Meet DISC-FinLLM: A Chinese Financial Large Language Model (LLM) Based On Multiple Experts Fine-Tuning
The biggest advancement in the field of Artificial Intelligence is the introduction of Large Language Models (LLMs). These Natural Language Processing (NLP) based models handle large and complicated datasets, which causes them to face a unique challenge in the finance industry. The fields of financial text summarisation, stock price prediction, financial report production, news sentiment analysis, and financial event extraction have all seen advancements in traditional financial NLP models.
As the volume and complexity of financial data keep rising, LLMs encounter a number of challenges, including the lack of human-labeled data, the lack of expertise particular to finance, the difficulty of multitasking, the constraints of numerical computing, and the incapacity to handle real-time information. LLMs like GPT-4 are renowned for their strong dialogue abilities, command comprehension, and capacity for following directions.
However, in industries like the Chinese financial market, LLMs lack an in-depth understanding of the financial industry, which makes the development of open-source Chinese financial LLMs that are suitable for a range of user types and situational settings important. To address the issue, a team of researchers has introduced DISC-FinLLM, a comprehensive approach for creating Chinese financial LLMs.
The main aim of this method is to provide the LLMs with the skill by which they gain the ability to generate and comprehend financial text, have multi-turn conversations about financial issues, and assist financial modeling and knowledge-enhanced systems through plugin functionality. The team has also developed a supervised instruction dataset known as DISC-FIN-SFT. This dataset’s primary categories are as follows.
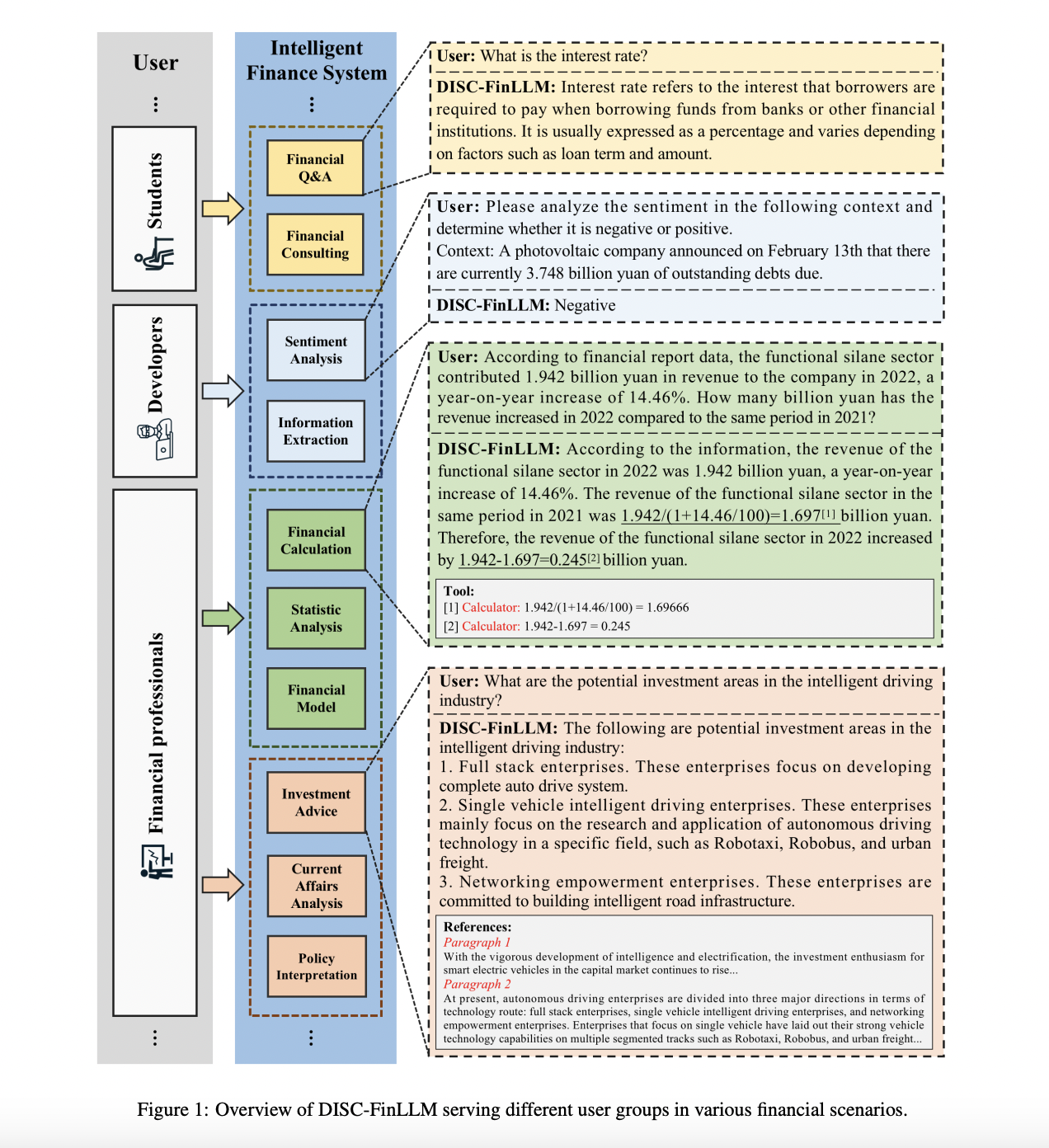
- Financial Consulting Instructions: These instructions have been developed from online financial forums and financial Q&A datasets. They aim to answer inquiries and offer guidance on financial matters.
- Financial Task Instructions: These instructions are meant to help with a variety of financial chores. They are drawn from both self-constructed and available NLP datasets.
- Instructions on Financial Computing: The solutions to financial statistical, computational, and modeling issues are the main subject of these instructions.
- Retrieval- enhanced Instructions: These instructions make knowledge retrieval easier. They have been constructed from financial texts and include created questions, retrieved references, and generated answers.
The team has shared that the DISC-FIN-SFT instruction dataset is the basis for the construction of DISC-FinLLM, which has been built using a Multiple Experts Fine-tuning Framework (MEFF). Four distinct Low-rank adaptation (LoRA) modules have been trained using four different dataset segments. Financial multi-round dialogues, financial NLP jobs, financial computations, and retrieval question responses are just a few of the financial scenarios that these modules are made to accommodate. This enables the system to offer various services to relevant user groups, like students, developers, and financial professionals. In this particular version, the foundation of DISC-FinLLM is Baichuan-13B, a general domain LLM for the Chinese language.
The researchers have conducted multiple assessment benchmarks for evaluating DISC-FinLLM’s. The experimental results have shown that DISC-FinLLM performs better than the base foundation model in all downstream tasks. A closer look reveals the benefits of the MEFF architecture, which makes it possible for the model to perform well in a range of financial scenarios and jobs.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.