Meet DreamSync: A New Artificial Intelligence Framework to Improve Text-to-Image (T2I) Synthesis with Feedback from Image Understanding Models
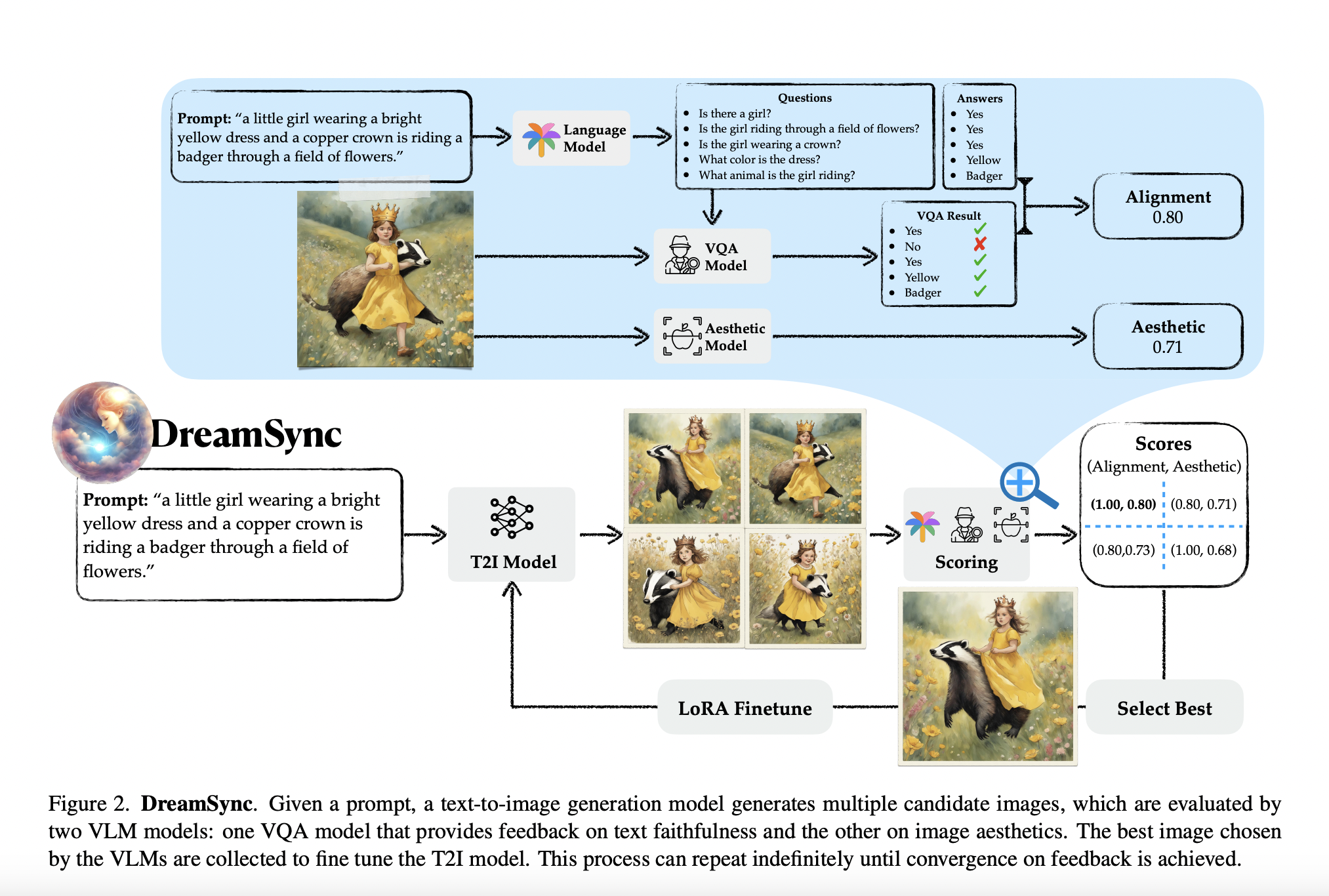
Researchers from the University of Southern California, the University of Washington, Bar-Ilan University, and Google Research introduced DreamSync, which addresses the problem of enhancing alignment and aesthetic appeal in diffusion-based text-to-image (T2I) models without the need for human annotation, model architecture modifications, or reinforcement learning. It achieves this by generating candidate images, evaluating them using Visual Question Answering (VQA) models, and fine-tuning the text-to-image model.
Previous studies proposed using VQA models, exemplified by TIFA, to assess T2I generation. With 4K prompts and 25K questions, TIFA facilitates evaluation across 12 categories. SeeTrue and training-involved methods like RLHF and training adapters address T2I alignment. Training-free techniques, for example, SynGen and StructuralDiffusion, adjust inference for alignment.
DreamSync addresses challenges in T2I models, enhancing faithfulness to user intentions and aesthetic appeal without relying on specific architectures or labeled data. It introduces a model-agnostic framework utilizing vision-language models (VLMs) to identify discrepancies between generated images and input text. The method involves developing multiple candidate images, evaluating them with VLMs, and fine-tuning the T2I model. DreamSync offers improved image alignment, outperforming baseline methods, and can enhance various image characteristics, extending its applicability beyond alignment improvements.
DreamSync employs a model-agnostic framework for aligning T2I generation with feedback from VLMs. The process involves generating multiple candidate images from a prompt and evaluating them for text faithfulness and image aesthetics using two dedicated VLMs. The selected best image, determined by VLM feedback, is used to fine-tune the T2I model, with the iteration repeating until convergence. It also introduces iterative bootstrapping, utilizing VLMs as teacher models to label unlabeled data for T2I model training.
DreamSync enhances both SDXL and SD v1.4 T2I models, with three SDXL iterations resulting in 1.7 and 3.7 points improvement in faithfulness on TIFA. Visual aesthetics also improved by 3.4 points. Applying DreamSync to SD v1.4 yields a 1.0-point faithfulness improvement and a 1.7-point absolute score increase on TIFA, with aesthetics improving by 0.3 points. In a comparative study, DreamSync outperforms SDXL in alignment, producing images with more relevant components and 3.4 more correct answers. It achieves superior textual faithfulness without compromising visual appearance on TIFA and DSG benchmarks, demonstrating gradual improvement over iterations.
In conclusion, DreamSync is a versatile framework evaluated on challenging T2I benchmarks, showing significant improvements in alignment and visual appeal across both in-distribution and out-of-distribution settings. The framework incorporates dual feedback from vision-language models and has been validated by human ratings and a preference prediction model.
Future enhancements for DreamSync include grounding feedback with detailed annotations like bounding boxes for identifying misalignments. Tailoring prompts at each iteration aim to target specific improvements in text-to-image synthesis. The exploration of linguistic structure and attention maps aims to enhance attribute-object binding. Training reward models with human feedback can further align generated images with user intent. Extending DreamSync’s application to other model architectures, evaluating performance, and additional studies in diverse settings are areas for ongoing investigation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.