UC Berkeley Researchers Propose CRATE: A Novel White-Box Transformer for Efficient Data Compression and Sparsification in Deep Learning
The practical success of deep learning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. Much of this achievement can be attributed to deep networks’ skill at discovering compressible low-dimensional structures in data and subsequently transforming these discoveries into an economical, i.e., compact and structured, representation. Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier.
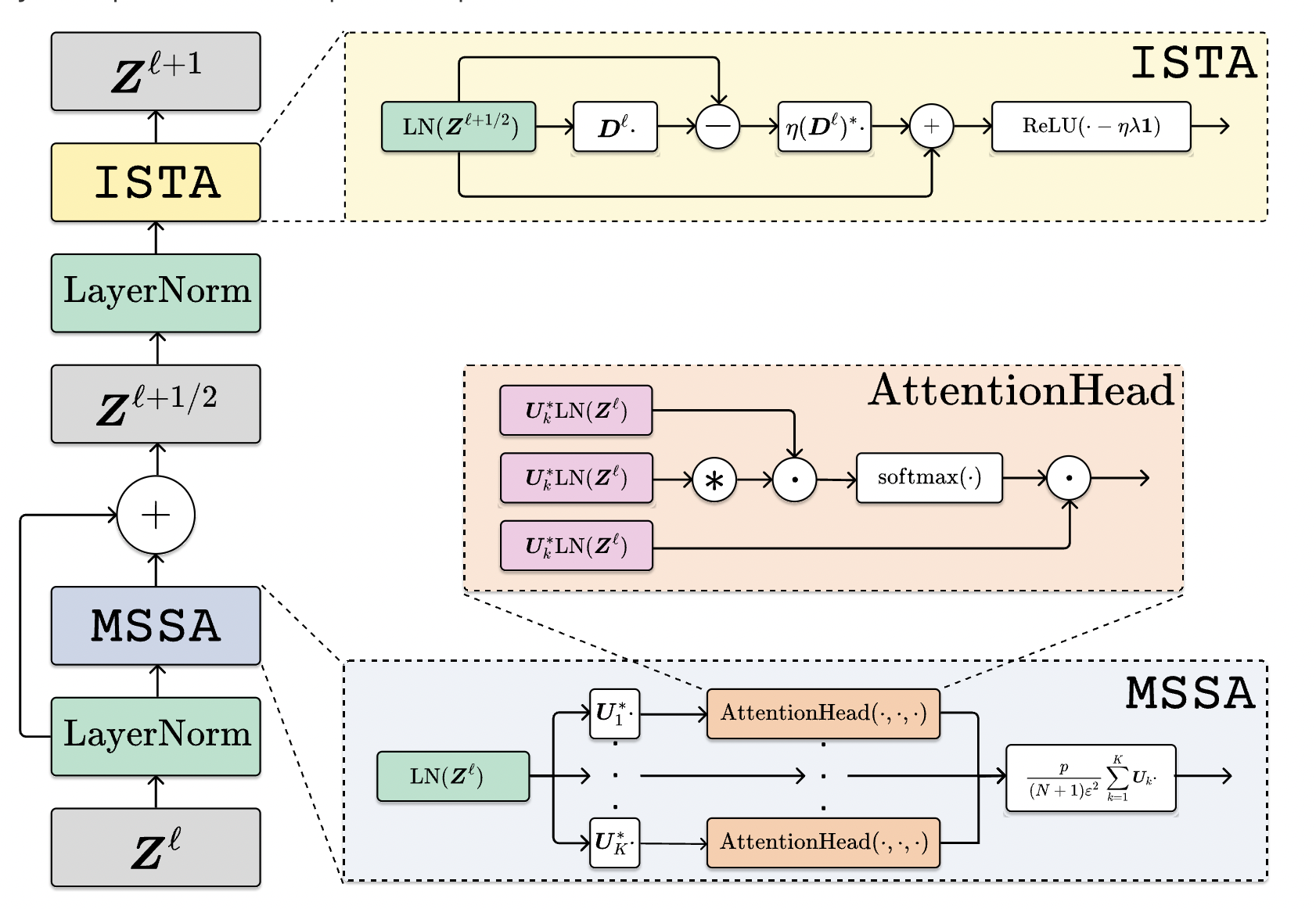
To learn organized and condensed representations, researchers from the UC Berkeley, Toyota Technological Institute at Chicago, ShanghaiTech University, Johns Hopkins University, the University of Illinois, and the University of Hong Kong propose a single goal: a principled measure of goodness. In their work, the researchers argue that one of the most common goals of representation learning is to reduce the dimensionality of the space in which the representations of the data (here, token sets) are stored by fitting them to a Gaussian mixture that is then supported by incoherent subspaces. The goodness of such a representation can be evaluated using a principled measure called sparse rate reduction that simultaneously optimizes the intrinsic information gain and extrinsic sparsity of the learned representation. Iterative approaches to maximize this metric can be seen as what popular deep network designs like transformers are. In particular, by alternating optimization on different aspects of this goal, they derive a transformer block: first, the multi-head self-attention operator compresses the representation via an approximate gradient descent step on the coding rate of the features, and then, the subsequent multi-layer perceptron specifies the features.
This led them to a deep network design resembling a transformer, which is a completely “white box” in the sense that its optimization target, network operators, and learned representation are all fully interpretable mathematically. They refer to this type of white-box deep architecture as a “crate” or “crate-transformer,” which is an abbreviation for “coding-rate” transformer. The team also provides rigorous mathematical proof that these incremental mappings are invertible in a distributional sense, with inverses comprising the same operator family. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design.
To show that this framework can truly bridge the gap between theory and practice, the researchers have conducted extensive experiments on both image and text data to evaluate the practical performance of the crate model on a wide range of learning tasks and settings that conventional transformers, such as ViT, MAE, DINO, BERT, and GPT2, have demonstrated strong performance. Surprisingly, the crate has shown competitive performance concerning its black-box counterparts on all tasks and settings, including image classification via supervised learning, unsupervised masked completion for imagery and language data, and self-supervised feature learning for imagery data. Furthermore, the crate model exhibits many useful features. It exhibits semantic meaning by easily segmenting an object from its background and partitioning it into shared parts. Each layer and network operator has statistical and geometric meaning. They believe the proposed computational paradigm shows tremendous promise in connecting deep learning theory and practice from a unified viewpoint of data compression.
The team highlights that with limited resources, they do not strive for state-of-the-art performance on all of the tasks above, which would need heavy engineering or considerable fine-tuning, nor can they construct and test their models at current industrial scales. The solutions they’ve developed for these chores are generally generic and lack task-specific flexibility. However, they think these studies have proven beyond a reasonable doubt that the white-box deep network crate model built from these data is universally effective and provides a firm foundation for future engineering research and development.
On large-scale real-world (image or text) datasets and tasks (discriminative and generative), in supervised, unsupervised, and self-supervised situations, these networks display performance comparable to seasoned transformers despite being perhaps the simplest among all available architectures. They believe this work offers a fresh perspective that could shed light on the full potential of current AI systems, which are frequently based on deep networks like transformers.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.