This AI Paper Proposes ML-BENCH: A Novel Artificial Intelligence Approach Developed to Assess the Effectiveness of LLMs in Leveraging Existing Functions in Open-Source Libraries
LLM models have been increasingly deployed as potent linguistic agents capable of performing various programming-related activities. Despite these impressive advances, a sizable chasm still separates the capabilities demonstrated by these models in static experimental settings from the ever-changing demands of actual programming scenarios.
Standard code generation benchmarks test how well LLM can generate new code from scratch. However, programming conventions rarely necessitate the genesis of all code components from scratch.
When writing code for real-world applications, using existing, publicly available libraries is common practice. These developed libraries offer robust, battle-tested answers to various challenges. Therefore, the success of code LLMs should be evaluated in more ways than only function production, such as their skill in running code derived from open-source libraries with correct parameter usage.
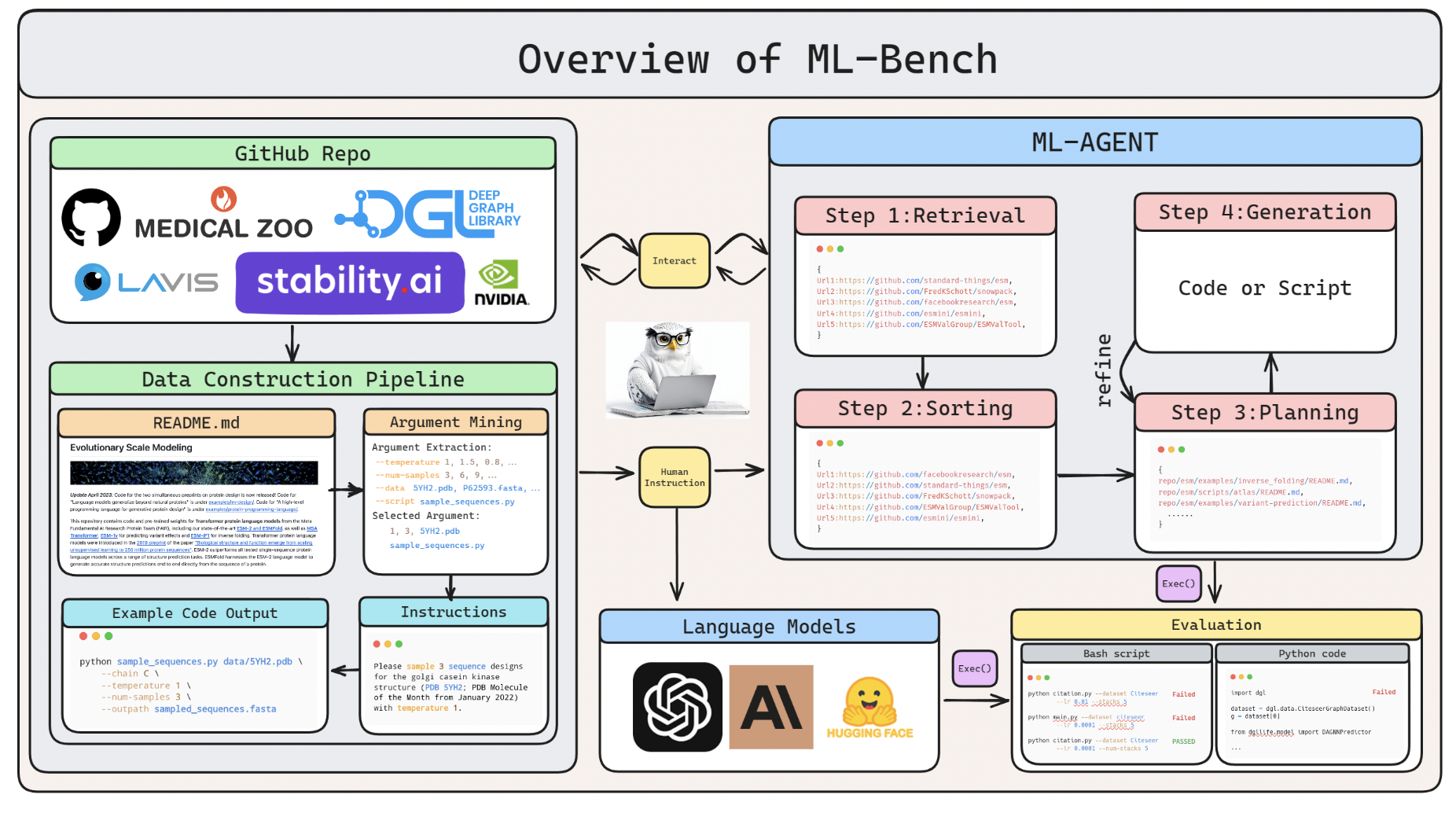
A new study by Yale University, Nanjing University, and Peking University presents ML-BENCH, a realistic and comprehensive benchmark dataset for evaluating LLMs’ abilities to comprehend user instructions, navigate GitHub repositories, and produce executable code. High-quality, instructable ground truth code that satisfies the instructions’ requirements is made available by ML-BENCH. There are 9,444 examples, among 130 tasks and 14 popular machines learning GitHub repositories that make up ML-BENCH.
The researchers use Pass@k and Parameter Hit Precision as metrics in their investigations. Using these tools, they explore the possibilities of GPT-3.5-16k, GPT-4-32k, Claude 2, and CodeLlama in ML-BENCH environments. ML-BENCH suggests new tests for LLMs. The empirical results show that GPT models and Claude 2 outperformed CodeLlama by a wide margin. Although GPT-4 shows a significant performance increase over other LLMs, it still only completes 39.73% of the tasks in the experiments. Other well-known LLms experience hallucinations and underachieve. The findings suggest that LLMs must do more than just write code; they must also understand lengthy documentation. The key technological contribution is the proposal of the ML-AGENT, an autonomous language agent designed to address the deficiencies discovered through their error analysis. These agents can comprehend human language and instructions, generate efficient code, and do difficult tasks.
ML-Bench and ML-Agent represent a significant advancement in the state of the art of automated machine learning processes. The researchers hope that this interests other researchers and practitioners alike.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.