Researchers from Microsoft Research and Tsinghua University Proposed Skeleton-of-Thought (SoT): A New Artificial Intelligence Approach to Accelerate Generation of LLMs
Large Language Models (LLMs), such as GPT-4 and LLaMA, have undoubtedly transformed the technological landscape. However, sluggish processing speed is a recurring challenge limiting their widespread applicability. Despite their remarkable capabilities, the time it takes to obtain responses from LLMs hinders their effectiveness, particularly in latency-critical applications like chatbots, copilots, and industrial controllers. Recognizing the need for a solution that addresses this fundamental problem, Microsoft Research and Tsinghua University researchers have introduced an innovative approach named Skeleton-of-Thought (SoT).
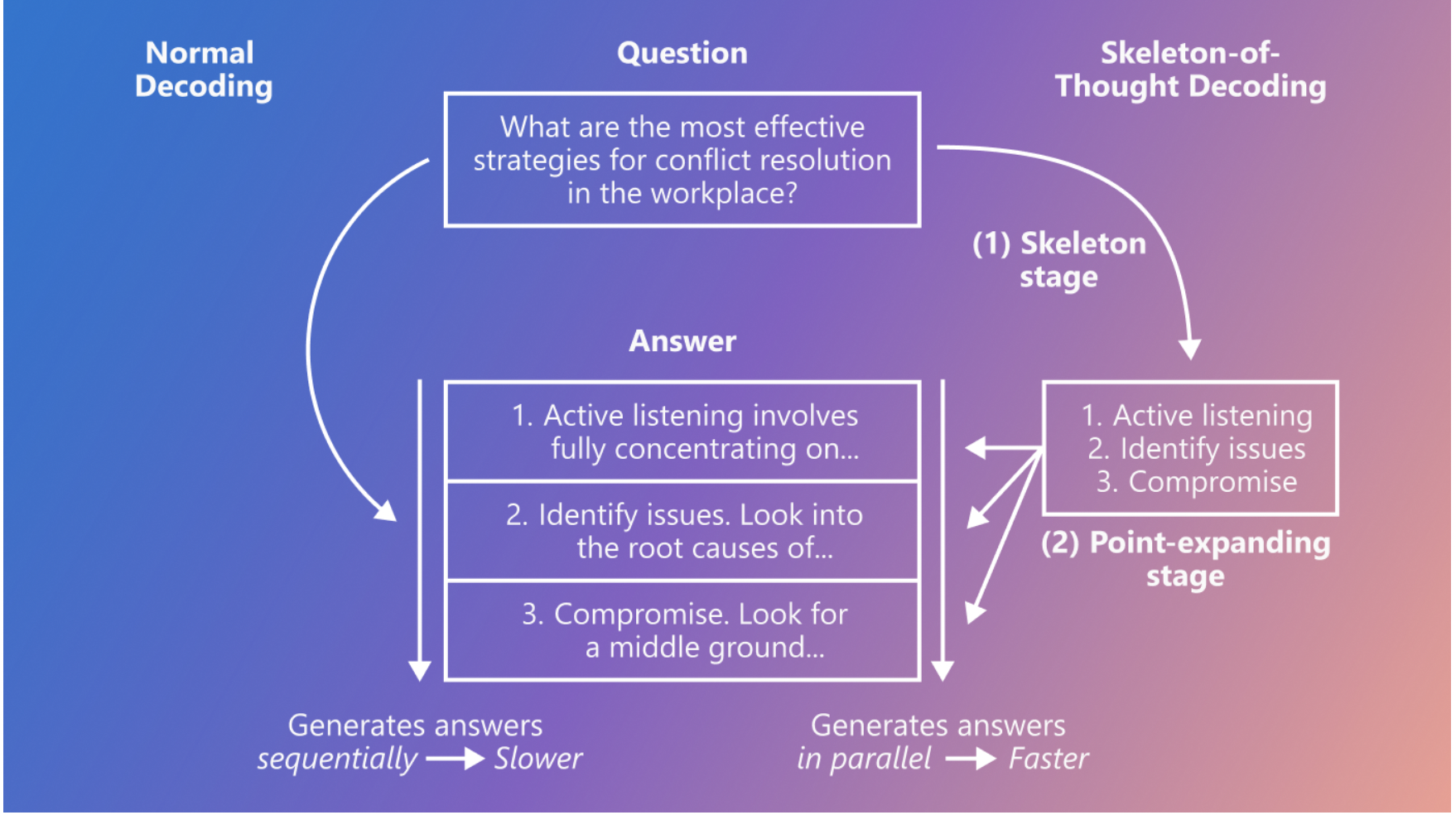
Traditionally, efforts to enhance LLMs’ speed have involved intricate modifications to the models, systems, or hardware. However, the research team takes a different route with SoT. Unlike conventional methods, SoT refrains from making extensive changes to LLMs and treats them as black boxes instead. The focus shifts from altering the internal workings of the models to optimizing the organization of their output content. The proposed solution prompts LLMs to follow a unique two-stage process. In the first stage, the LLM is directed to derive a skeleton of the answer. Subsequently, in the second stage, the LLM is tasked with the parallel expansion of multiple points within the skeleton. This approach introduces a novel means of boosting LLM response times without requiring complex adjustments to the model architecture.
The methodology of SoT involves breaking down the content generation process into two distinctive stages. Firstly, the LLM is prompted to construct a skeleton of the answer. This initial step aligns with how humans often approach problem-solving by outlining a high-level structure. The second stage leverages this skeleton to execute parallel expansion, enabling the LLM to address multiple points simultaneously. Remarkably, this approach is applicable to open-source models like LLaMA and API-based models such as GPT-4, showcasing its versatility.

To evaluate the effectiveness of SoT, the research team conducted extensive tests on 12 recently released models, spanning both open-source and API-based categories. The team observed substantial speed-ups by utilizing the Vicuna-80 dataset, which includes questions from various domains like coding, math, writing, and roleplay. SoT achieved speed-ups ranging from 1.13x to 2.39x on eight 12 models. Crucially, these speed-ups were attained without sacrificing answer quality. The team used metrics from FastChat and LLMZoo to assess the quality of SoT’s answers, showcasing its ability to maintain or improve response quality across diverse question categories.

In conclusion, SoT emerges as a promising solution to the persistent challenge of slow LLMs. The research team’s innovative approach of treating LLMs as black boxes and focusing on data-level efficiency optimization provides a fresh perspective on accelerating content generation. By prompting LLMs to construct a skeleton of the answer and then executing parallel expansion, SoT introduces an effective means of improving response times. The results from the evaluation demonstrate not only considerable speed-ups but also the ability to maintain or enhance answer quality, addressing the dual challenges of efficiency and effectiveness. This work opens up avenues for future exploration in dynamic thinking processes for artificial intelligence, encouraging a shift towards more efficient and versatile language models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.