Meet Mixtral 8x7b: The Revolutionary Language Model from Mistral that Surpasses GPT-3.5 in Open-Access AI
The large language models domain has taken a remarkable step forward with the arrival of Mixtral 8x7b. Mistral AI developed this new model with impressive capabilities and a unique architecture that sets it apart. It has replaced feed-forward layers with a sparse Mixture of Expert (MoE) layer, a transformative approach in transformer models.
Mixtral 8x7b has eight expert models within a single framework. This model is a Mixture of Experts (MoE), allowing Mixtral to achieve exceptional performance.
The Mixture of Experts can enable models to be pretrained with significantly less computational power. This means the model or dataset size can be significantly increased without increasing the compute budget.
A router network is incorporated into the MoE layer, which chooses which experts efficiently process which tokens. Despite having four times as many parameters as a 12B parameter-dense model, Mixtral’s model can decode rapidly because two experts are selected for each timestep.
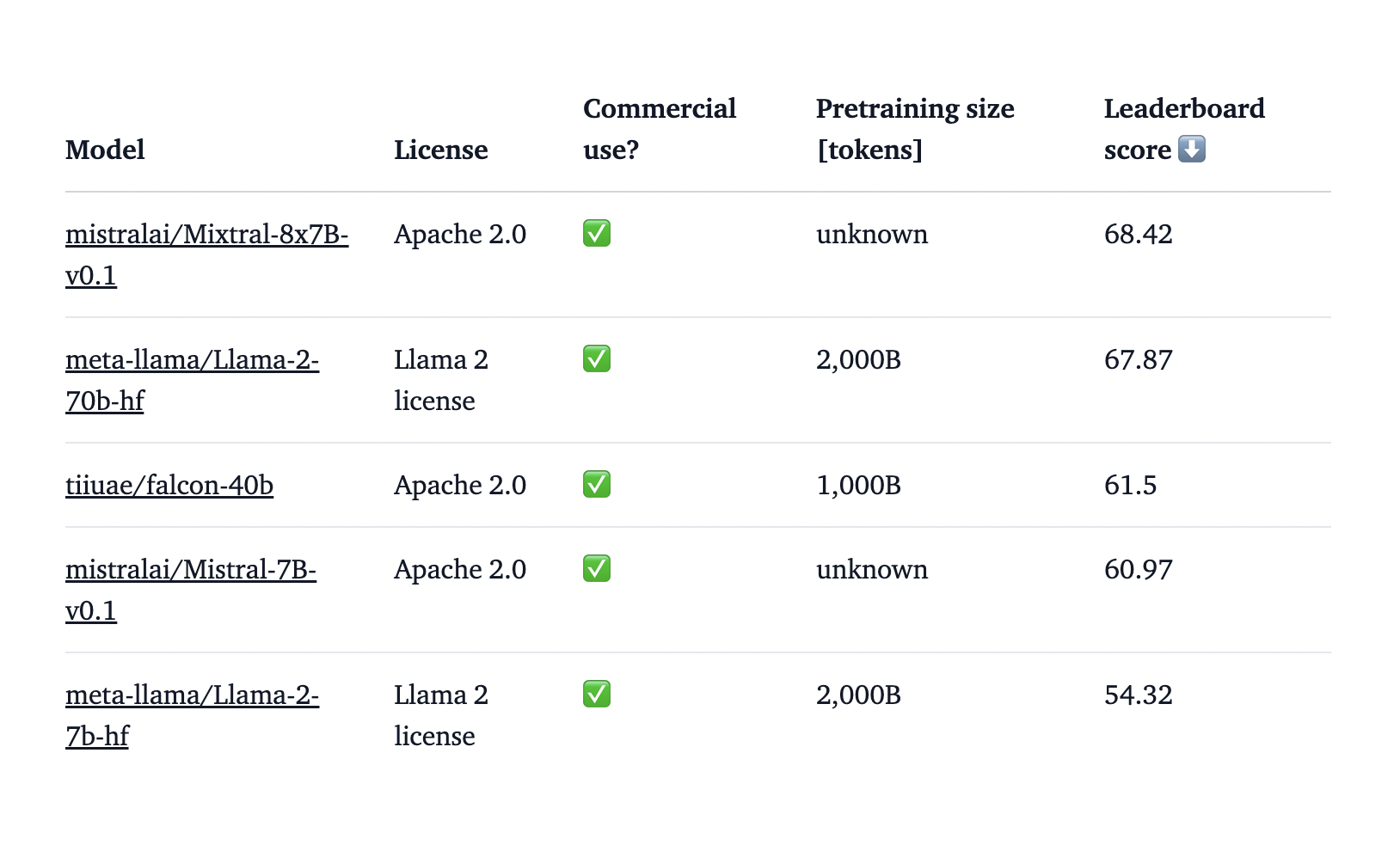
Mixtral 8x7b has a context length capacity of 32,000 tokens, outperforming the Llama 2 70B and demonstrating comparable or superior results to GPT3.5 across diverse benchmarks. The researchers said that the model is versatile for various applications. It can be multilingual and demonstrates its fluency in English, French, German, Spanish, and Italian. Its coding ability is also remarkable; scoring 40.2% on HumanEval tests cemented its position as a comprehensive natural language processing tool.
Mixtral Instruct has shown its performance on industry standards such as MT-Bench and AlpacaEval. It performs more remarkably on MT-Bench than any other open-access model and matches GPT-3.5 in performance. Despite having seven billion parameters, the model functions like an ensemble of eight. While it may not reach the scale of 56 billion parameters, the total parameter count stands at approximately 45 billion. Also, Mixtral Instruct excels in the instruct and chat model domain, asserting its dominance.
The base model of Mixtral Instruct does not have a specific prompt format that aligns with other base models. This flexibility permits users to smoothly extend an input sequence with a plausible continuation or utilize it for zero-shot/few-shot inference.
But, complete information regarding the pretraining dataset’s dimensions, composition, and preprocessing methods still needs to be located. Similarly, it is still unknown which fine-tuning datasets and associated hyperparameters are used for the Mixtral instruct model’s DPO (Domain-Provided Objectives) and SFT (Some Fine-Tuning).
In summary, Mixtral 8x7b has changed the game in language models by combining performance, adaptability, and creativity. When the AI community continues to investigate and evaluate Mistral’s architecture, researchers are eager to see the implications and applications of this state-of-the-art language model. The MoE’s 8x7B capabilities may create new opportunities for scientific research and development, education, healthcare, and science.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.