Exploring the Frontiers of AI in Single-Cell Biology: A Critical Evaluation of Zero-Shot Foundation Models like Geneformer and scGPT
The application of foundational models in single-cell biology has been a recent topic of discussion among researchers. Models like scGPT, GeneCompass, and Geneformer are some of the promising tools for this field. However, their efficacy has been a point of concern, particularly in zero-shot settings, especially when this field involves exploratory experiments and a lack of clear labels for fine-tuning. This paper is based on this issue and rigorously assesses the zero-shot performance of these models.
Previously, there have been studies relying on fine-tuning these models on specific tasks, but its limitations become quite evident when applied to the field of single-cell biology because of the nature of this field, as well as due to high computational requirements. Therefore, to address this challenge, Microsoft researchers evaluated the zero-shot performance of Geneformer and scGPT foundational models on multiple facets involving diverse datasets and an array of tasks like the utility of embeddings for cell type clustering, batch effect correction, and the effectiveness of the models’ input reconstruction based on the pretraining objectives.
The reason for choosing these two models is because of the availability of their pretrained weights (at the time of their assessment). For their evaluation, the researchers used five distinct human tissue datasets, each posing unique, relevant challenges to single-cell analysis. For comparison, the researchers used a generative model called scVI, which was trained on each dataset. They used the following metrics for each task:
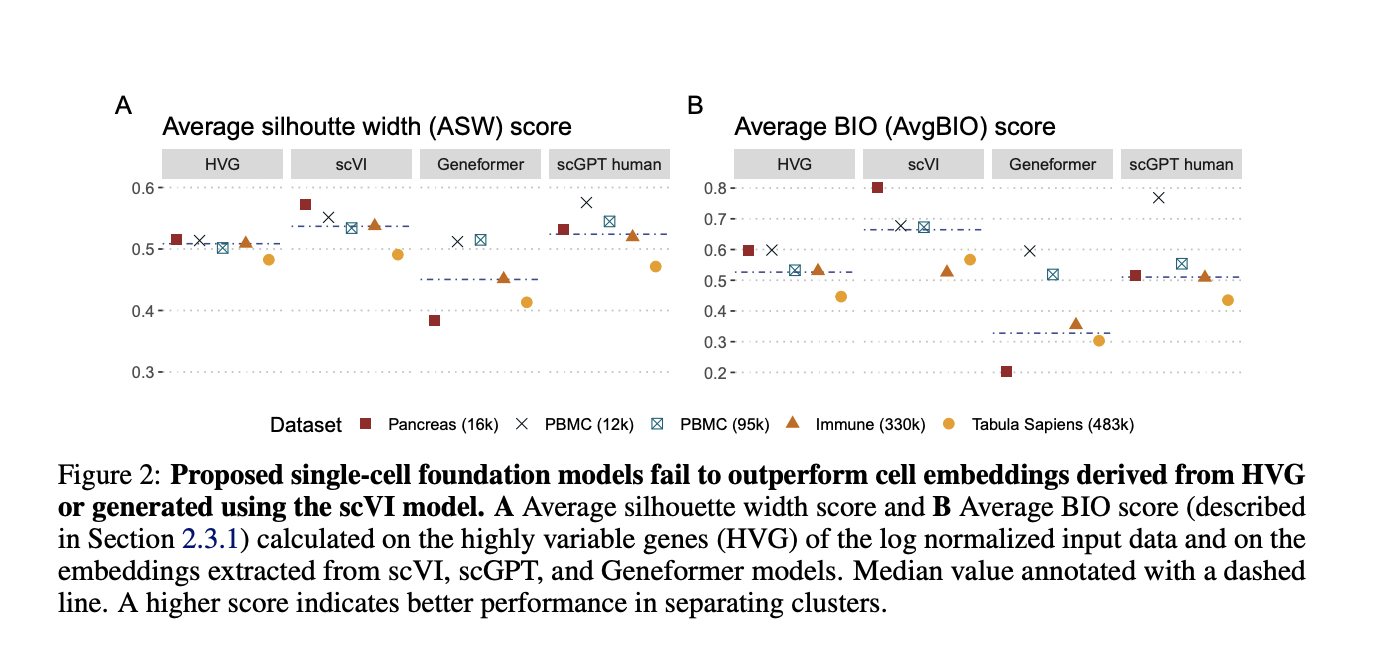
- For evaluating cell embeddings, they used Average Silhouette Width (ASW) and the Average Bio (AvgBIO) scores to calculate the degree to which the cell types are unique within the embedding space.
- For batch integration, they employed a variation of the AWS score on a scale between 0 and 1, with 0 signifying complete separation of the batches and 1 signifying a perfect batch mixing.
- For evaluating the performance of scGPT and Geneformer in their pretraining objective, they used mean squared error (MSE) and Pearson’s correlation, respectively.
scGPT and Geneformer performed worse than the baseline strategies for both metrics. Geneformer had a high variance for different datasets, and although scGPT performed better than the base model scVI for one of the datasets, it fell behind for two of them. Subsequently, the researchers evaluated the impact of the pretraining dataset on the model performance, focusing mainly on scGPT (four variants of scGPT), and found an improvement in the median scores for all model variants.
When evaluated on batch effects, both models showed poor results, often lagging behind models like scVI, which suggests that they are not completely robust to batch effects in zero-shot environments. For the last set of evaluations, the researchers found that scGPT fails to reconstruct gene expressions, while Geneformer gives a better performance. When compared against a baseline, they observed that the baseline prediction outperformed all scGPT variants, and Geneformer performed better than the average rankings in one of the datasets.
In conclusion, the researchers extensively analyzed the zero-shot capabilities of scGPT and Geneformer when applied to single-cell biology, and their analysis highlights the sub-par performance of these models. Their findings present that scGPT outperforms the Geneformer model in all evaluations. Lastly, the researchers also provided some insights as to where the future work needs to be focused, namely expressing the relationship between pretraining task, pretraining dataset, and performance on downstream analysis tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.