Enhancing Factuality in AI: This AI Research Introduces Self-RAG for More Accurate and Reflective Language Models
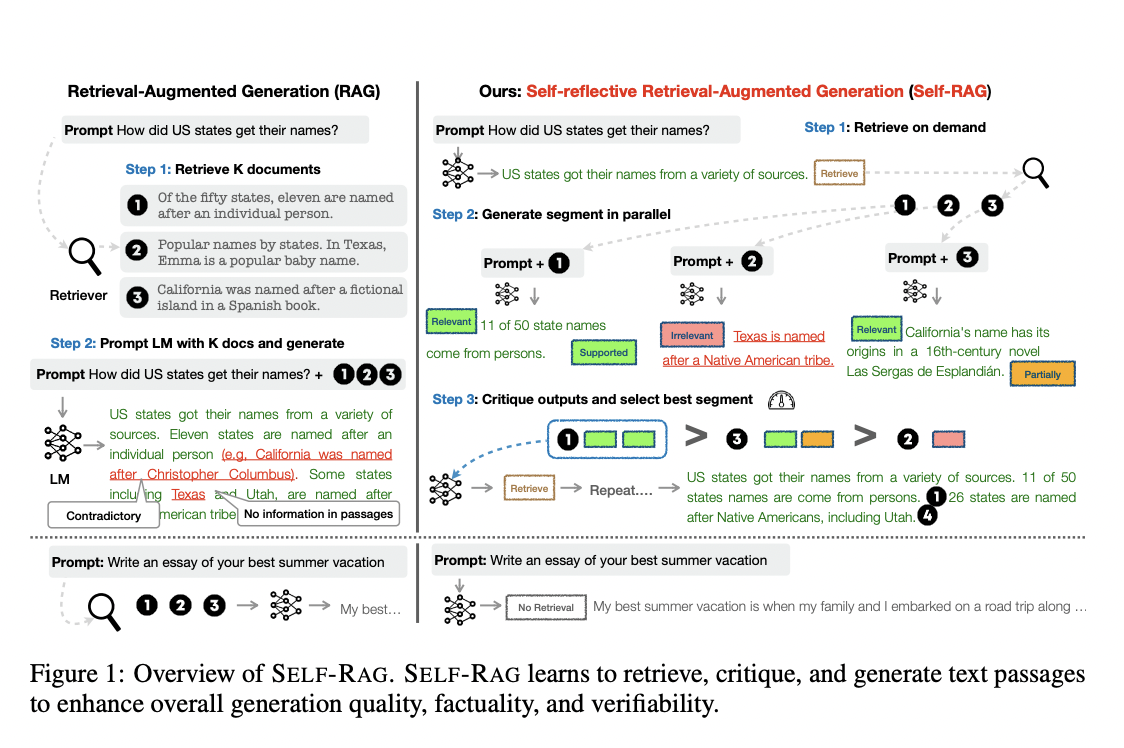
Self-Reflective Retrieval-Augmented Generation (SELF-RAG) is a framework that enhances large language models (LLMs) by dynamically retrieving relevant information and reflecting on its generations. This approach significantly improves LLMs’ quality, factuality, and performance on various tasks, outperforming LLMs like ChatGPT and retrieval-augmented models like Llama2-chat. SELF-RAG is particularly effective in open-domain question-answering, reasoning, fact verification, and long-form content generation tasks.
Researchers from the University of Washington, Allen Institute for AI, and IBM Research AI introduced SELF-RAG, which enhances LLMs by dynamically retrieving relevant passages on-demand and reflecting on their generated content. Their approach addresses factual inaccuracies found in LLMs and outperforms both LLMs and retrieval-augmented models in diverse tasks, including open-domain question-answering, reasoning, and fact verification. It aims to overcome the limitations of prior methods that could hinder LLM versatility and produce low-quality results.
The challenge of factual errors in state-of-the-art LLMs is addressed by introducing SELF-RAG. SELF-RAG combines retrieval and self-reflection to enhance an LLM’s generation quality without reducing versatility. It trains an LLM to adaptively retrieve passages on demand and reflect on them, achieving significant improvements in generation quality and factual accuracy. Experiments demonstrate SELF-RAG’s superiority over existing LLMs and retrieval-augmented models in various tasks.
SELF-RAG improves language models’ quality and factuality. SELF-RAG trains a single LM to retrieve and reflect on passages, enhancing versatility adaptively. It employs reflection tokens for control during inference, following a three-step process: determining retrieval necessity, processing retrieved passages, and generating critique tokens for output selection. Experiments demonstrate SELF-RAG’s superiority over existing models in tasks like open-domain QA and fact verification.
The SELF-RAG framework has proven highly effective in various tasks, outperforming state-of-the-art LLMs and retrieval-augmented models. It shows significant improvements in factuality and citation accuracy for long-form generations compared to ChatGPT. In human evaluations, SELF-RAG’s outputs are plausible, supported by relevant passages, and consistent with the assessment of reflection tokens. Among non-proprietary LM-based models, SELF-RAG achieves the best performance on all tasks.
The SELF-RAG mechanism offers a viable solution for enhancing the accuracy and quality of Language Model Machines (LLMs) by integrating retrieval and self-reflection tools. Significantly outperforming traditional retrieval-augmented approaches and LLMs containing more parameters, SELF-RAG is more effective across various tasks. This work addresses real-world concerns regarding factual accuracy and misinformation while acknowledging room for improvement. Holistic evaluations utilizing multiple metrics demonstrate SELF-RAG superior to conventional approaches, underscoring its potential for enhancing LLM outputs.
Further research can improve LLMs by enhancing the accuracy of their outputs, especially in addressing real-world challenges related to misinformation and inaccurate advice. Although SELF-RAG has made significant progress, there is room for further refinement. Incorporating explicit self-reflection and fine-grained attribution can help users validate model-generated content. The study also suggests exploring the application of self-reflection and retrieval mechanisms in a broader range of tasks and datasets beyond their current experimental scope.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.