Enhancing Machine Learning Reliability: How Atypicality Improves Model Performance and Uncertainty Quantification
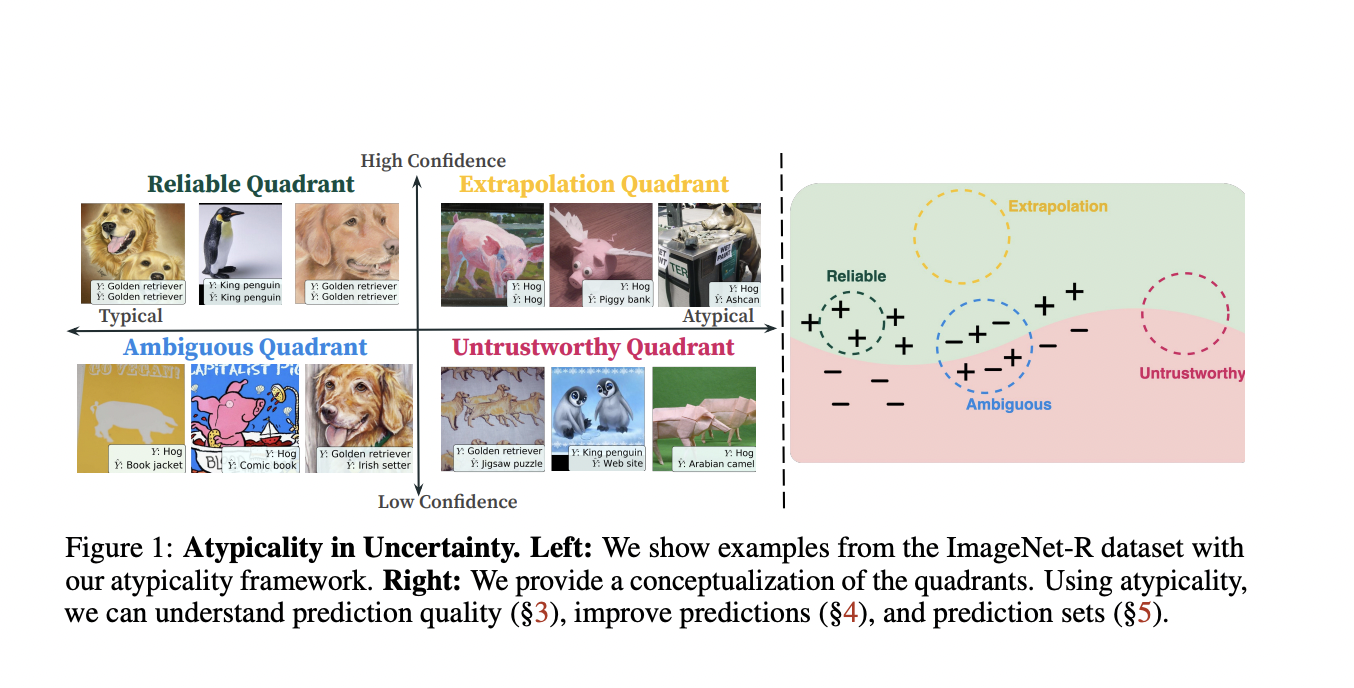
An object is considered typical if it resembles other items in its category. For instance, a penguin is an unusual bird, yet a dove and a sparrow are normal birds. Several cognitive science studies imply that typicality is essential to category knowledge. Humans, for example, have been demonstrated to learn, recall, and relate to common objects more quickly. Comparably, the representativeness heuristic refers to people’s propensity to base judgments on how common an occurrence is. Although this cognitive bias helps quick decision-making, it might result in inaccurate uncertainty assessments. For example, one may overestimate the likelihood of normal events or undervalue the degree of uncertainty in judgments about unusual events.
Although measuring the degree of uncertainty in human judgments is challenging, machine learning methods offer assurance in their forecasts. Nevertheless, confidence alone may not always be enough to determine a prediction’s trustworthiness. A low-confidence prediction, for example, might result from a clearly stated uncertainty or the sample being underrepresented in the training distribution. Similarly, a prognosis with high confidence could be accurate or miscalibrated. Their key suggestion is that to understand the coverage of the training distribution or the predictability of the predictions, models should measure both the atypicality and the confidence. Nevertheless, many machine learning applications use pretrained models that don’t provide any measure of atypicality. Rather, they only offer confidence levels.
The research team from Stanford University and Rutgers University looks at the link between a sample’s or class’s degree of atypicality (rareness) and the accuracy of a model’s predictions. Here are their contributions:
1. Recognize the Prediction Quality: Through this research the team demonstrates that with basic atypicality, estimators can evaluate how well a model’s projected probability matches the actual chances of certain occurrences. Even logistic regression and neural networks might have incorrect calibrations right out of the box. Here, atypicality can provide information about when the confidence in a model is trustworthy. Through rigorous testing and theoretical study, the research team shows that atypicality leads to lower-quality predictions. In particular, the research team demonstrated that predictions with higher overconfidence and worse accuracy are made for atypical inputs and samples from atypical classes.
2. Boost Accuracy and Calibration: By modifying a probabilistic model, calibration techniques mitigate miscalibration. The research team demonstrated that models require various corrections based on unusual inputs and classes and that atypicality plays a major role in recalibration. The research team suggests a straightforward technique called Atypicality-Aware Recalibration in light of these findings. Their recalibration technique is easy to implement and accounts for the atypicality of the inputs and classes. The research team demonstrated that adding atypicality to recalibration techniques enhances prediction accuracy and uncertainty quantification. Additionally, the research team demonstrated that atypicality awareness can enhance performance across several skin-tone subgroups without requiring access to group annotations in a case study that categorizes skin lesions.
3. Boost Prediction Arrays: Prediction sets with a high chance of the label’s inclusion are another way to assess uncertainty. Here, the research team examines the atypicality of current approaches and demonstrates that low-confidence or atypical samples may cause prediction sets to underperform. The research team illustrates the possibility of enhancing prediction sets through the use of atypicality.
Overall, the research team suggests that atypicality should be considered in models, and the research team demonstrates that atypicality estimators that are straightforward to use may be highly valuable.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.