Alibaba AI Open-Sources Qwen Series that Includes Qwen-1.8B, Qwen-7B, Qwen-14B, and Qwen-72B along with Qwen-Chat Series
With the most recent models in its Qwen series of open-source AI models, Alibaba Cloud is pushing the boundaries of AI technology even further. Alibaba has expanded its AI solutions with the release of Qwen-1.8B and Qwen-72B, as well as specialized chat and audio models. Alibaba’s dedication to developing AI capabilities is demonstrated by these models, which provide improved performance and versatility in language and audio processing.
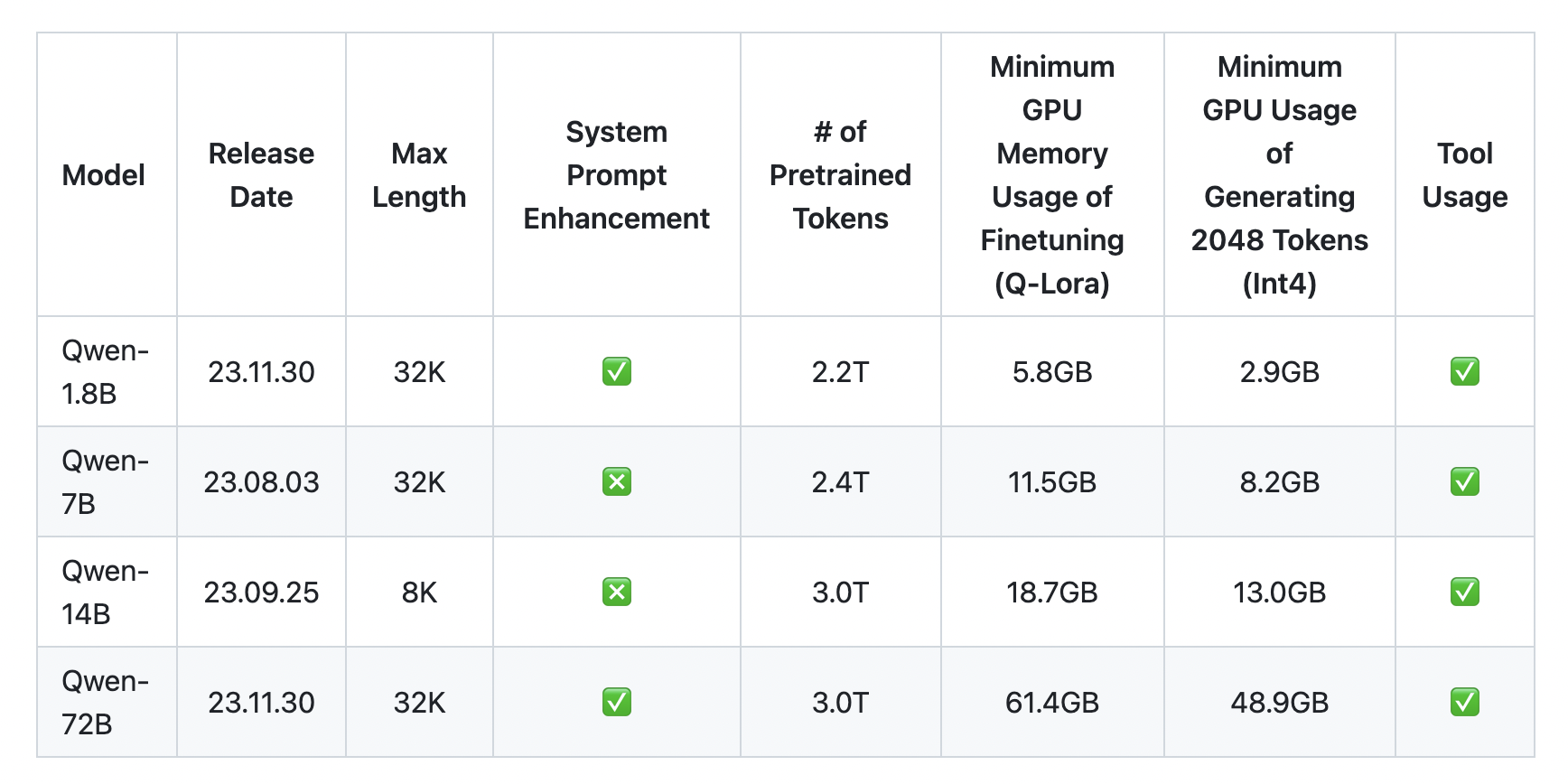
With the release of the Qwen-1.8B and its larger equivalent, the Qwen-72B, the Qwen series—which already comprises the Qwen-7B and Qwen-14B—has been significantly enhanced. Pretrained on a massive corpus of more than 2.2 trillion tokens, Qwen-1.8B is a transformer-based model with 1.8 billion parameters. This model outperforms many similar-sized and even larger models in various language tasks in both Chinese and English. It also supports a long context with 8192 tokens.
Notably, Qwen-1.8B, with its quantized variants int4 and int8, provides an affordable deployment solution. These characteristics make it a sensible option for various applications by drastically lowering memory needs. Its extensive vocabulary of more than 150K tokens further improves its linguistic ability.
The larger model, Qwen-72B, has been trained on 3 trillion tokens. This model outperforms GPT-3.5 in most tasks and outperforms LLaMA2-70B in all tested tasks. Alibaba has designed the models to enable low-cost deployment despite their large parameters; quantized versions allow minimum memory use of around 3GB. This breakthrough significantly reduces the obstacles to working with massive models that used to cost millions of dollars on cloud computing.
Alibaba introduced Qwen-Chat, optimized versions designed for AI support and conversational capabilities, in addition to Qwen base models. In addition to generating material and facilitating natural conversation, Qwen-Chat can execute code interpretation and summarization tasks.
With its ability to handle various audio inputs in addition to text to generate text outputs, Alibaba’s Qwen-Audio represents a noteworthy advancement in multimodal AI. Remarkably, Qwen-Audio achieves state-of-the-art performance in speech recognition and a variety of audio understanding standards without the need for fine-tuning.
In the audio arena, Qwen-Audio establishes a new benchmark as a foundation audio-language model. It uses a multi-task learning framework to handle many audio formats. It achieves impressive results on multiple benchmarks, including state-of-the-art scores on tasks such as AISHELL-1 and VocalSound.
Wen-Audio’s adaptability includes operating several chat sessions from text and audio inputs, with features ranging from speech editing tools to music appreciation and sound interpretation.
Check out the Paper, Github, and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.