This Paper Proposes RWKV: A New AI Approach that Combines the Efficient Parallelizable Training of Transformers with the Efficient Inference of Recurrent Neural Networks
Advancements in deep learning have influenced a wide variety of scientific and industrial applications in artificial intelligence. Natural language processing, conversational AI, time series analysis, and indirect sequential formats (such as pictures and graphs) are common examples of the complicated sequential data processing jobs involved in these. Recurrent Neural Networks (RNNs) and Transformers are the most common methods; each has advantages and disadvantages. RNNs have a lower memory requirement, especially when dealing with lengthy sequences. However, they can’t scale because of issues like the vanishing gradient problem and training-related non-parallelizability in the time dimension.
As an effective substitute, transformers can handle short- and long-term dependencies and enable parallelized training. In natural language processing, models like GPT-3, ChatGPT LLaMA, and Chinchilla demonstrate the power of Transformers. With its quadratic complexity, the self-attention mechanism is computationally and memory-expensive, making it unsuitable for tasks with limited resources and lengthy sequences.
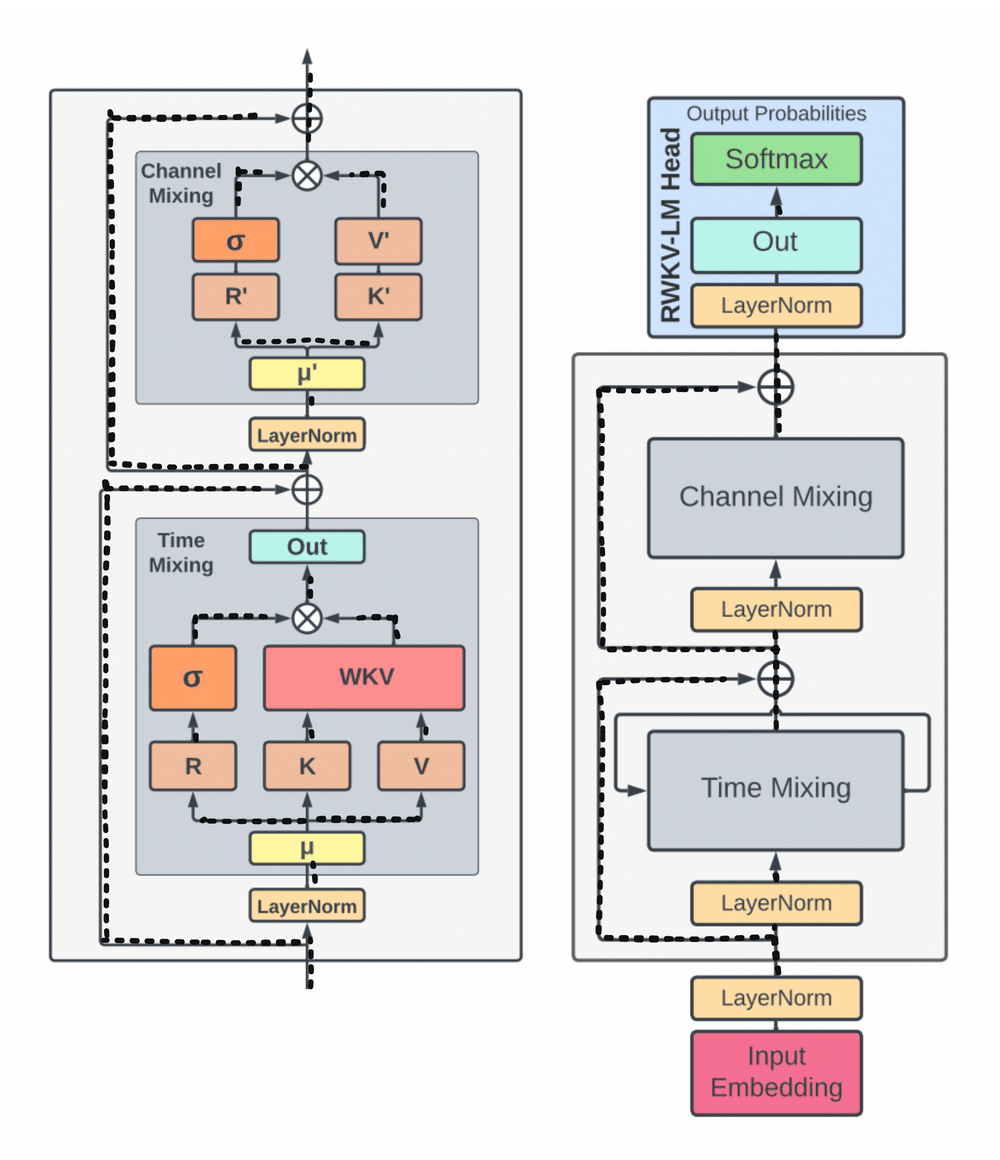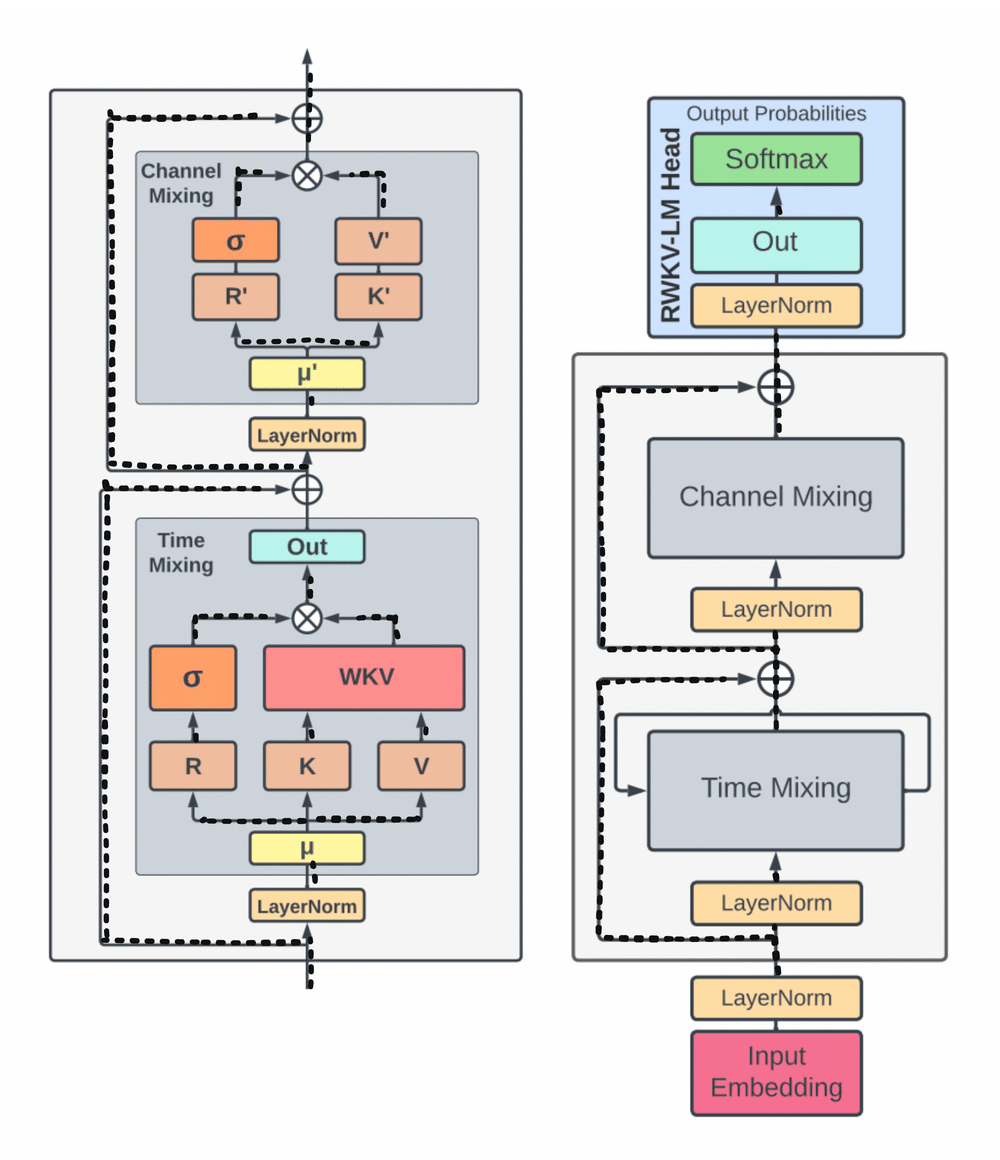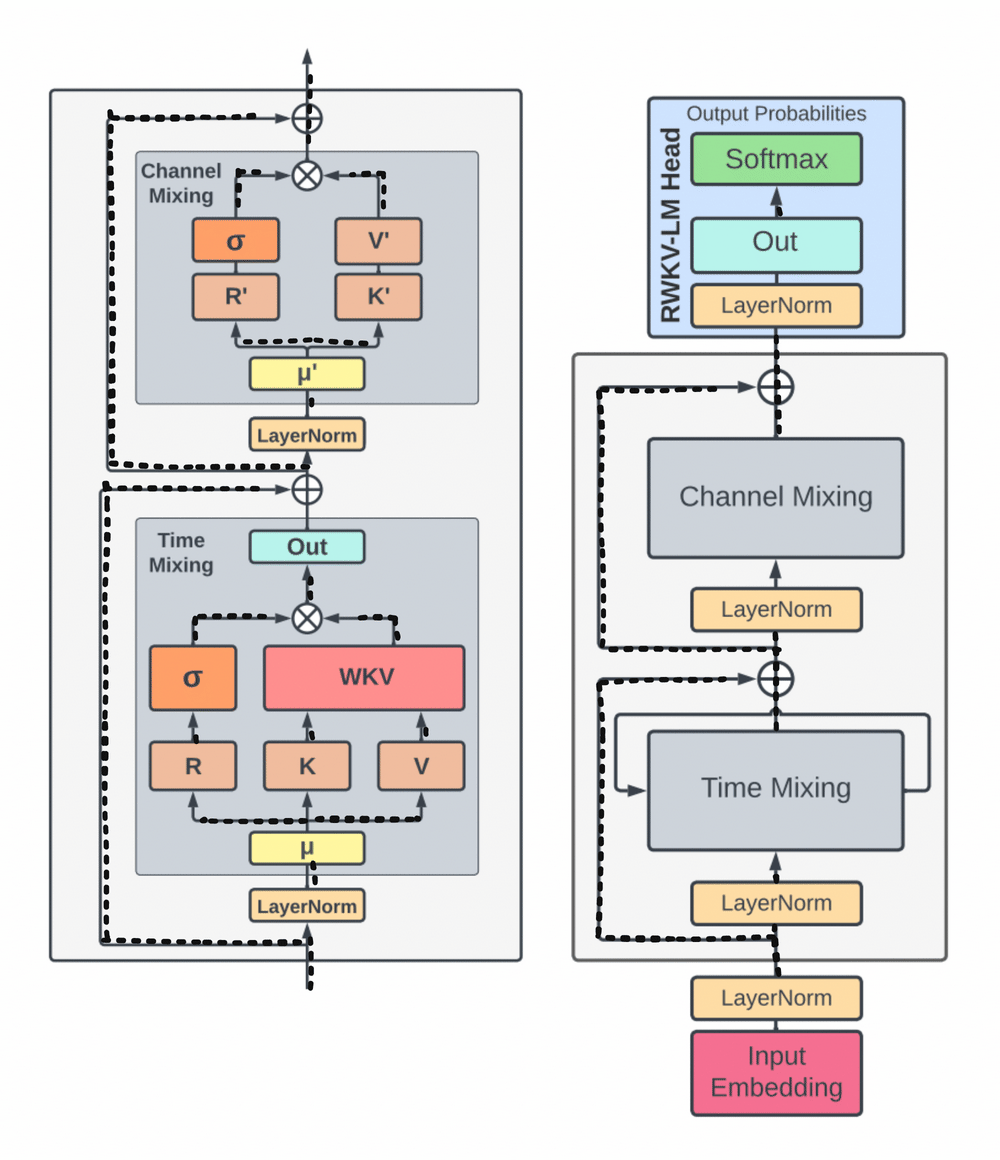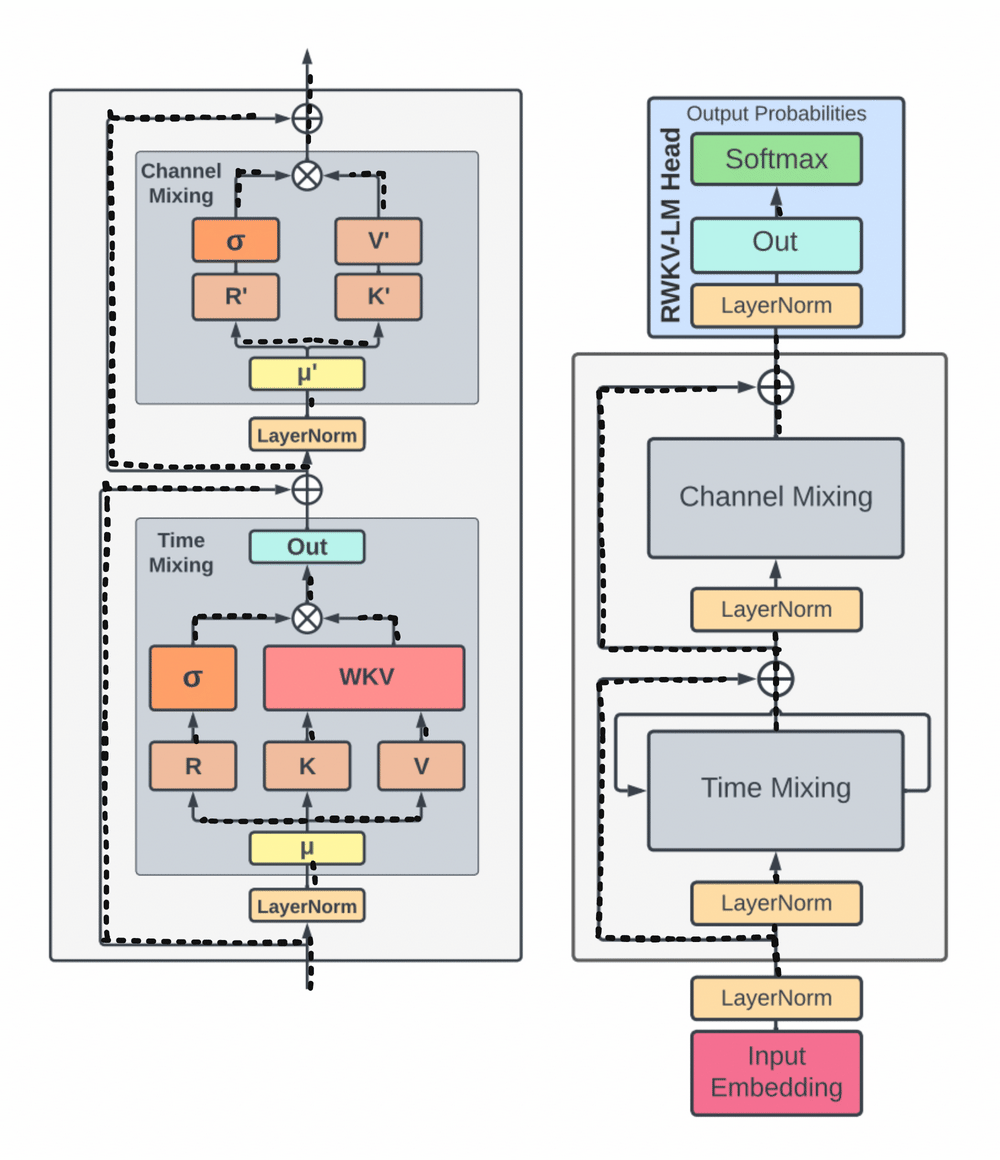
A group of researchers addressed these issues by introducing the Acceptance Weighted Key Value (RWKV) model, which combines the best features of RNNs and Transformers while avoiding their major shortcomings. While preserving the expressive qualities of the Transformer, like parallelized training and robust scalability, RWKV eliminates memory bottleneck and quadratic scaling that are common with Transformers. It does this with efficient linear scaling.
The study has been conducted by Generative AI Commons, Eleuther AI, U. of Barcelona, Charm Therapeutics, Ohio State U., U. of C., Santa Barbara, Zendesk, Booz Allen Hamilton, Tsinghua University, Peking University, Storyteller.io, Crisis, New York U., National U. of Singapore, Wroclaw U. of Science and Technology, Databaker Technology, Purdue U., Criteo AI Lab, Epita, Nextremer, Yale