Microsoft AI Releases LLMLingua: A Unique Quick Compression Technique that Compresses Prompts for Accelerated Inference of Large Language Models (LLMs)
Large Language Models (LLMs), due to their strong generalization and reasoning powers, have significantly uplifted the Artificial Intelligence (AI) community. These models have shown to be remarkably capable and have showcased the capabilities of Natural Language Processing (NLP), Natural Language Generation (NLG), Computer Vision, etc. However, newer developments, including in-context learning (ICL) and chain-of-thought (CoT) prompting, have resulted in the deployment of longer prompts, sometimes even more than tens of thousands of tokens. This presents problems for model inference in terms of cost-effectiveness and computational efficiency.
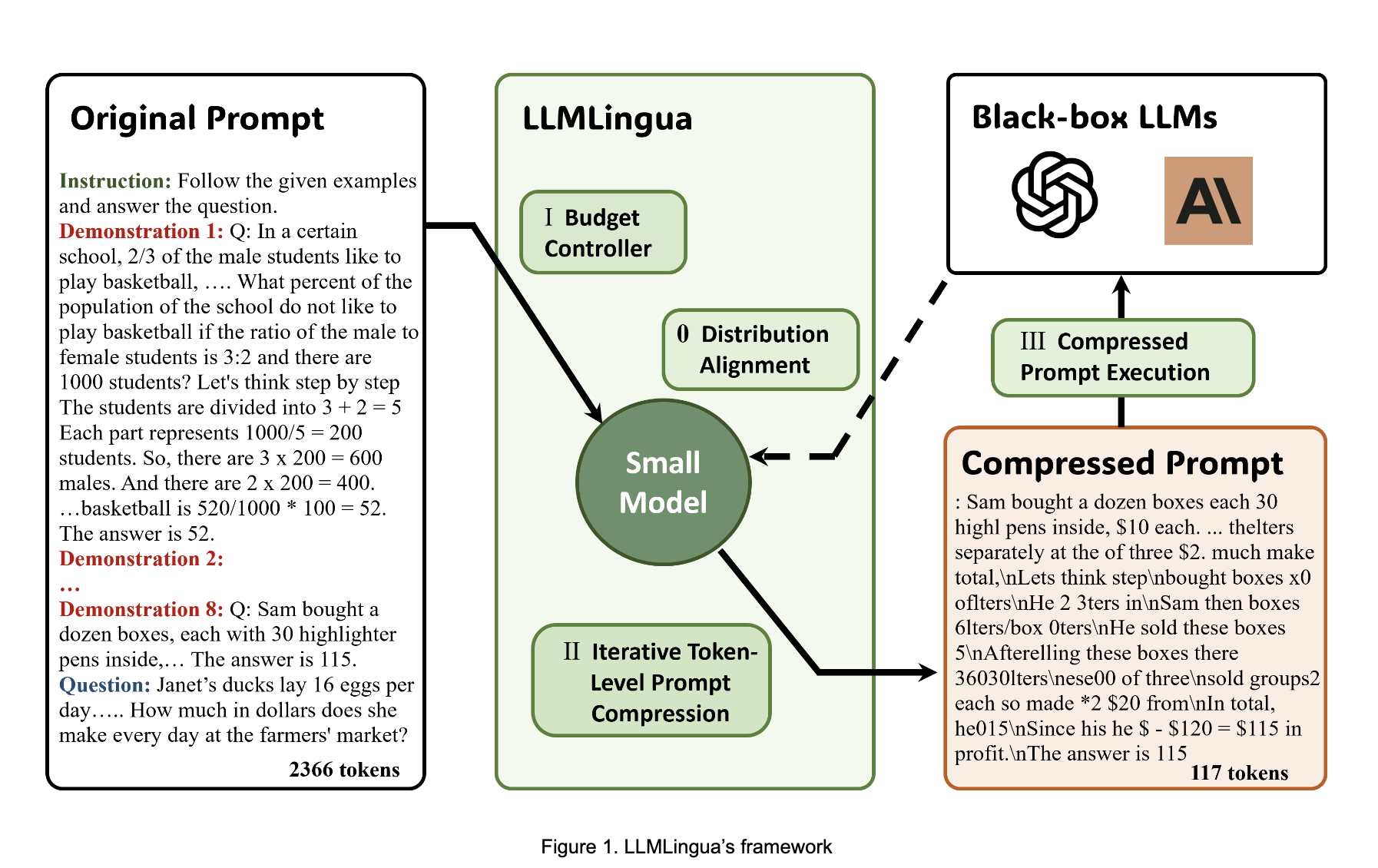
To overcome these challenges, a team of researchers from Microsoft Corporation has introduced LLMLingua, a unique coarse-to-fine quick compression technique. LLMLingua has been developed with the primary objective of minimizing expenses related to processing lengthy prompts and expediting model inference. To do this, LLMLingua uses a few essential strategies, which are as follows.
- Budget Controller: A dynamic budget controller has been created to govern how compression ratios are distributed among the various parts of the original prompts. This makes sure that the prompts’ semantic integrity is preserved even at large compression ratios.
- Token-level Iterative Compression Algorithm: An algorithm for token-level iterative compression has been integrated into LLMLingua. This technique enables more sophisticated compression by capturing the interdependence between compressed elements while maintaining crucial information about the prompt.
- Instruction Tuning-Based Approach: The team has suggested an instruction tuning-based approach to deal with the problem of distribution misalignment amongst language models. Aligning the language model distribution improves compatibility between the small language model utilized for rapid compression and the intended LLM.
The team has conducted the analysis and the experiments using four datasets from different circumstances to validate the usefulness of LLMLingua. The datasets are GSM8K and BBH for reasoning, ShareGPT for conversation, and Arxiv-March23 for summarization. The results have shown that the suggested approach achieves state-of-the-art performance in each of these circumstances. The results even demonstrated that LLMLingua permits significant compression of up to 20 times while sacrificing very little in terms of performance.
The small language model used in the experiments was LLaMA-7B, and the closed LLM was GPT-3.5-Turbo-0301. LLMLingua outperformed previous compression techniques by retaining reasoning, summarising, and discourse skills even at a maximum compression ratio of 20x, which portrays resilience, economy, efficacy, and recoverability.
The efficacy of LLMLingua has been observed across a range of closed LLMs and small language models. LLMLingua demonstrated good performance results, roughly matching larger models when utilizing GPT-2-small. It has also shown to be successful with strong LLMs, outperforming expected quick outcomes.
The recoverability of LLMLingua is one noteworthy aspect as GPT-4 effectively retrieved important reasoning information from the complete nine-step CoT prompting when it was used to restore compressed prompts, keeping the original prompts’ meaning and resemblance. This function guarantees recoverability and retains crucial information even after translation, adding to LLMLingua’s overall impressiveness.
In conclusion, LLMLingua has provided a comprehensive solution to the difficulties presented by long prompts in LLM applications. The method demonstrates excellent performance and offers a useful way to improve the effectiveness and affordability of LLM-based applications.
Check out the Paper, Github, and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.