on various tasks and modalities have been made available lately. A rising agreement has resulted from these developments, stating that LLMs are an important step towards artificial general intelligence (AGI). Still, several things could be improved in how LLMs are now designed and implemented despite all of their benefits. Their dependence on unstructured text is one of their most evident drawbacks since it can occasionally lead the models to overlook clear, logical inferences or imagine false conclusions.
Another is that LLMs have inherent limitations based on the time period they were taught, and it might be challenging to integrate “new” knowledge about how the world has evolved. One of the most adaptable forms of information representation is graph-structured data, which offers a potential remedy for both problems. It’s interesting to note that only a little research has been done at the intersection of graphs and LLMs despite this potential. For instance, even though graph databases and LLMs have received much attention, more research needs to be done on the broader applications of graph-structured data. Wang et al. have recently made an effort to solve this by creating a graph benchmarking challenge specifically for language models.
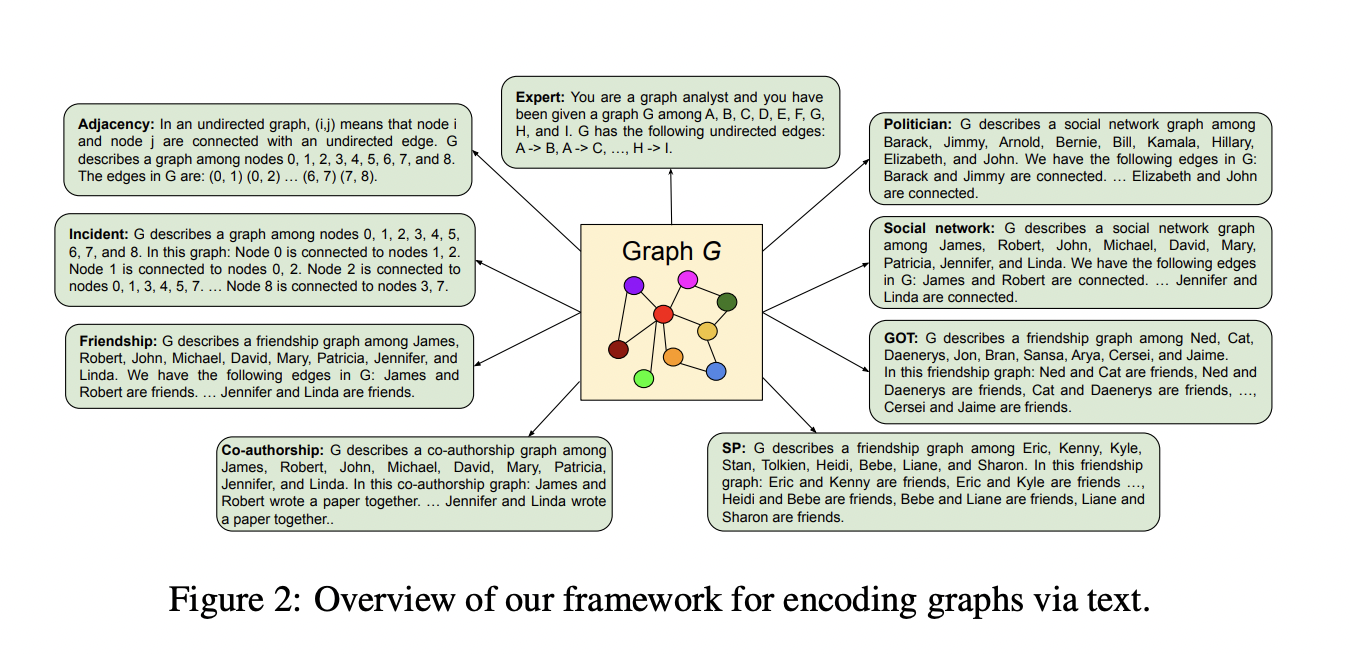
The removal of various natural graph challenges and the lack of variation in the types of graph structures addressed make for many unanswered concerns, even though their work marks an interesting starting effort into assessing LLM’s graph reasoning skills. Other recent work aims to use LLMs instead of graph-structured data, but it ignores some of the core problems with LLMs. Researchers from Google Research conducted the first thorough investigation on reasoning over graph-structured data as text that LLMs may read in this paper. They break down the issue into graph prompt engineering and graph encoding to examine graph reasoning in further detail.
We can use LLM’s acquired representations in graph problems by experimenting with different graph encoding techniques. While researching prompt engineering methods, one may choose the best approach to ask an LLM the question that they want to be answered. Their test findings aim to identify the scenarios in which various prompt heuristics perform optimally. To do so, they provide a brand-new set of benchmarks called GraphQA for evaluating the performance of LLM reasoning on graph data. Using graphs with a far more diverse and realistic graph structure than those previously investigated using LLMs sets GraphQA apart.
In particular, their work has contributed to the following:
1. A thorough examination of graph-structure prompting approaches for use in LLMs.
2. Best practices and insights for encoding graphs as text for LLM usage.
3. A brand-new graph benchmark called GraphQA to let the community better explore how graph structure affects LLM prompting.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.