UC Berkeley Researchers Propose an Artificial Intelligence Algorithm that Achieves Zero-Shot Acquisition of Goal-Directed Dialogue Agents
Large Language Models (LLMs) have shown great capabilities in various natural language tasks such as text summarization, question answering, generating code, etc., emerging as a powerful solution to many real-world problems. One area where these models struggle, though, is goal-directed conversations where they have to accomplish a goal through conversing, for example, acting as an effective travel agent to provide tailored travel plans. In practice, they generally provide verbose and non-personalized responses.
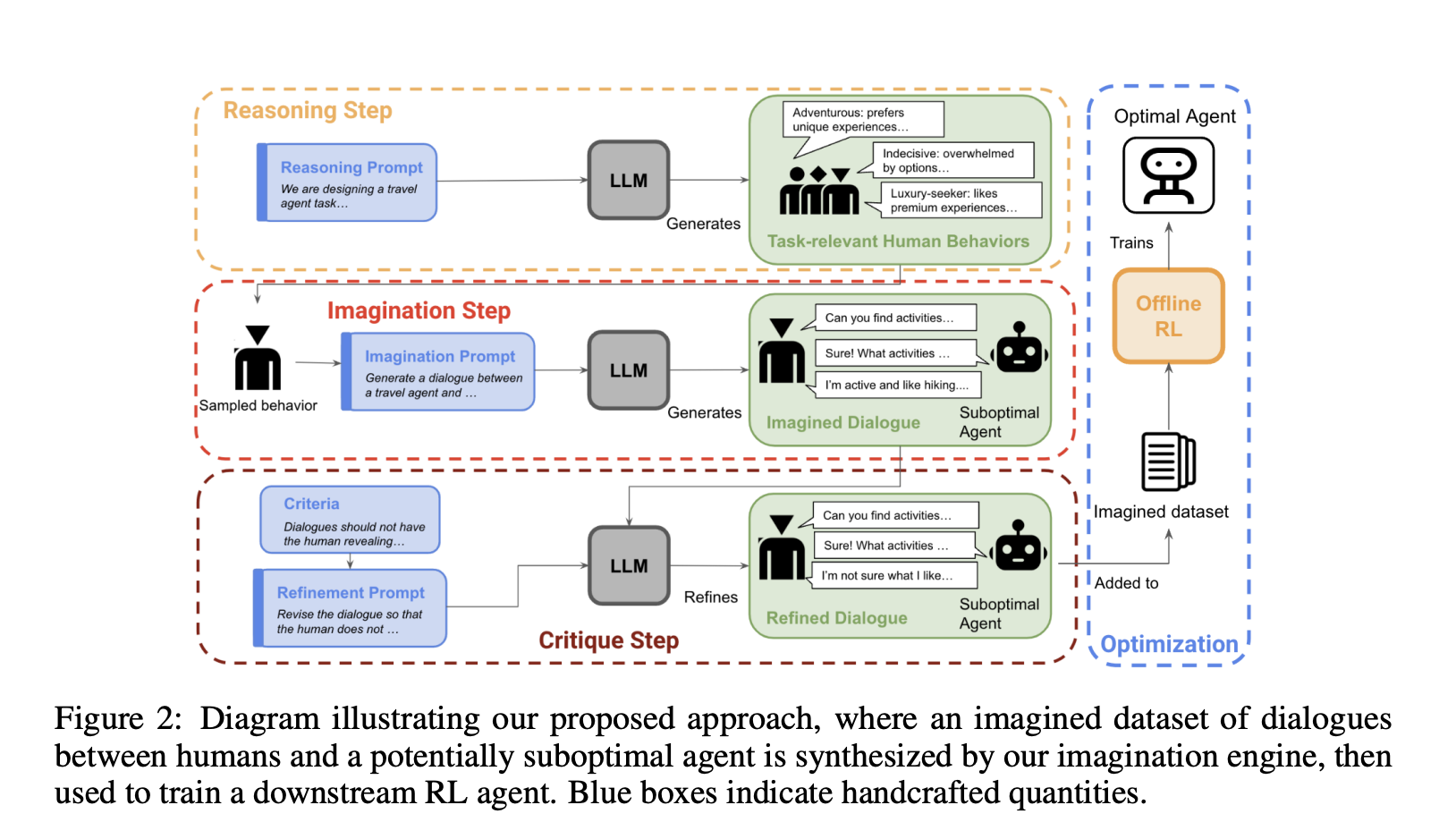
Models trained with supervised fine-tuning or single-step reinforcement learning (RL) commonly struggle with such tasks as they are not optimized for overall conversational outcomes after multiple interactions. Moreover, another area where they lack is dealing with uncertainty in such conversations. In this paper, the researchers from UC Berkeley have explored a new method to adapt LLMs with RL for goal-directed dialogues. Their contributions include an optimized zero-shot algorithm and a novel system called imagination engine (IE) that generates task-relevant and diverse questions to train downstream agents.
Since the IE cannot produce effective agents by itself, the researchers utilize an LLM to generate possible scenarios. To enhance the effectiveness of an agent in achieving desired outcomes, multi-step reinforcement learning is necessary to determine the optimal strategy. The researchers have made one modification to this approach. Instead of using any on-policy samples, they used offline value-based RL to learn a policy from the synthetic data itself.
To test the effectiveness of their method, the researchers compared the performances of a GPT agent and IE+RL using human evaluators. They took into consideration two goal-directed conversations based on real-world problems. The researchers used the GPT-3.5 model in the IE to generate synthetic data and a rather small decoder-only GPT -2 model as the downstream agent. This is what makes their approach practical, as a state-of-the-art model is required only for data generation, thereby reducing computational costs.
Based on their experiments, they found that their proposed agent outperformed the GPT model across all metrics and ensured the naturalness of the resulting dialogue. According to qualitative results also, the IE+RL agent was able to perform better than its counterpart. It produced easy-to-answer questions and follow-up questions based intelligently on the previous one. The researchers also compared the performances of the two agents using a simulation. Although both were almost at par with the IE+RL agent outperforming the GPT agent, the former produced better results when evaluated qualitatively.
In conclusion, in this research paper, the authors have introduced a method to improve the performance of LLMs in goal-directed dialogues. Using an imagination engine, they generate diverse, task-relevant, and realistic synthetic data to train a dialogue agent. More specifically, they use an offline approach to avoid computational costs. Results show that their method consistently outshines traditional methods, paving the way for future improvements. They believe that this process could be automated further to improve the performance of zero-shot dialogue agents and hence enhance the way we interact with AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link
Comments are closed.