Amazon Researchers Propose KD-Boost: A Novel Knowledge Distillation Algorithm Designed for Real-Time Semantic Matching
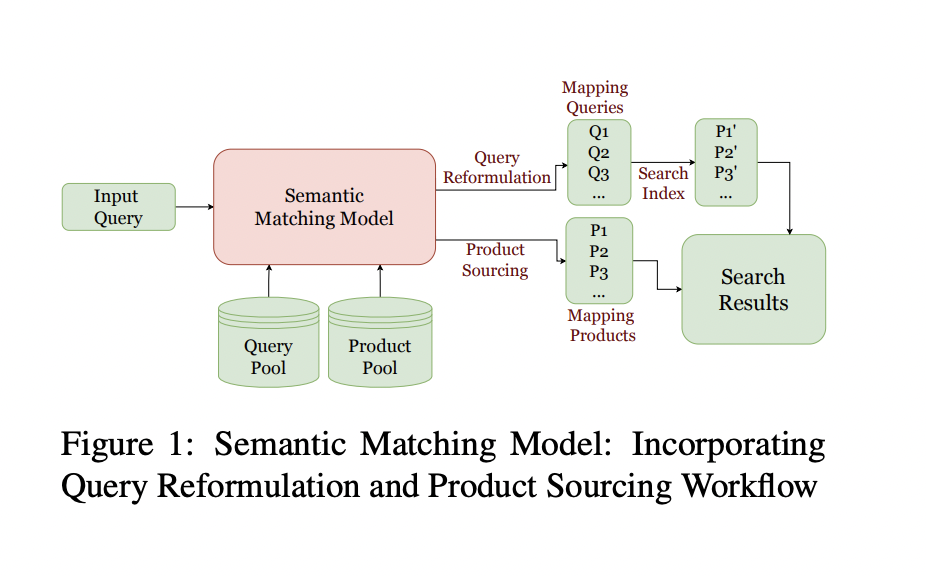
Web search and e-commerce product search are two primary applications that depend on accurate real-time semantic matching. In product searches, the difficulty is in bridging the semantic gap between user queries and the associated results. The matching procedure generally consists of two steps: Product Sourcing (PS) and Automated Query Reformulation. Product sourcing retrieves matching results for a given query, which are often referred to as products in the context of product search. Following that, Automated Query Reformulation converts poorly formulated user queries into semantically similar, well-formulated queries to broaden result coverage.
Semantic matching is the process by which search engines recognize and associate items with comparable meanings. With semantic matching, user queries return not just any results but the most relevant ones given the context. Transformer-based models have been shown to be very successful at encoding requests and clustering them together in an embedding space with semantically related elements such as queries or results. However, latency problems make big transformer models impractical for real-time matching due to their computational cost.
To address these challenges, a team of researchers from Amazon has introduced KD-Boost, a new knowledge distillation technique that has been specifically tailored to tackle real-time semantic matching problems. KD-Boost uses ground truth and soft labels from a teacher model to train low-latency, accurate student models. Pairwise query-product and query-query signals, produced by direct audits, user behavior research, and taxonomy-based data, are the source of the soft labels. Custom loss functions have been used to direct the learning process properly.
The researchers have shared that the study has used a variety of sources of similarity and dissimilarity signals to meet the combined needs of query reformulation and product sourcing. Editorial ordinal relevance labels for query-product pairs, user-behavioral information like clicks and sales, and product taxonomy are some examples of these signals. To make sure the model learns representations that can accurately capture the subtleties of relevance and similarity, tailored loss functions have been used.
The team has shared that tests have been carried out on internal and external e-commerce datasets, which have demonstrated a significant enhancement of 2-3% in ROC-AUC (Receiver Operating Characteristic – Area Under the Curve) in contrast to student model direct training. KD-Boost demonstrated better performance than both the state-of-the-art knowledge distillation benchmarks and teacher models.
Promising outcomes have been observed in simulated online A/B tests using KD-Boost for automated Query Reformulation. Query-to-query matching increased by 6.31%, suggesting improved semantic understanding. There was also a 2.19% improvement in relevance, showing more precise and contextually relevant matches, and a 2.76% rise in product coverage, indicating a wider range of relevant results.
In conclusion, this study has addressed the latency issues associated with extensive product searches, emphasizing the enhancement of both Product Sourcing and Automated Query Reformulation activities. It has acknowledged the shortcomings of the current transformer-based models and has helped study the use of knowledge distillation as a solution.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.