This AI Paper Propose AugGPT: A Text Data Augmentation Approach based on ChatGPT
NLP, or Natural Language Processing, is a field of AI focusing on human-computer interaction using language. Text analysis, translation, chatbots, and sentiment analysis are just some of its many applications. NLP aims to make computers understand, interpret, and generate human language.
Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges. While these methods enhance model capabilities through architectural designs and pre-trained language models, data quality and quantity limitations persist.
Additionally, text data augmentation methods have emerged as valuable tools for addressing sample size limitations. These model-agnostic techniques, including synonym replacement and more advanced procedures like back-translation, complement FSL methods in NLP, offering solutions to these challenges.
In the same context, a research team published a new paper introducing a novel data augmentation method called “AugGPT.” This method leverages ChatGPT, a large language model, to generate auxiliary samples for few-shot text classification tasks.
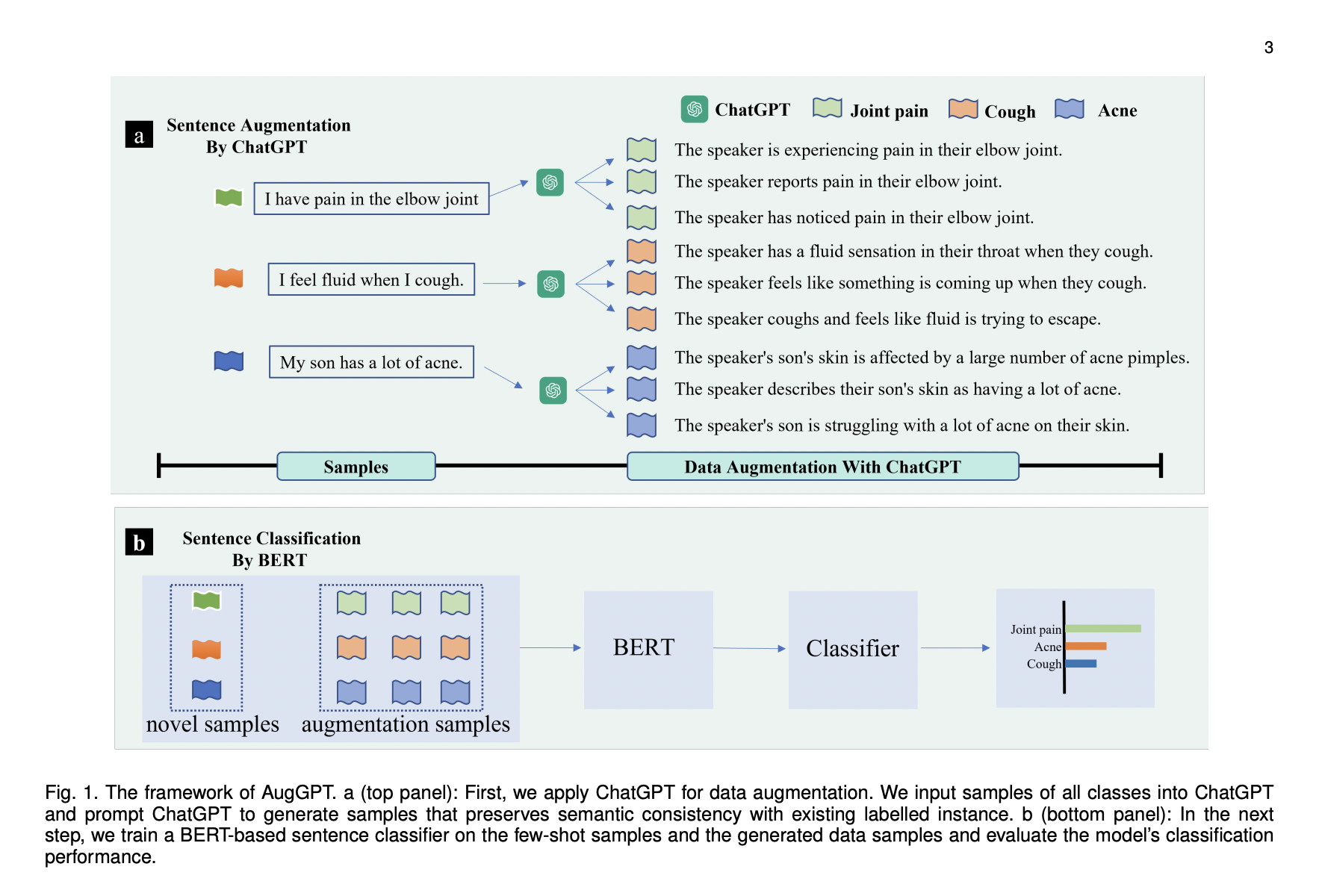
The method addresses the challenge of few-shot learning, where a model trained on a source domain with limited data is expected to generalize to a target domain with only a few examples. The AugGPT method that is being proposed utilizes ChatGPT to generate more samples and improve the training data for text classification.
Concretely, the model is trained with a base dataset (Db) containing a relatively large set of labeled samples and a novel dataset (Dn) with only a few labeled data. The goal is to achieve satisfying generalizability on the novel dataset. AugGPT’s framework consists of fine-tuning BERT on the base dataset, generating augmented data (Daugn) using ChatGPT, and fine-tuning BERT with the augmented data. ChatGPT is employed for data augmentation, rephrasing input sentences into additional sentences to increase few-shot samples. The few-shot text classification model is based on BERT, using cross-entropy and contrastive loss functions to classify samples effectively. AugGPT is compared with other data augmentation methods, including character and word-level substitutions, keyboard simulation, synonym replacement, and more. The method’s prompts are designed for single-turn and multi-turn dialogues, enabling effective data augmentation for various datasets and scenarios.
To summarize, to perform the proposed AugGPT approach for enhancing few-shot text classification, the following steps are taken:
1- Dataset Setup:
- Create a base dataset (Db) with a large set of labeled samples.
- Prepare a novel dataset (Dn) with only a few labeled samples.
2- Fine-tuning BERT:
- Begin by fine-tuning the BERT model on the base dataset (Db) to leverage its pre-trained language understanding capabilities.
3- Data Augmentation with ChatGPT:
- Utilize ChatGPT, a large language model, to generate augmented data (Daugn) for the few-shot text classification task.
- Apply ChatGPT to rephrase input sentences, creating additional sentences to augment the few-shot samples. This process enhances data diversity.
4- Fine-tuning BERT with Augmented Data:
- Fine-tune the BERT model with the augmented data (Daugn) to adapt it for the few-shot classification task.
5- Classification Model Setup:
- Design a few-shot text classification model based on BERT, using the augmented data for training.
The authors conducted experiments using BERT as the base model to evaluate the proposed technique. AugGPT outperformed other data augmentation methods regarding classification accuracy for various datasets. AugGPT also generated high-quality augmented data and improved model performance. When comparing ChatGPT for downstream tasks, it excelled in easier tasks but required model fine-tuning for more complex tasks like PubMed, demonstrating the value of the proposed approach in enhancing performance.
In conclusion, the paper introduced AugGPT, a novel data augmentation method for few-shot classification that operates at the semantic level, resulting in improved data consistency and robustness compared to other methods. It highlights the potential of using large language models, like ChatGPT, in various NLP tasks and suggests fine-tuning these models for domain-specific applications. AugGPT’s success in enhancing classification tasks opens up possibilities for its application in text summarization and computer vision tasks, particularly in generating images from text.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.