Microsoft Researchers Propose PIT (Permutation Invariant Transformation): A Deep Learning Compiler for Dynamic Sparsity
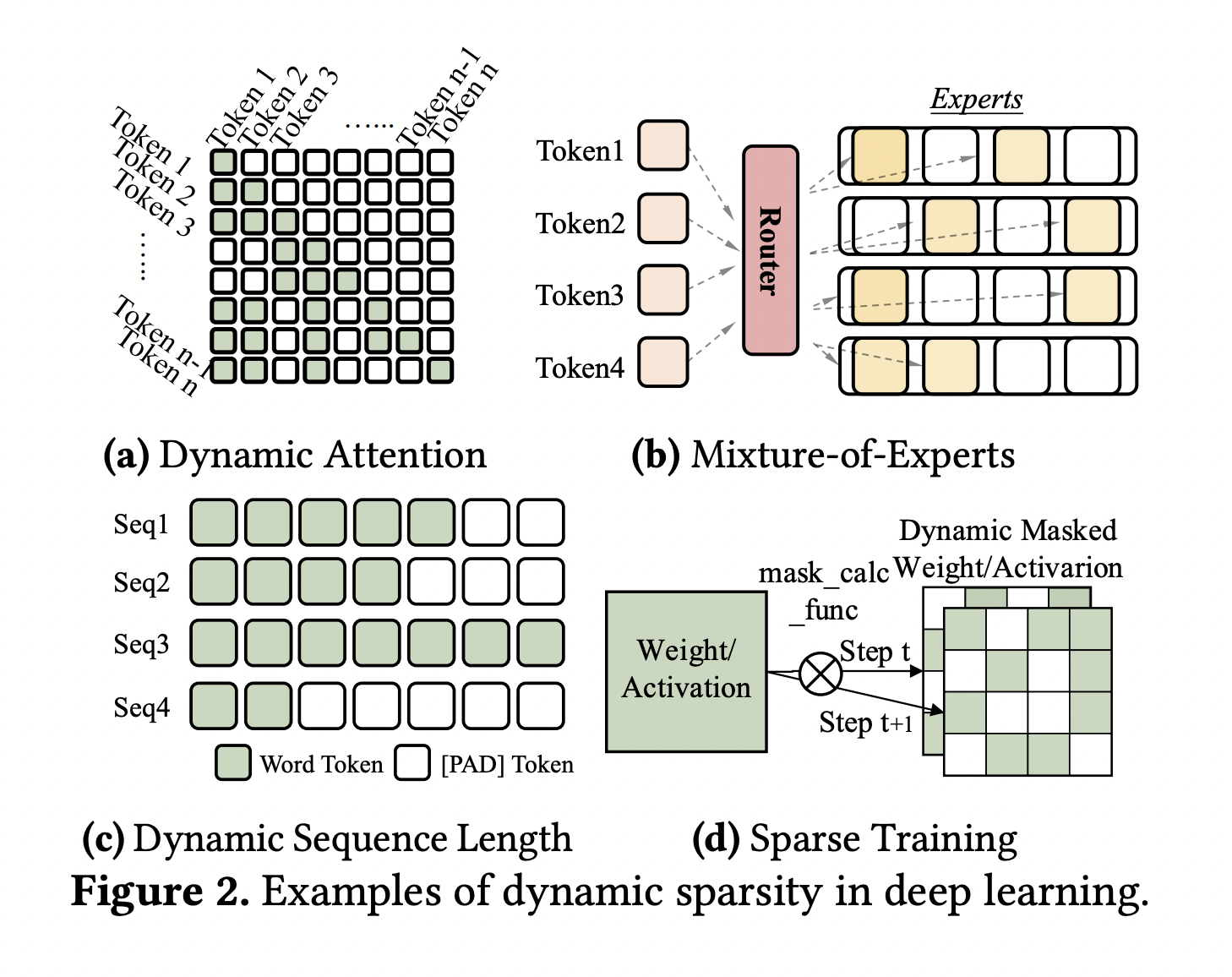
Recently, deep learning has been marked by a surge in research aimed at optimizing models for dynamic sparsity. In this scenario, sparsity patterns only reveal themselves at runtime, posing a formidable challenge to efficient computation. Addressing this challenge head-on, a group of researchers proposed a novel solution called Permutation Invariant Transformation (PIT), showcased in their latest research at the 29th ACM Symposium on Operating Systems Principles.
The state-of-the-art solutions in sparsity-aware deep learning have traditionally grappled with predefined, static sparsity patterns. The inherent challenge lies in the substantial overhead linked to preprocessing, restricting these solutions from effectively handling dynamic sparsity patterns that are only known during runtime. The researchers acknowledge that the efficient execution of dynamic sparse computation encounters a fundamental misalignment between GPU-friendly tile configurations – crucial for achieving high GPU utilization – and sparsity-aware tile shapes aimed at minimizing coverage waste, i.e., non-zero values in a tensor that do not contribute to the computation.
Enter PIT, a deep-learning compiler that charts a new course in the optimization landscape. At its core, PIT leverages Permutation Invariant Transformation, a mathematically proven property. This transformation enables the consolidation of multiple sparsely located micro-tiles into a GPU-efficient dense tile without altering the computation results. This strategic maneuver balances high GPU utilization and minimal coverage waste, marking a paradigm shift in dynamic sparsity handling.

PIT’s workflow begins with identifying feasible PIT rules for all operators within a given model. These rules serve as the blueprint for generating efficient GPU kernels tailored to the specific requirements of dynamic sparsity. Importantly, this entire process occurs at runtime, ensuring that PIT can dynamically adapt to sparsity patterns as they unfold. The implementation involves two critical primitives – SRead and SWrite – that enable PIT rules to be executed rapidly, supporting dynamic sparsity online.
Digging into the technical intricacies, PIT’s online sparsity detection and sparse-dense data transformation mechanisms play a pivotal role. The Permutation Invariant Transformation is the linchpin, allowing PIT to construct computation-efficient dense tiles from micro-tiles, aligning with GPU-friendly configurations. This approach starkly contrasts conventional solutions that grapple with significant offline data rearrangement overheads.
The researchers conducted an extensive evaluation, putting PIT to the test across diverse models. The results are impressive, with PIT showcasing its prowess by accelerating dynamic sparsity computation by up to 5.9 times compared to state-of-the-art compilers. This performance boost underscores the tangible impact of PIT in addressing the computational challenges posed by dynamic sparsity.
PIT’s contribution extends to sparse training scenarios, further solidifying its versatile and robust solution position. The research doesn’t just stop at proposing a novel method; it provides a comprehensive toolkit for handling dynamic sparsity, setting the stage for transformative advancements in the realm of deep learning optimization.
In conclusion, the groundbreaking dynamic sparsity optimization tool introduced in this research, harnessing the power of Permutation Invariant Transformation (PIT), not only addresses the persistent challenge of aligning GPU-friendly tile configurations with sparsity-aware tile shapes but also propels the field toward a new era of efficiency in deep learning. With its remarkable acceleration of computation efficiency, versatility in handling diverse models, and potential applications in sparse training scenarios, this research lays the foundation for transformative advancements in dynamic sparsity adaptation, positioning itself as a pivotal player in the ever-evolving landscape of deep learning optimization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.