Meet Notus: Enhancing Language Models with Data-Driven Fine-Tuning

In the pursuit of refining language models to align more closely with user intent and elevate response quality, a new iteration emerges – Notus. Stemming from Zephyr’s foundations, Notus, a fine-tuned version of Data Preference Optimization (DPO), emphasizes high-quality data curation for a more refined response generation process.
Zephyr 7B Beta, released recently, marked a significant stride in creating a more compact yet intent-aligned Language Model (LLM). Their methodology involved distilled Supervised Fine-Tuning (dSFT) followed by distilled Direct Preference Optimization (dDPO) using AI Feedback (AIF) datasets like UltraFeedback.
Recognizing the benefits of applying DPO after SFT, Zephyr 7B Beta surpassed other models, outperforming larger counterparts like Llama 2 Chat 70B. Notus builds upon this success, taking a different approach to data curation for enhanced model fine-tuning.
The foundation for Notus lies in leveraging the same data source as Zephyr – openbmb/UltraFeedback. However, Notus pivots towards prioritizing high-quality data through meticulous curation. UltraFeedback contains responses evaluated using GPT-4, each assigned scores across preference areas (instruction-following, truthfulness, honesty, and helpfulness), alongside rationales and an overall critique score.
Notably, while Zephyr used the overall critique score to determine chosen responses, Notus opted to analyze the average preference ratings. Surprisingly, in about half of the examples, the highest-rated response based on average preference ratings differed from the one chosen using the critique score.
To curate a dataset conducive to DPO, Notus computed the average of preference ratings and selected the response with the highest average as the chosen one, ensuring its superiority over a randomly selected rejected response. This meticulous curation process was geared towards bolstering the dataset’s quality and aligning responses more accurately with user preferences.
Notus aims to re-iterate both the response generation and AI ranking stage while keeping the dSFT stage as is and apply the dDPO on top of the previously dSFT fine-tuned version of Zephyr so that the main focus relies on understanding and exploring the AIF data and experiment around that idea.
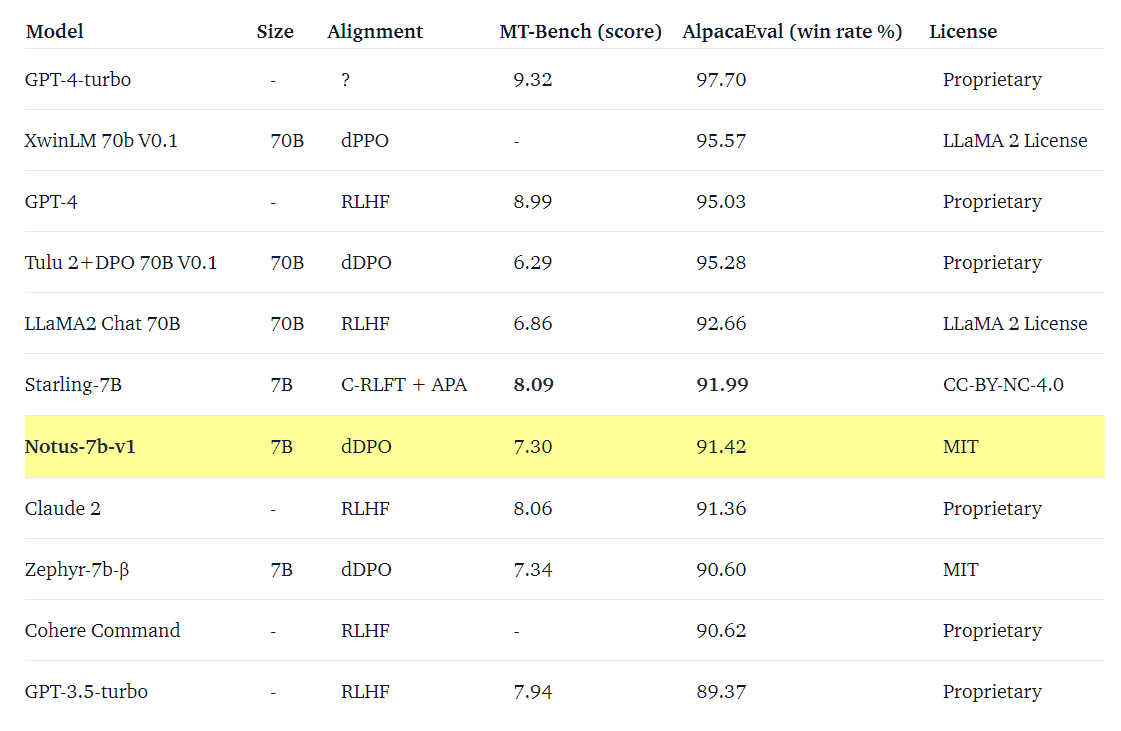
The results spoke volumes about Notus’ efficacy. It nearly matched Zephyr on MT-Bench while outperforming Zephyr, Claude 2, and Cohere Command on AlpacaEval, solidifying its position among the most competitive 7B commercial models.
Looking ahead, Notus and its developers at Argilla remain steadfast in their commitment to a data-first approach. They are actively crafting an AI Feedback (AIF) framework to collect LLM-generated feedback, aspiring to create high-quality synthetic labeled datasets akin to UltraFeedback. Their aim extends beyond refining in-house LLMs; they aspire to contribute open-source models to the community while continually enhancing data quality for superior language model performance.
In conclusion, Notus emerges as a testament to the power of meticulous data curation in fine-tuning language models, setting a new benchmark for intent-aligned, high-quality responses in AI-driven language generation.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.