This AI Research from Adobe Proposes a Large Reconstruction Model (LRM) that Predicts the 3D Model of an Object from a Single Input Image within 5 Seconds
Many researchers have envisioned a world where any 2D image can be instantaneously converted into a 3D model. Research in this area has been mostly motivated by the desire to find a generic and efficient method of achieving this long-standing objective, with potential applications spanning industrial design, animation, gaming, and augmented reality/virtual reality.
Early learning-based approaches typically perform well on certain categories, using the category data before inferring the overall shape because of the inherent ambiguity of 3D geometry in a single glance. Recent studies have been motivated by recent developments in image generation, such as DALL-E and Stable Diffusion, to take advantage of the amazing generalization potential of 2D diffusion models to enable multi-view supervision. However, Many of these approaches necessitate careful parameter adjustment and regularization, and their output is constrained by the pre-trained 2D generative models used in the first place.
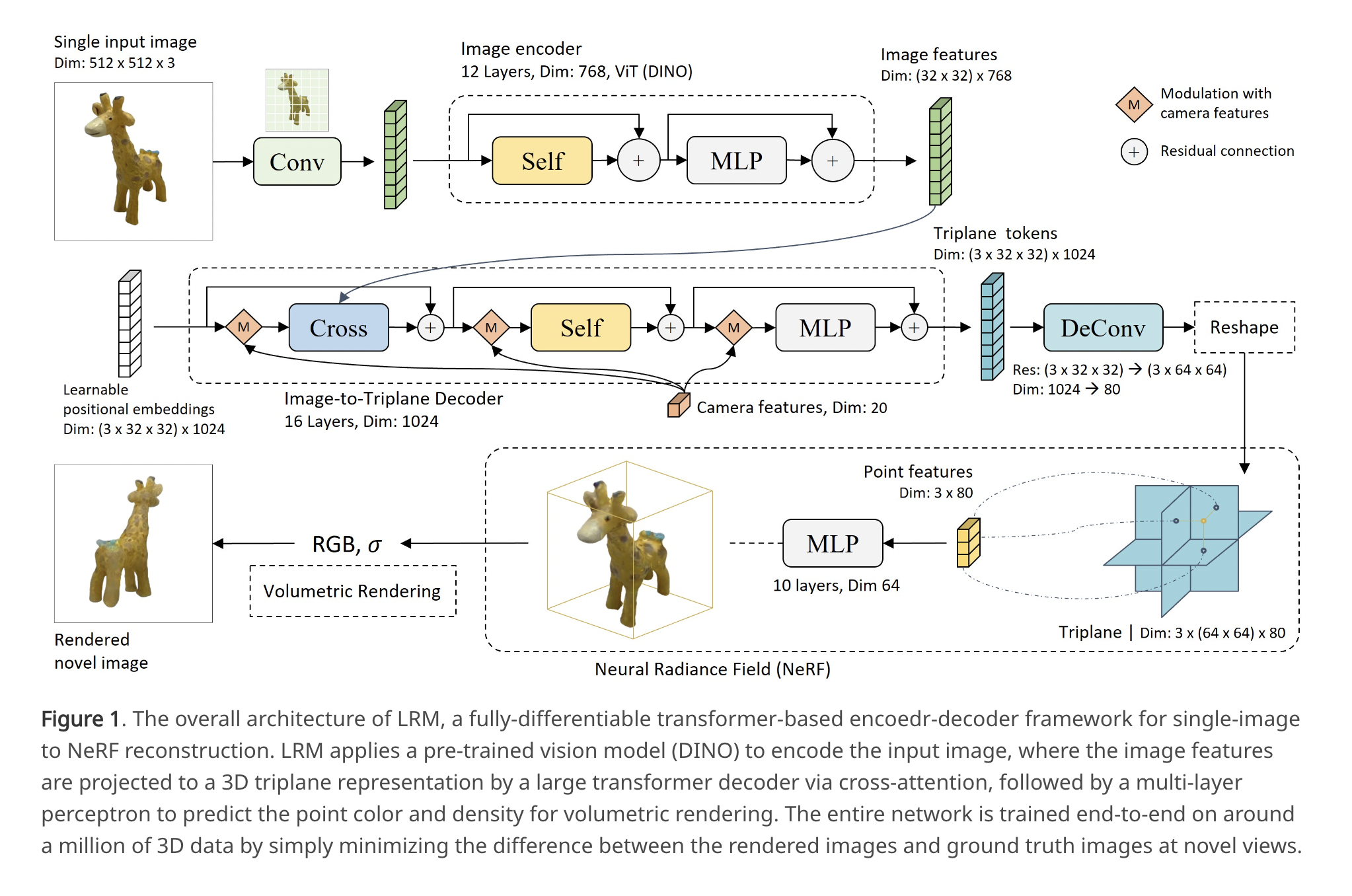
Using a Large Reconstruction Model (LRM), researchers from Adobe Research and the Australian National University could convert a single image into 3D. The proposed model uses a massive transformer-based encoder-decoder architecture for data-driven 3D object representation learning from a single image. When an image is fed into their system, it outputs a triplane representation of a NeRF. Specifically, LRM generates image features using the pre-trained visual transformer DINO as the image encoder, and then learns an image-to-triplane transformer decoder to project the 2D image cross-attentionally features onto the 3D triplane, and then self-attentively models the relations among the spatially-structured triplane tokens. The output tokens from the decoder are reshaped and upsampled to the final triplane feature maps. After that, they may decode the triplane characteristic of each point with an additional shared multi-layer perception (MLP) to obtain its color and density and carry out volume rendering, allowing us to generate the images from any arbitrary viewpoint.
LRM is highly scalable and efficient due to its well-designed architecture. Triplane NeRFs are computationally friendly compared to other representations like volumes and point clouds, making them a simple and scalable 3D representation. In addition, its proximity to the picture input is superior to that of Shap-E’s tokenization of the NeRF’s model weights. Furthermore, the LRM is trained by simply minimizing the difference between the rendered images and ground truth images at novel views, without excessive 3D-aware regularization or delicate hyper-parameter tuning, making the model very efficient in training and adaptable to a wide variety of multi-view image datasets.
LRM is the first large-scale 3D reconstruction model, with over 500 million learnable parameters and training data consisting of approximately one million 3D shapes and videos from a wide variety of categories; this is a significant increase in size over more recent methods, which make use of relatively shallower networks and smaller datasets. The experimental results demonstrate that LRM can rebuild high-fidelity 3D shapes from real-world and generative model photos. Additionally, LRM is a very useful tool for downsizing.
The team plans to focus on the following areas for their future study:
- Increase the model’s size and training data using the simplest transformer-based design possible with little regularization.
- Extend it to multi-modal generative models in 3D.
Some of the work done by 3D designers might be automated with the help of image-to-3D reconstruction models like LRM. It’s also important to note that these technologies can potentially increase growth and accessibility in the creative sector.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.