Revolutionizing AI’s Listening Skills: Tsinghua University and ByteDance Unveil SALMONN – A Groundbreaking Multimodal Neural Network for Advanced Audio Processing
In several natural language processing applications, text-based big language models have shown impressive and even human-level performance. In the meanwhile, an LLM training paradigm known as instruction tuning—in which data is arranged as pairs of user instruction and reference response—has evolved that enables LLMs to comply with unrestricted user commands. Increasingly, researchers are interested in equipping LLMs with multimodal sensory skills. Current research focuses on linking LLMs to the encoder of one more input type—such as an image, silent video, audio event, or speech—or to the encoders of many input kinds together.
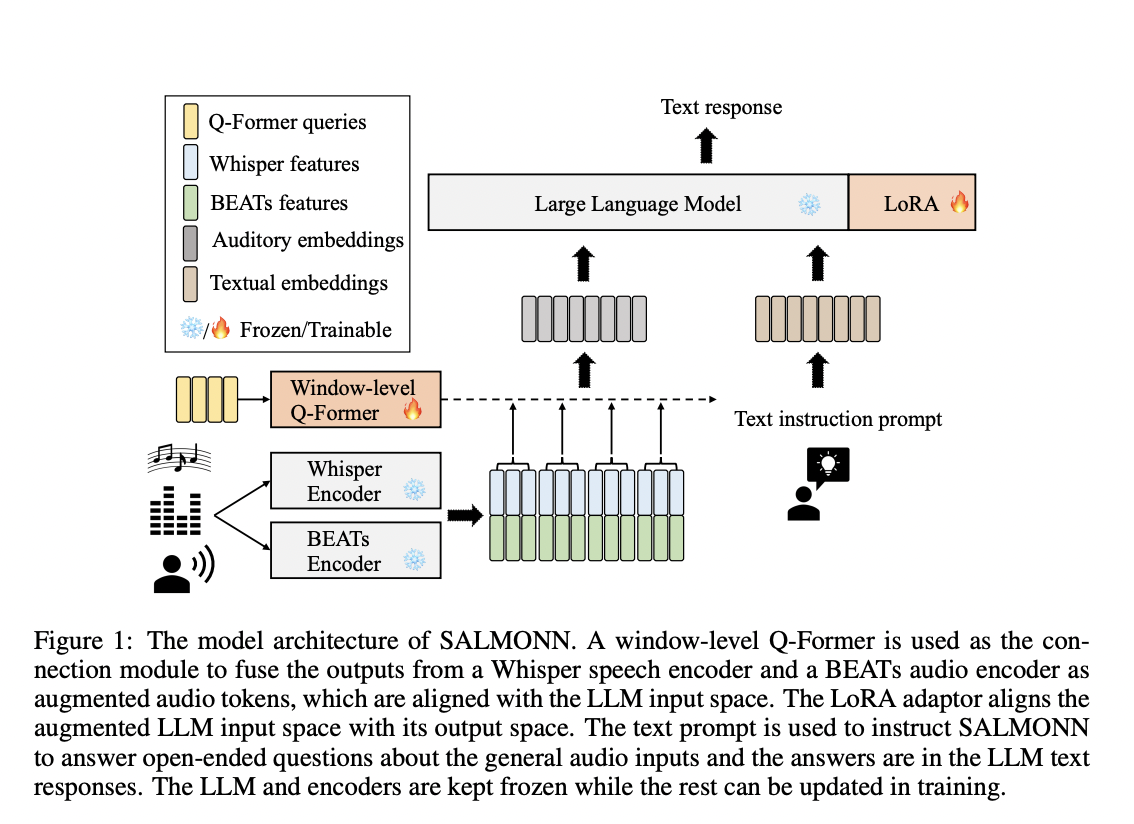
To align the encoder output spaces with the LLM input space—which is often taught through cross-modal pre-training and instruction tuning—one can utilize a connection module and LLM adaptors. The speech audio language music open neural network that is proposed in this study is a single audio-text multimodal LLM that can recognize and comprehend speech, audio events, and music—the three main categories of sounds. SALMONN employs a dual encoder framework, comprising a BEATs audio encoder and a speech encoder from the Whisper speech model, to improve performance on both speech and nonspeech audio applications.
To further enhance Vicuna’s performance, the low-rank adaption strategy is utilized as a cross-modal adaptor to match the augmented input space with the output space. The cross-modal pre-training and instruction tuning phases of the window-level Q-Former and LoRA employ many speech, audio, and music challenges. The resultant multimodal LLMs show little to no cross-modal emergent skills and can be restricted to the specific kinds of tasks utilized in instruction tuning, specifically audio captioning and voice recognition, which they term the task over-fitting problem. The ability to execute cross-modal tasks that are not noticed during training is referred to in this study as cross-modal emergent skills. These abilities are basically the emergent capabilities of LLMs that are lost during instruction tailoring.
In order to mitigate the significant catastrophic forgetting of the training tasks, they suggest adding an additional few-shot activation tuning stage to SALMONN’s repertoire. SALMONN’s cognitive hearing abilities are assessed using a variety of speech, auditory events, and music standards. There are three levels to the tasks. The first two levels test untrained activities, while the first level benchmarks eight tasks that are taught in instruction tuning, including audio captioning, translation, and voice recognition. Five speech-based natural language processing (NLP) tasks, including slot filling and translation to untrained languages, are included in the second level. These tasks need multilingual and high-quality alignments between voice and text tokens.
Comprehending non-speech auditory information is necessary for the last set of activities, such as audio-based narrative and speech audio co-reasoning. The results of the experiments demonstrate that SALMONN can complete all of these tasks and perform competitively on industry benchmarks when used as a single model. This suggests that it is possible to create artificial intelligence that is capable of “hearing” and comprehending a wide variety of audio inputs, including speech, audio events, and music.
This paper’s primary contribution may be summed up as follows.
• To the best of their knowledge, researchers from Tsinghua University and ByteDance offer SALMONN, the first multimodal LLM that can recognize and comprehend general audio inputs including voice, audio events, and music.
• By varying the LoRA scaling factor, they investigate the existence of cross-modal emergent skills. They then suggest a low-cost activation tuning technique as an additional training step that can activate these abilities and reduce catastrophic forgetting to tasks encountered during training.
• They provide two new tasks, audio-based storytelling and spoken audio co-reasoning, and assess SALMONN on a variety of tasks that represent a range of general hearing skills.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.