This AI Paper Introduces JudgeLM: A Novel Approach for Scalable Evaluation of Large Language Models in Open-Ended Scenarios
Large language models (LLMs) have attracted much attention lately because of their exceptional ability to follow instructions and handle a wide range of open-ended scenarios. Through instruction fine-tuning, researchers offer many techniques to align these models with human preferences based on open-source LLMs, such as FlanT5, OPT, LLaMA, and Pythia. These aligned LLMs show improved comprehension of human commands and produce more logical replies. However, the capabilities of LLMs in open-ended scenarios need to be sufficiently estimated by current benchmarks and conventional measurements.
Consequently, there is a need for a new benchmark approach that might assess LLMs thoroughly in open-ended activities. Simultaneous studies are attempting to investigate different methods for determining LLM performance. The arena-format techniques get anonymized LLM competition outcomes by utilizing crowdsourcing platforms. Human evaluations are reliable, but they also cost money and require much effort. Some methods use the GPT-4 as the adjudicator. However, these approaches need help with variable API model shifts and possible data disclosure, which might jeopardize the judge’s repeatability. PandaLM makes an effort to improve open-source LLMs used for answer evaluation.

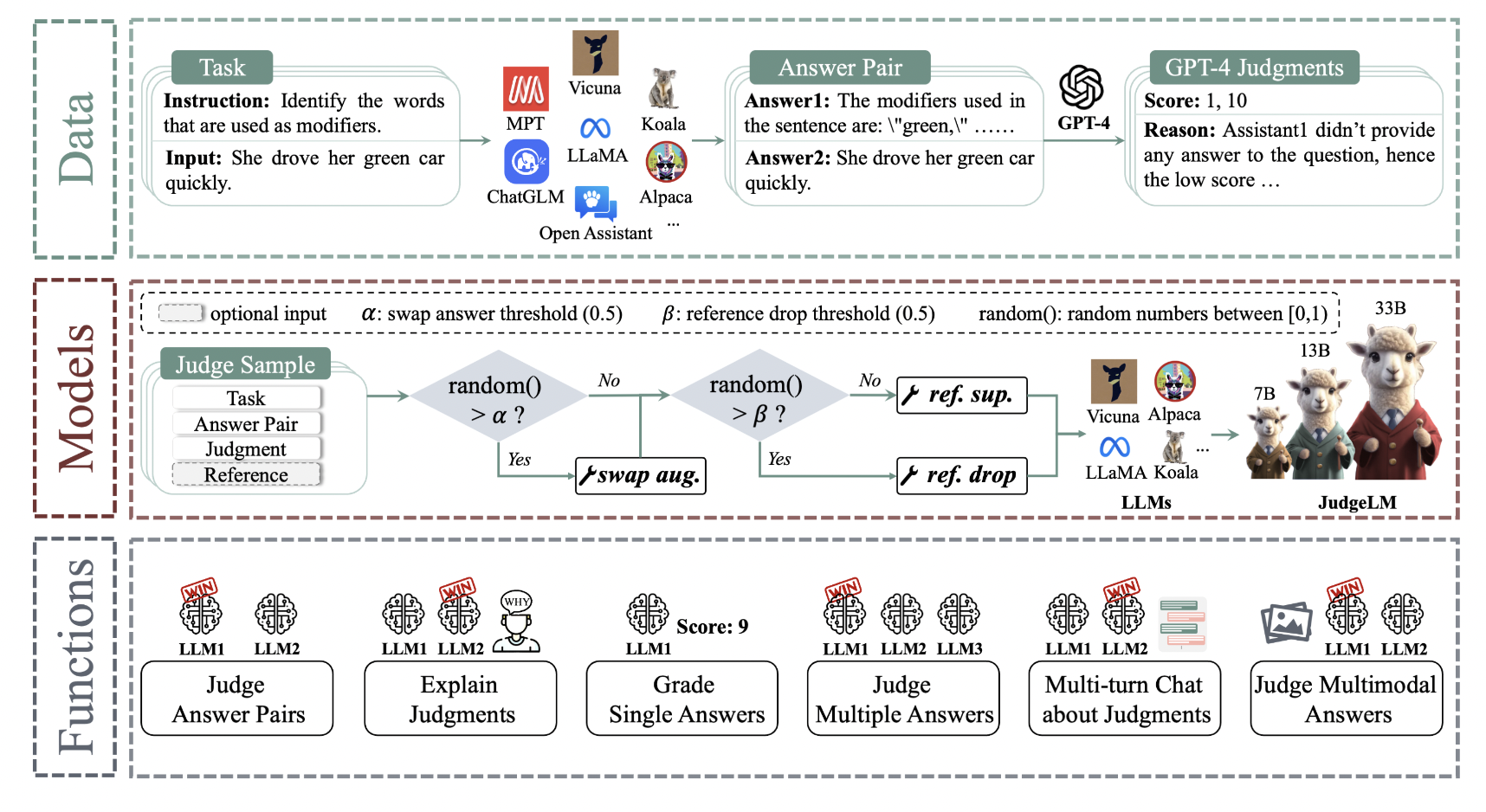
Figure 1(a): JudgeLM’s data generating pipeline. 105K seed tasks are initially gathered as questions. After that they take the answers out of the 11 LLMs and choose two at random from the answer set. Lastly, enter the tasks, sample answer pairs, and, if desired, the responses to the GPT-4. This produces scores and thorough justifications for the judge instructor.
Nevertheless, the usefulness of such refined models in the judicial position is weakened by constraints arising from the model’s size, training data quality, and intrinsic LLM biases. Researchers from Beijing Academy of Artificial Intelligence and Huazhong University of Science & Technology suggest evaluating LLMs in this study using optimized open-source LLMs that operate as scalable judges (JudgeLM) that reach a good enough agreement with the instructor judge. Their technique combines a high-quality dataset useful for training and assessing the judge models with scalable judges acting as evaluators in open-ended assignments. They modify open-source LLMs to serve as judges inside their framework and examine how well they scale concerning model size (7B to 33B) and training data volume (3.5K to 100K).

