This AI Research from China Introduces Consistent4D: A Novel Artificial Intelligence Approach for Generating 4D Dynamic Objects from Uncalibrated Monocular Videos
The realm of computer vision grapples with a foundational yet arduous task: deciphering dynamic 3D data from visual inputs. This capability is pivotal for a spectrum of applications spanning digital content production, the simulation of autonomous vehicles, and the analysis of medical images. However, gleaning such information from a solitary monocular video observation presents a formidable challenge due to the intricate nature of dynamic 3D signals.
Most existing methodologies for reconstructing moving objects necessitate either synchronized multi-view footage as inputs or rely on training data enriched with effective multi-view cues, employing methods like teleporting cameras or quasi-static scenes. Nevertheless, these approaches encounter difficulties in accurately reconstructing elements of the scene that evade capture by the camera lens. Furthermore, the dependence on synchronized camera setups and precise calibrations curtails the practical applicability of these methods in real-world scenarios.
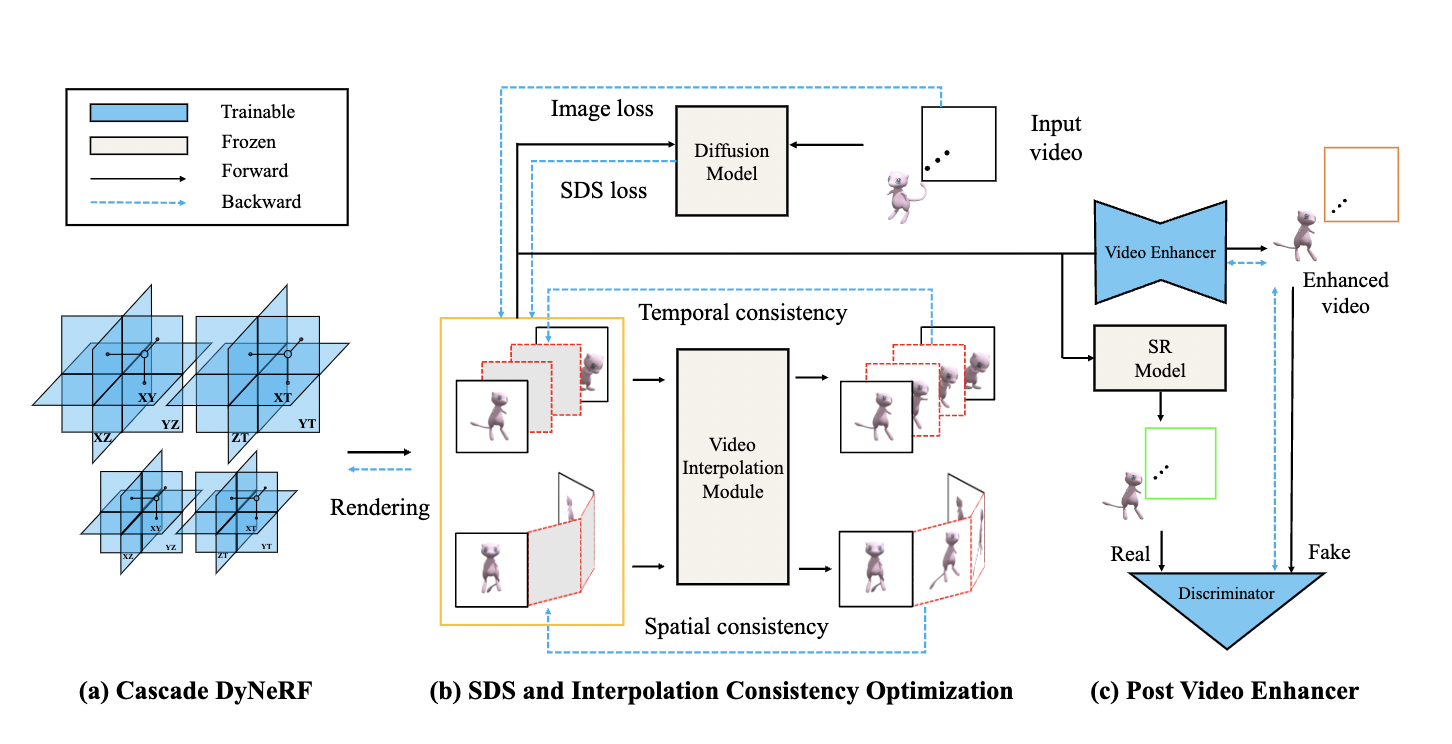
A new study by CASIA, Nanjing University, and Fudan University introduces Consistent 4D, a novel method designed to generate 4D content from 2D sources. Drawing inspiration from recent advancements in text-to-3D and image-to-3D techniques, this approach visualizes moving objects through a tailored Cascade DyNeRF while leveraging a pre-trained 2D diffusion model to govern the DyNeRF optimization process.
As mentioned in their paper, the primary challenge lies in preserving both temporal and spatial coherence. To address this challenge, the researchers made use of an Interpolation-driven Consistency Loss (ICL), which resolves the issue by relying on a pre-trained video interpolation model. This enables the generation of consistent supervision signals across both space and time. Notably, implementing the ICL loss not only enhances reliability in 4D development but also mitigates the issues commonly associated with multiple facets in 3D creation. Additionally, they undertake training in a streamlined video enhancer to post-process the dynamic NeRF-generated video.
Encouraging results stemming from our extensive testing, encompassing both synthetic and real-world Internet videos, signify a promising stride forward in the uncharted territory of video-to-4D creation.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.