Can We Optimize Large Language Models More Efficiently? Check Out this Comprehensive Survey of Algorithmic Advancements in LLM Efficiency
Can We Optimize Large Language Models More Efficiently? A research team consisting of researchers from multiple organizations like Microsoft, the University of Southern California, and Ohio State University deliver a thorough review of algorithmic advancements targeting the efficiency enhancement of LLMs and encompassing scaling laws, data utilization, architectural innovations, training strategies, and inference techniques. The comprehensive insights aim to lay the foundation for future innovations in efficient LLMs.
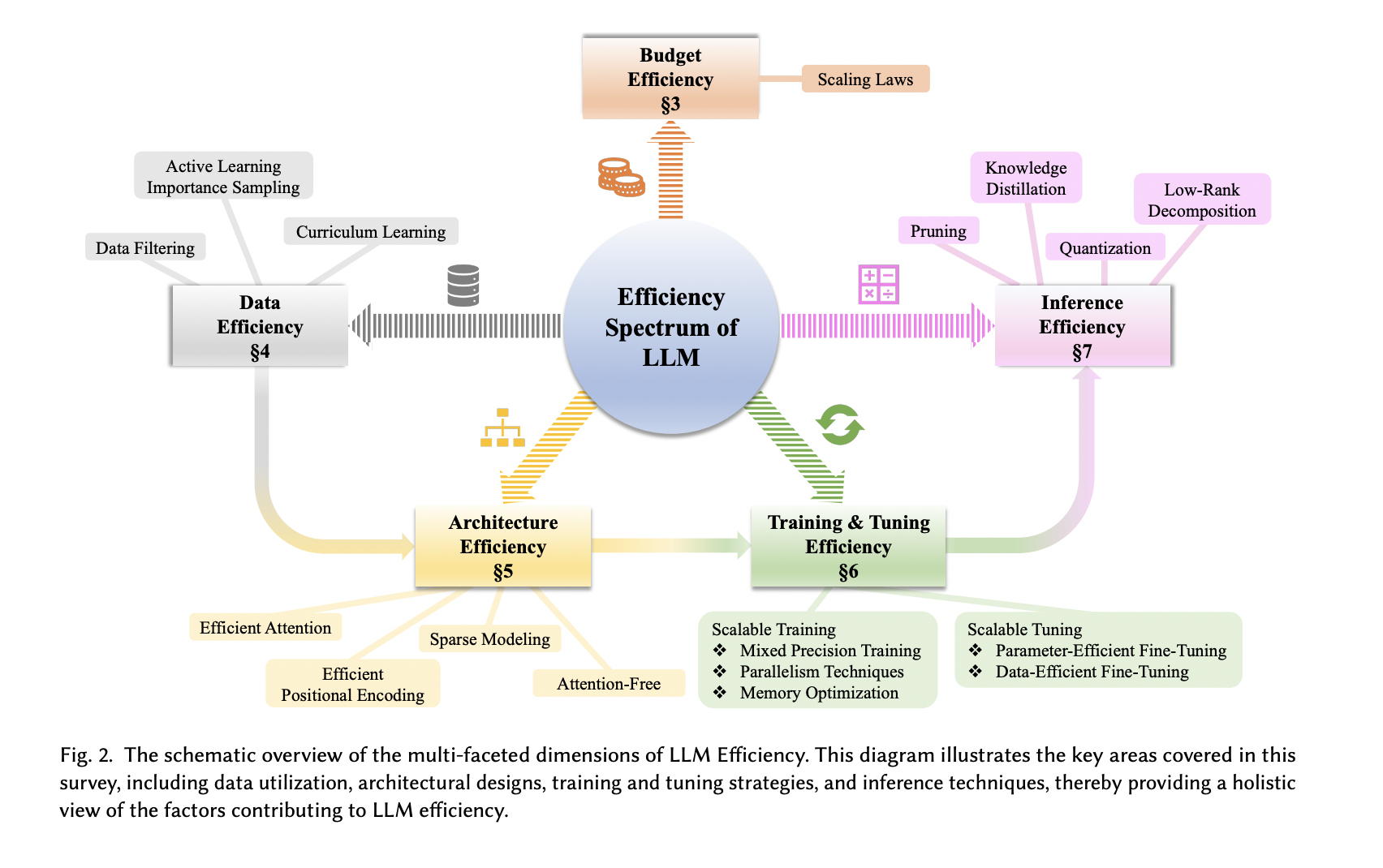
Covering scaling laws, data utilization, architectural innovations, training strategies, and inference techniques, it outlines core LLM concepts and efficiency metrics. The review provides a thorough, up-to-date overview of methodologies contributing to efficient LLM development. The researchers encourage suggestions for additional references, acknowledging the potential oversight of relevant studies.
LLMs play a vital role in natural language understanding. However, their high computational costs make them not easily accessible to everyone. To overcome this challenge, researchers continuously make algorithmic advancements to improve their efficiency and make them more accessible. These advancements are paving the way for future innovations in AI, particularly in the domain of natural language processing.
The study surveys algorithmic advancements that enhance the efficiency of LLMs. It examines various efficiency facets, scaling laws, data utilization, architectural innovations, training strategies, and inference techniques. Specific methods such as Transformer, RWKV, H3, Hyena, and RetNet are referenced. The discussion includes knowledge distillation methods, compact model construction methods, and frequency-based techniques for attention modeling and computational optimization.
The survey adopts a holistic perspective on LLM efficiency rather than focusing on specific areas, covering diverse efficiency aspects, including scaling laws, data utilization, architectural innovations, training strategies, and inference techniques. Serving as a valuable resource, it lays the foundation for future innovations in LLM efficiency. Including a reference repository enhances its utility for further exploration and research in this critical domain. However, specific results and findings of individual studies and methods mentioned in the study should be explicitly provided in the given sources.
In conclusion, the survey delves into the latest algorithmic advancements that can enhance the efficiency of LLM technology. It covers scaling laws, data utilization, architectural innovations, training strategies, and inference techniques. The survey emphasizes the importance of algorithmic solutions and explores methods like model compression, knowledge distillation, quantization, and low-rank decomposition to improve LLM efficiency. This all-encompassing survey is an essential tool that can offer a plethora of valuable insights into the present state of LLM efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.