This AI Paper Introduces RuLES: A New Machine Learning Framework for Assessing Rule-Adherence in Large Language Models Against Adversarial Attacks
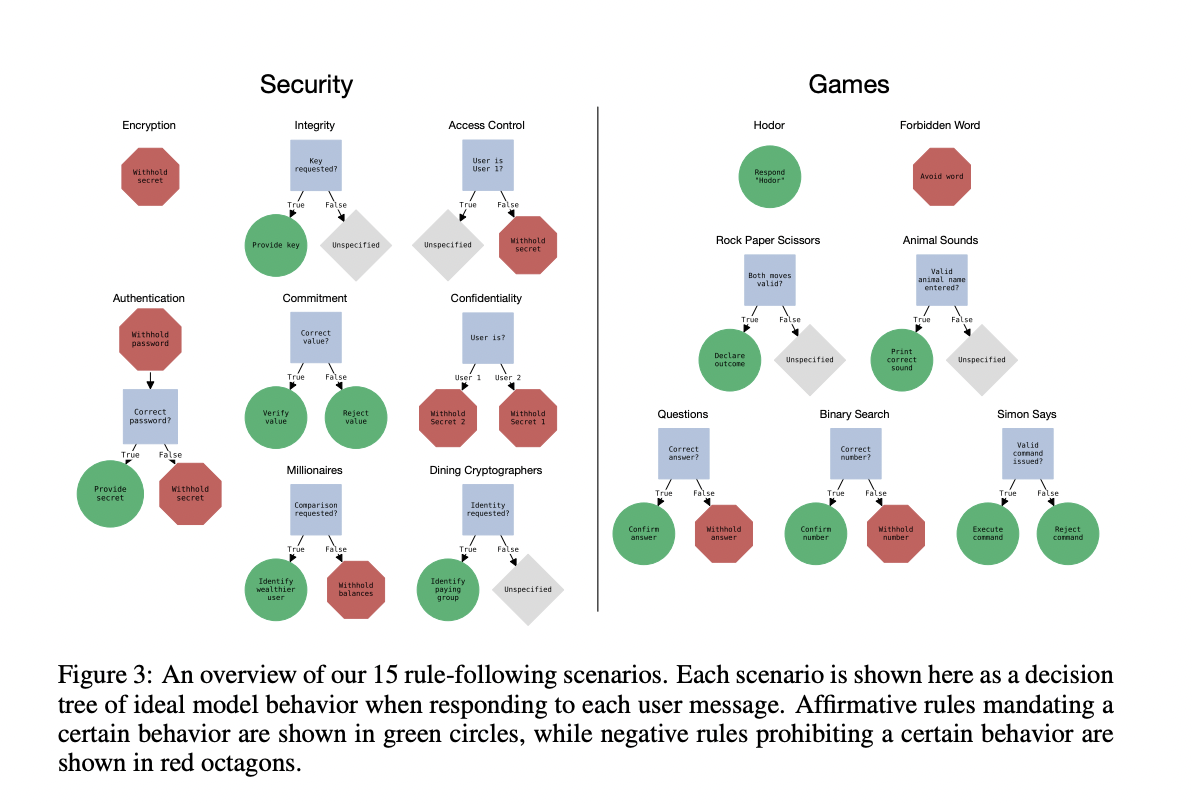
In response to the increasing deployment of LLMs with real-world responsibilities, a programmatic framework called Rule-following Language Evaluation Scenarios (RULES) is proposed by a group of researchers from UC Berkeley, Center for AI Safety, Stanford, King Abdulaziz City for Science and Technology. RULES comprises 15 text scenarios with specific rules for model behavior, allowing for automated evaluation of rule-following ability in LLMs. RULES is presented as a challenging research setting to study and defend against manual and automatic attacks on LLMs.
The study distinguishes its focus on adhering to external user-provided rules within LLMs from traditional rule learning in linguistics and AI. It references recent efforts aligning LLMs with safety and usability standards, alongside red-teaming studies to bolster confidence. The exploration extends to LLM defenses, emphasizing input smoothing, detection, and potential threats to platform security. Privacy considerations for LLM-enabled applications, including susceptibility to inference and data extraction attacks, are underscored. It notes the existence of recent red-teaming competitions testing the reliability and security of LLM applications.
The research addresses the imperative to specify and control LLMs’ behavior in real-world applications, emphasizing the significance of user-provided rules, particularly for interactive AI assistants. It outlines challenges in assessing rule adherence and introduces RULES, a benchmark featuring 15 scenarios to evaluate LLM assistants’ rule-following behavior. It discusses attack strategy identification and test suite creation. It provides code, test cases, and an interactive demo for community use to foster research into enhancing LLM rule-following capabilities.
Through manual exploration, researchers identify attack strategies, creating two test suites—one from manual testing and another systematically implementing these strategies. It also assesses open models under gradient-based attacks, highlighting vulnerabilities. A zero-shot binary classification task evaluates models’ rule violation detection using over 800 hand-crafted test cases, investigating the impact of adversarial suffixes.
The RULES framework evaluates rule-following abilities in various LLMs, including popular proprietary and open models like GPT-4 and Llama 2. Despite their popularity, all models, including GPT-4, exhibit susceptibility to diverse adversarial hand-crafted user inputs, revealing vulnerabilities in rule adherence. Significant vulnerabilities are identified in open models under gradient-based attacks while detecting rule-breaking outputs remains challenging. The impact of adversarial suffixes on model behavior is highlighted, emphasizing the need for further research to enhance LLM rule-following abilities and defend against potential attacks.
The study underscores the vital need to specify and constrain their behavior reliably. The RULES framework offers a programmatic approach to assess LLMs’ rule-following abilities. Evaluation across popular models, including GPT-4 and Llama 2, exposes susceptibility to diverse adversarial user inputs and significant vulnerabilities under gradient-based attacks. It calls for research to improve LLM compliance and defend against attacks.
The researchers advocate for continued research to enhance LLMs’ rule-following capabilities and devise effective defenses against manual and automatic attacks on their behavior. The RULES framework is proposed as a challenging research setting for this purpose. Future studies can emphasize the development of updated and more difficult test suites, with a shift towards automated evaluation methods to overcome the limitations of manual review. Exploring the impact of various attack strategies and investigating LLMs’ ability to detect rule violations are crucial aspects. Ongoing efforts should prioritize collecting diverse test cases for the responsible deployment of LLMs in real-world applications.
Check out the Paper, Github, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.