U., RuoxinTech, U. of Oslo, U. of Science and Technology of China, Kuaishou Technology, U. of British Columbia, U. of C., Santa Cruz, U. of Electronic Science and Technology of China.
Replacing the inefficient dot-product token interaction with the more efficient channel-directed attention, RWKV reworks the attention mechanism using a variant of linear attention. The computational and memory complexity is lowest in this approach, which does not use approximation.
By reworking recurrence and sequential inductive biases to enable efficient training parallelization and efficient inference, by replacing the quadratic QK attention with a scalar formulation at linear cost, and by improving training dynamics using custom initializations, RWKV can address the limitations of current architectures while capturing locality and long-range dependencies.
By comparing the suggested architecture to SoTA, the researchers find that it performs similarly while being more cost-effective across a range of natural language processing (NLP) workloads. Additional interpretability, scale, and expressivity tests highlight the model’s strengths and reveal behavioral similarities between RWKV and other LLMs. For efficient and scalable structures to model complicated relationships in sequential data, RWKV provides a new path. Despite numerous Transformers alternatives making similar claims, this is the first to use pretrained models with tens of billions of parameters to support such claims.
The team highlights some of the limitations of their work. Before anything else, RWKV’s linear attention leads to huge efficiency improvements, but it might also hinder the model’s ability to remember fine details over long periods. This is because, unlike ordinary Transformers, which maintain all information through quadratic attention, this one only uses one vector representation throughout several time steps.
The work also has the drawback of placing more emphasis on rapid engineering than conventional Transformer models. Specifically, RWKV’s linear attention mechanism restricts the amount of prompt-related data that may be carried to the subsequent model iteration. So, it’s likely that well-designed cues are much more important for the model to do well on tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.