This AI Research Shares a Comprehensive Overview of Large Language Models (LLMs) on Graphs
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). These models have been pre-trained on large text corpora and have shown incredible performance in multiple tasks, including question answering, content generation, text summarization, etc.
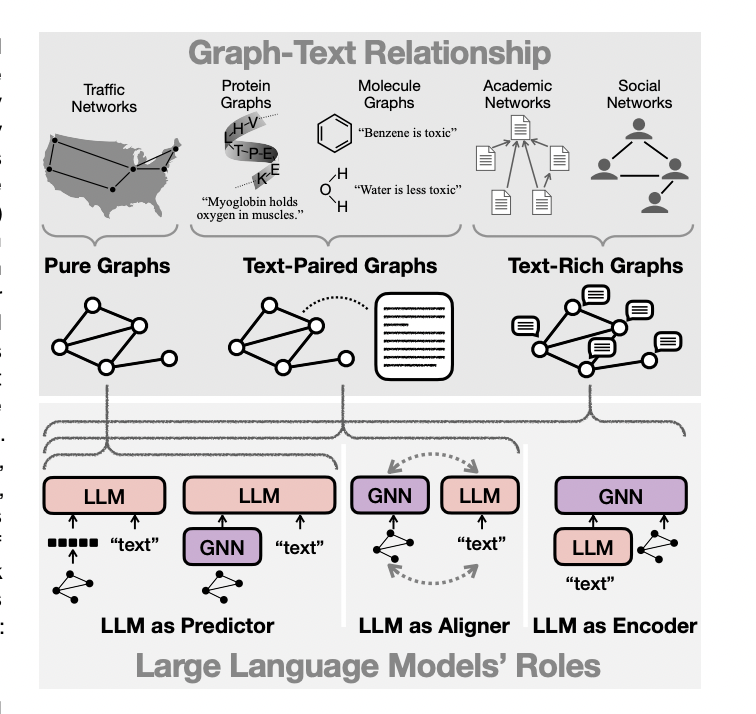
Though LLMs have proven capable of handling plain text, handling applications where textual data is linked to structural information in the form of graphs is becoming increasingly necessary. Researchers have been studying how LLMs, with their good text-based reasoning, can be applied to basic graph reasoning tasks, including matching subgraphs, shortest paths, and connection inference. Three types of graph-based applications, i.e., pure graphs, text-rich graphs, and text-paired graphs, have been associated with the integration of LLMs. Techniques include treating LLMs as task predictors, feature encoders for Graph Neural Networks (GNNs), or aligners with GNNs, depending on their function and interaction with GNNs.
LLMs are becoming increasingly popular for graph-based applications. Still, there are very few studies that look at how LLMs and graphs interact. In recent research, a team of researchers has proposed a methodical overview of the situations and methods associated with the integration of big language models with graphs. The aim is to sort possible situations into three primary categories: text-rich graphs, text-paired graphs, and pure graphs. The team has shared specific methods of using LLMs on graphs, such as using LLMs as aligners, encoders, or predictors. Every strategy has benefits and drawbacks, and the purpose of the released study is to contrast these various approaches.
The practical applications of these techniques have been emphasized by the team, demonstrating the benefits of using LLMs in graph-related activities. The team has shared information on benchmark datasets and open-source scripts to help in applying and assessing these methods. The results highlighted the need for more investigation and creativity by outlining possible future study topics in this quickly developing field.
The team has summarized their primary contributions as follows.
- The team has made a contribution by methodically classifying the situations in which language models are used in graphs. These scenarios are organized into three categories: text-rich, text-paired, and pure graphs. This taxonomy provides a framework for comprehending the various settings.
- Language models have been carefully analyzed using graph approaches. The evaluation has summarised representative models for various graph contexts, making it the most thorough.
- A large number of materials have been curated pertaining to language models on graphs, including real-world applications, open-source codebases, and benchmark datasets.
- Six possible directions have been suggested for further research in the field of language models on graphs, delving into the fundamental ideas.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.