Arch-Net: A Family Of Neural Networks Built With Operators To Bridge The Gap Between Computer Architecture of ASIC Chips And Neural Network Model Architectures

The computation power of Deep Neural Networks is a major challenge to their real-world applications. New developments in the field are outpacing the recent ASICs (Application Specific Integrated Circuit) that have neural network acceleration since ASIC takes several years to develop. One such example is that there is no support from Transformer Networks emerging in Language Modeling and Computer Vision for many chips, so it’s difficult to deploy their solutions.
Researchers from Megvii Inc. in China propose ‘Arch-Net’, a family of Neural Networks built out of a small core set of almost-universally supported hardware operators.’ With the ever-growing workload of supporting every Neural Architecture on every ASIC, Arch-Net can be used to reduce this complexity by using a Blockwise Model Distillation method. This greatly simplifies and diversifies the proposed neural network architecture into one simple family of Arch-Net.
With the help of utilities, Arch-Net can be used to reduce weights and features during distillation. Empirical results show that using Arch-Net between various Neural Architectures and the parade of neural network accelerator ASICs provides an efficient way for machine translation, image classification tasks. Researchers found that by using Layer Normalization and Embedding Layers in Transformers, they could transform them into more mundane Batch Normalization or Fully-Connected layers while maintaining comparable accuracy.
According to the paper, Arch-Net brings great value to both Neural Architecture Designers and Architects of Neural Network Accelerators. Incase of neural architecture designers, Arch-Net makes it possible to entirely ignore the hardware architecture while modifying neural architecture to utilize the inductive bias of data depending on the scenario where neural architecture is distilled into the Arch-Net. While for architects of neural network accelerators, Arch-Net supplies high-level operators contributing to Arch-Net. Having these operators makes the architects ignore neural architectures to some extent and push the ASIC as proof to the next level in front of neural architectures.

Key Takeaways
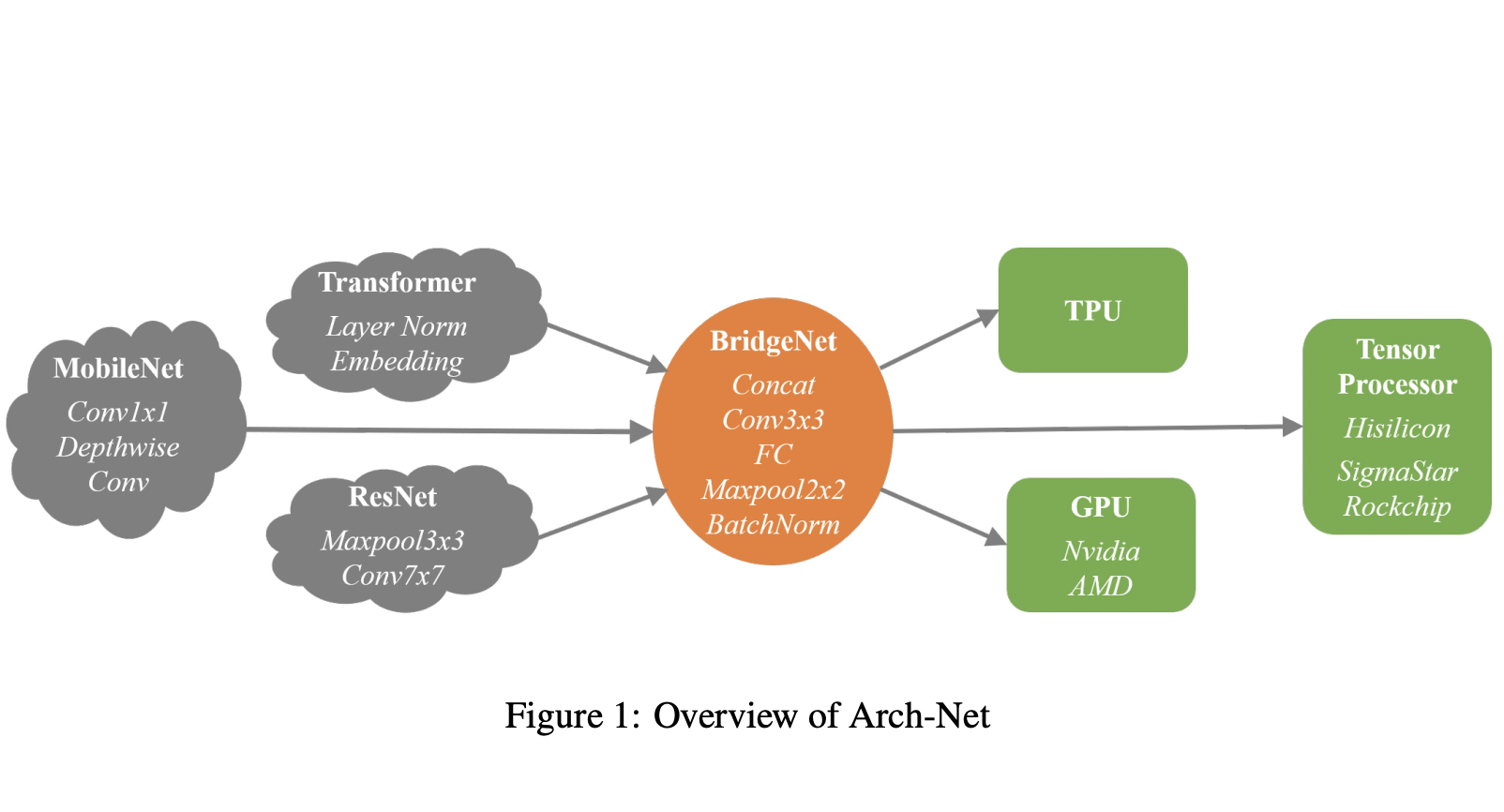
- As it turns out, the Arch-Net is actually building a bridge that translates between computer architectures of ASIC chips and neural network model architectures by changing existing floating-point DNNs into hardware-friendly quantized Arch-Net.
- The structure of ArchNet is made up of five operators: 3×3 Convolutions, Batch Normalization, Concatenation, 2×2 Max-pooling, and Fully-Connected layers.
- The conversion to Arch-Net is much simpler without labeled data as researchers employ Blockwise Model Distillation on feature maps.
- Researchers did extensive experiments on image classification and machine translation tasks to confirm that Arch-Net is both effective, efficient and fast.
We are excited to see how this new Arch-Net architecture will shape the future of computing. We have used information mainly from the paper ‘Arch-Net: Model Distillation for Architecture Agnostic Model Deployment,’ and you can find the URL links to both paper and Github below.
Paper: https://arxiv.org/pdf/2111.01135v1.pdf
Github: https://github.com/megvii-research/Arch-Net
Suggested
Credit: Source link
Comments are closed.