This AI Research from Cohere AI Introduces the Mixture of Vectors (MoV) and Mixture of LoRA (MoLORA) to Mitigate the Challenges Associated with Scaling Instruction-Tuned LLMs at Scale
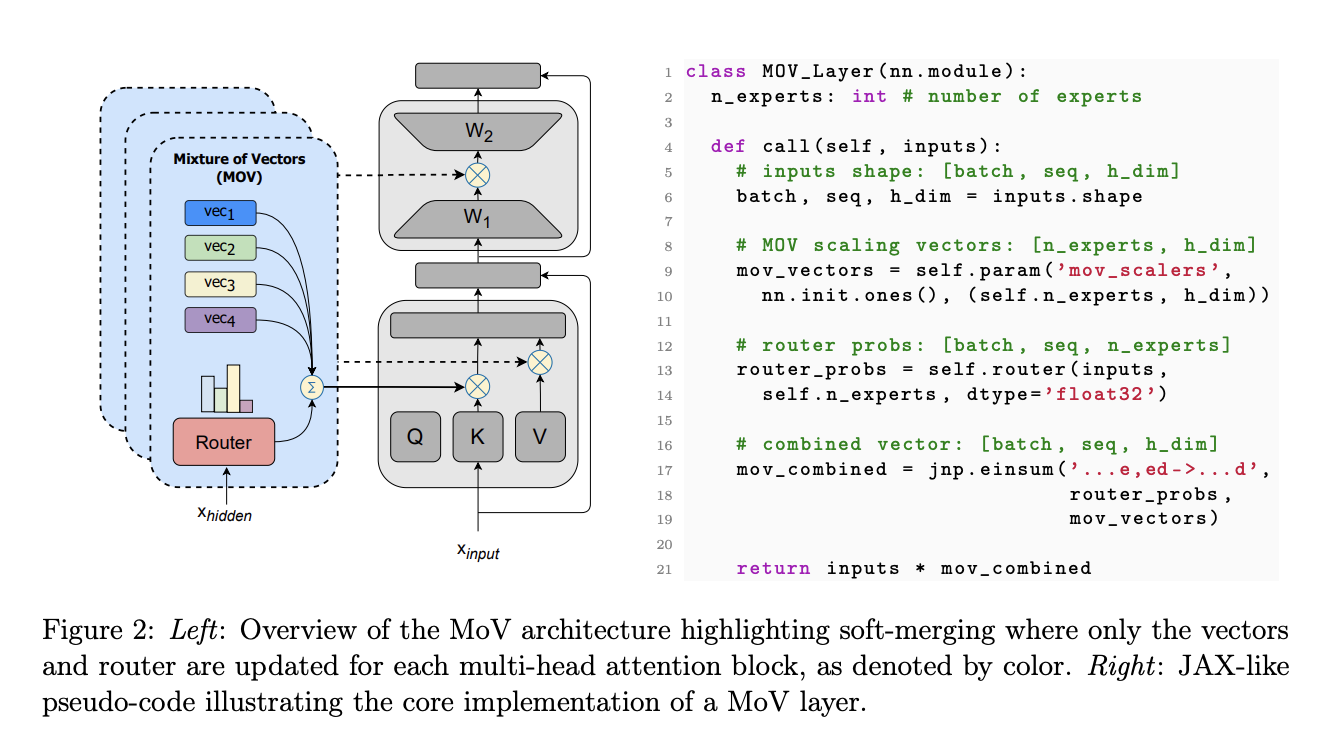
With the growing advancements in the field of Artificial Intelligence (AI), researchers are constantly coming up with new transformations and innovations. One such pioneering development is in the domain of Mixture of Experts (MoE) architecture, a well-known neural framework known for its capacity to maximize overall performance at a constant computing cost.
However, when AI models get bigger, traditional MoEs have trouble keeping track of every memory expert. To overcome this, in recent research, a team of Cohere researchers has studied about ways to expand the capabilities of MoE by presenting a very parameter-efficient version that solves these scalability problems. Lightweight experts have been combined with the MoE architecture in order to achieve this.
The suggested MoE architecture is a highly effective approach for parameter-efficient fine-tuning (PEFT) as it surpasses the drawbacks of conventional models. The team has shared that incorporating lightweight experts is the primary innovation enabling the model to surpass conventional PEFT techniques. Even when updating only the lightweight experts, which is less than 1% of a model with 11 billion parameters, the performance demonstrated was comparable to full fine-tuning.
The model’s capacity to generalize to tasks that haven’t been seen before, highlighting its independence from prior task knowledge, is one amazing feature of the research. This suggests that the proposed MoE architecture is not limited to particular domains and can successfully adjust to new tasks.
The results have demonstrated the adaptability of the combination of skilled architects. The suggested MoE variant has shown great performance in spite of strict parameter limits, which emphasizes how flexible and effective MoEs are, especially in difficult situations with constrained resources.
The team has summarized their primary contributions as follows.
- The research presents a unique design incorporating lightweight and modular experts to improve the Mixture of Experts (MoEs). This makes it possible to fine-tune dense models with low efficiency of less than 1% parameter updates.
- The suggested techniques often beat conventional parameter-efficient techniques in fine-tuning instructions, exhibiting better results on untested tasks. Notable improvements have been achieved by the Mixture of (IA)³ Vectors (MoV), which outperforms the standard (IA)³ at 3B and 11B model sizes by up to 14.57% and 8.39%, respectively. This superiority holds true for a variety of scales, expert variations, model types, and trainable parameter budgets.
- The study has shown that, with only a small percentage of the model parameters updated, the suggested MoV architecture can perform comparably to complete fine-tuning at large scales. Results from 8 previously unpublished tasks have shown competitive performance with far lower computational costs, just 0.32% and 0.86% of the parameters in the 3B and 11B models, respectively.
- In-depth ablation studies have been carried out to systematically assess the effectiveness of several MoE architectures and Parameter-Efficient Fine-Tuning (PEFT) techniques, which highlight how sensitive MoE is to hyperparameter optimization and cover a wide range of model sizes, adapter kinds, expert counts, and routing strategies.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.