Researchers from the University of Washington and Duke University Introduce Punica: An Artificial Intelligence System to Serve Multiple LoRA Models in a Shared GPU Cluster
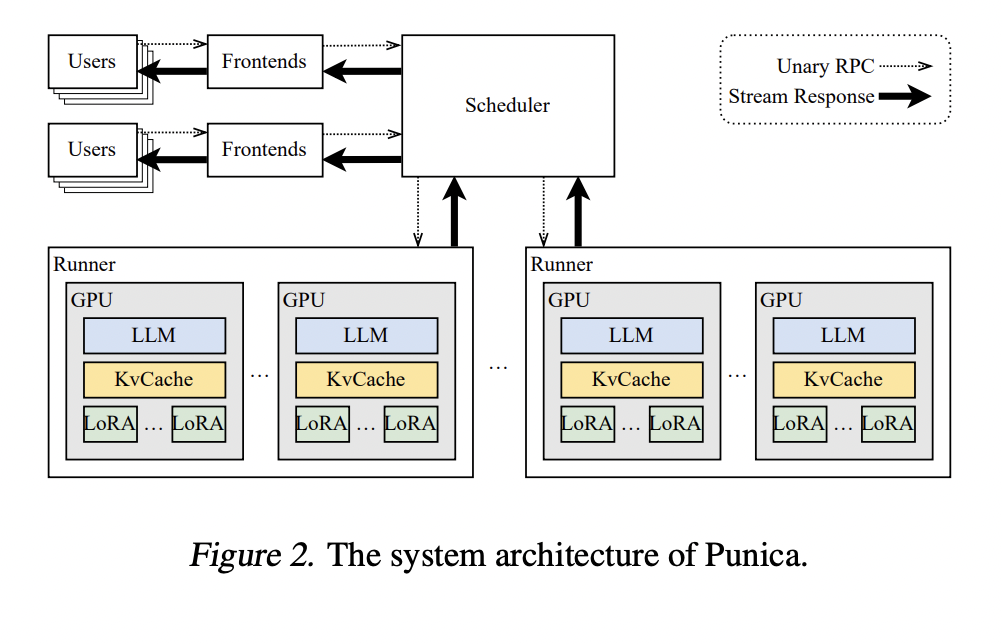
To specialize in pre-trained large language models (LLMs) for domain-specific tasks with minimum training data, low-rank adaptation, or LoRA, is gaining popularity. Tenants may train various LoRA models at a minimal cost since LoRA greatly reduces the number of trainable parameters by keeping the pre-trained model’s weights and adding trainable rank decomposition matrices to each layer of the Transformer architecture. LoRA is now a part of several widely used fine-tuning frameworks. To meet the demands of its tenants, ML providers must thus concurrently offer many specific LoRA models. GPU resources are wasted by merely providing LoRA models as though they were individually trained.
If k GPUs are required for every LoRA model, then k × n GPUs would appear to be needed to support n separate LoRA models. This simple method ignores the possibility of weight correlations between these LoRA models because they come from the same pre-trained models. They contend that an effective system that supports several distinct LoRA models must adhere to three design principles. Since (G1) GPUs are costly and in short supply, multi-tenant LoRA serving workloads must be concentrated onto a small number of GPUs to maximize GPU usage. (G2) Batching is one of the best, if not the best, ways to combine ML workloads to increase performance and GPU usage, as previous studies have noted. But they are batching only functions in cases where requests are made for identical models. As a result, they must allow batching for various LoRA models. (G3) Most model serving costs are attributed to the decode stage. So, all they have to concentrate on is the amazing stage performance. They can use simple methods, such as on-demand loading of LoRA model weights, for other less crucial components of the model serving. Based on these three criteria, researchers from the University of Washington and Duke University developed and built Punica, a multi-tenant serving framework for LoRA models on a shared GPU cluster. Segmented Gather Matrix-Vector Multiplication (SGMV), a new CUDA kernel, is one of the main innovations.
Batching GPU operations for the simultaneous execution of several distinct LoRA models is made possible by SGMV. By reducing the number of copies of the pre-trained model that a GPU must keep in memory, SGMV dramatically increases GPU efficiency in both memory and computation. They combine several cutting-edge methods for system optimization with this new CUDA kernel. Surprisingly, they find very few performance differences when batching the same LoRA models versus batching different LoRA models. SGMV permits batching requests from several LoRA models. Simultaneously, the delay of the LoRA model on-demand loading is mere milliseconds.
Punica may now condense user requests to a smaller group of GPUs without being limited by the LoRA models currently executing on the GPUs. Punica uses the following two methods to arrange tasks for several tenants. Punica directs a fresh request to a select group of GPUs currently in use, ensuring they are utilized to their maximum potential. Punica will only commit further GPU resources once the current GPUs are completely used. Punica moves active requests for consolidation regularly. This makes it possible to release GPU resources that Punica has been assigned. On NVIDIA A100 GPU clusters, they assess LoRA models derived from the Llama2 7B, 13B, and 70B models.
Punica adds a 2ms delay per token and delivers 12x greater throughput than state-of-the-art LLM serving solutions with the same GPU resources. The following are the contributions made by this paper:
• They recognize the potential for batch-processing requests from various LoRA models.
• They create and put into practice a CUDA kernel that is effective for running many LoRA models at once. • They provide innovative scheduling techniques to combine tasks from many tenants in LoRA.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.