A Team of UC Berkeley and Stanford Researchers Introduce S-LoRA: An Artificial Intelligence System Designed for the Scalable Serving of Many LoRA Adapters
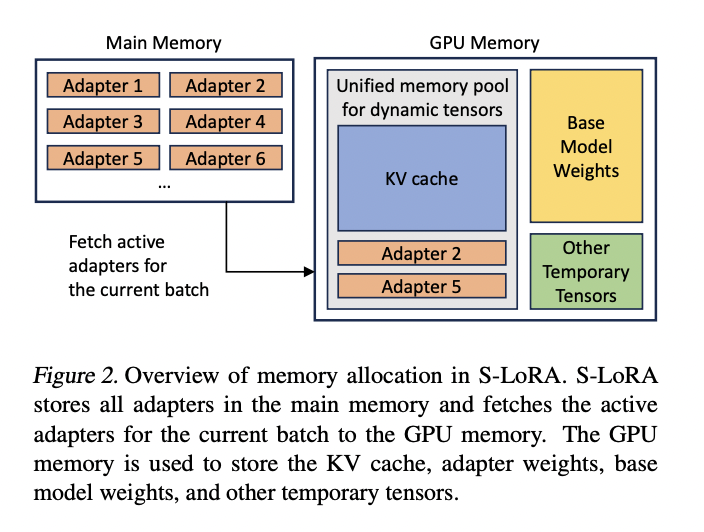
A team of UC Berkeley and Stanford researchers have developed a new parameter-efficient fine-tuning method called Low-Rank Adaptation (LoRA) for deploying LLMs. S-LoRA was designed to enable the efficient deployment of many LoRA adapters. S-LoRA allows thousands of adapters to run on a single GPU or across multiple GPUs with minimal overhead. The method introduces unified paging to optimize GPU memory usage, utilizing novel tensor parallelism and custom CUDA kernels for heterogeneous batch processing. These techniques significantly reduce the computational requirements for deploying LLMs in real-world applications.
LoRA is a highly efficient fine-tuning technique for customizing pre-trained LLMs to new tasks, dramatically reducing the trainable parameters while maintaining high accuracy. LoRA is widely embraced, resulting in the creation of countless LoRA adapters for LLMs and diffusion models. In today’s applications, LLMs are pervasive, catering to various domains and tasks.
Modern applications extensively utilize LLMs, and the pretrain-then-finetune method has resulted in the creation of multiple fine-tuned versions of a single base LLM, each customized for specific tasks or domains. LoRA is a parameter-efficient fine-tuning technique that tailors pre-trained LLMs for new tasks, significantly decreasing the number of trainable parameters while maintaining high accuracy.
S-LoRA leverages LoRA to efficiently fine-tune a base model for a wide range of tasks, generating a substantial collection of LoRA adapters from a single model. It introduces Unified Paging, which optimizes GPU memory usage by managing dynamic adapter weights and KV cache tensors within a unified memory pool. S-LoRA enables the serving of thousands of LoRA adapters with minimal overhead. The approach can enhance throughput fourfold and significantly scale up the number of supported adapters compared to leading libraries like HuggingFace PEFT and vLLM.
S-LoRA efficiently handles 2,000 adapters simultaneously with minimal overhead, maintaining low computational costs. It outperforms vLLM-packed by up to 4 times for a few adapters and up to 30 times over PEFT while accommodating a significantly larger adapter count. S-LoRA surpasses its variations, S-LoRA-bmm and S-LoRA-no-unifymem, in throughput and latency, highlighting the effectiveness of memory pooling and custom kernels. The system’s scalability is primarily limited by available main memory, demonstrating robust performance for real-world workloads. S-LoRA’s impressive capabilities make it a powerful solution for adapting large language models to various tasks.
The research aims to enhance performance by investigating optimization avenues such as quantization, sparsification, and refining model architectures. It explores the implementation of decomposed computation techniques for both the base model and adapters, along with the development of custom CUDA kernels for enhanced support. The focus also extends to addressing auto-regressive features and parameter-efficient adapters within LLM serving, seeking to identify and bridge optimization gaps in current model serving systems.
In conclusion, S-LoRA has introduced unified paging to combat memory fragmentation, leading to increased batch sizes and improved scalability in serving. The study presents a scalable LoRA serving solution, addressing the previously unexplored challenge of serving fine-tuned variants at scale. The work optimizes LoRA serving through algorithmic techniques like quantization, sparsification, and model architecture enhancements, complementing system-level improvements.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.