Figure 1(b): An example of the different features and fine-tuning of the JudgeLM. To improve LLMs’ performance as scalable judges, they employ produced judge samples. They also suggest reference drop, reference support, and swap augmentation for fine-tuning LLMs as judges in order to overcome format, knowledge, and position biases, respectively.
As seen in Fig. 1a, their curated dataset consists of 105K seed questions, LLM answer pairs, and teacher judge, GPT-4, judgments. Note that for every seed challenge, students produced two decisions—one with reference answers and the other without. The partitioning of this dataset involves setting aside 100K seed questions for training (×2 bigger than PandaLM) and setting aside the remaining questions for validation (×29 larger than PandaLM). Biases including position bias (favouring responses in particular situations), knowledge bias (over-reliance on pre-trained information), and format bias (optimal performance only under specific prompt forms) are invariably introduced when LLMs are used as judges.
They provide ways to deal with them. Additionally, as seen in Fig. 1b, their JudgeLM system has expanded features, such as multi-turn conversation, grading single replies, and judging multiple answers in addition to multimodal models. Compared to arena-format approaches, theirs is a quick and inexpensive solution. For example, JudgeLM-7B is a model that can assess 5000 response pairs in 3 minutes and only needs 8 A100 GPUs. JudgeLM offers more privacy protection and repeatability than closed-source LLM judges. Their method investigates the scaling capabilities and biases in LLM fine-tuning compared to concurrent open-source LLM judges.
Moreover, the dataset they present is the most comprehensive and superior, which will greatly aid future studies in judging model analysis. The following succinctly describes their primary contributions:
• They propose JudgeLM, a scalable language model judge designed for evaluating LLMs in open-ended scenarios.
• They introduce a high-quality, large-scale dataset for judge models, enriched with diverse seed tasks, LLMs-generated answers, and detailed judgments from GPT-4, laying the groundwork for future research on evaluating LLMs. It exceeds human-to-human agreement with an agreement of above 90%. Additionally, its JudgeLM has extensive capabilities to handle lengthy jobs.
• They examine the biases present in LLM, judge fine-tuning, and present several solutions. Their techniques greatly increase the model’s consistency over various scenarios, increasing the JudgeLM’s dependability and adaptability.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.